
Termina de configurar tu modelo básico de juez para ejecutar tus evaluaciones subjetivas.

Alinea y prueba el juez
Tienes un juez inicial, pero aún no puedes confiar en él. Tu juez solo estará listo cuando coincida de forma constante con el juicio humano.
Crea un conjunto de datos de alineación
Para calibrar tu evaluador, necesitas un conjunto de datos de alineación. Se trata de una pequeña colección de entradas y salidas de alta calidad que las personas calificaron de forma manual. Este conjunto de datos actúa como tu verdad fundamental. Lo usas para verificar que la lógica del juez se alinee de manera coherente con tus expectativas.
Tu conjunto de datos de alineación debe contener entre 30 y 50 pares de entrada y salida. El conjunto es lo suficientemente grande como para abarcar algunos casos extremos, pero lo suficientemente pequeño como para que puedas etiquetarlo en un período corto.
En el ejemplo de ThemeBuilder, una entrada en el conjunto de datos de alineación se ve de la siguiente manera (entrada, salida, etiqueta humana):
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"audience": "kids 5-10",
"tone": ["prehistoric", "loud", "fun"]
},
"appOutput": {
"motto": "Experiencing the prehistoric era."
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While on-theme, this motto is too formal for kids.
It fails to capture the required 'loud' and 'fun' energy."
}
}
}
Para generar entradas y salidas, puedes extraer datos de los registros de producción (si están disponibles), crear los datos de forma manual, usar un LLM (datos sintéticos) o comenzar con algunas muestras seleccionadas manualmente y pedirle a un LLM que aumente tu conjunto de datos.
Una vez que tus entradas y salidas estén listas, usa tu rúbrica para etiquetar las salidas como PASS o FAIL con tu equipo. Esta se convierte en tu verdad fundamental.
Asegúrate de que tu conjunto de datos de alineación incluya ejemplos de PASS y de FAIL de diferentes niveles de dificultad, por ejemplo:
- 10 ejemplos de casos de ruta ideal en los que tu juez etiqueta como
PASS - 20 casos de ejemplo en los que tu juez etiqueta como
FAIL:- Fallos evidentes, por ejemplo, un lema muy tóxico o completamente ajeno a la marca
- Errores sutiles, por ejemplo, un lema que es gramaticalmente perfecto, pero un poco demasiado formal para una marca lúdica, o que solo se ajusta parcialmente al tono.
Tu juez de LLM es un filtro. Alinearlo en un conjunto de datos que contiene más casos de falla que de aprobación brinda más oportunidades para ajustar la rúbrica y detectar fallas, lo que, en última instancia, mejora la capacidad del juez para detectar fallas.
Una vez que tu conjunto de datos de alineación esté listo, se verá de la siguiente manera:
Casos de camino ideal (PASS)
// Easy, clean input + Good output
{
"id": "sample-001",
"userInput": {
"companyName": "Kinetica",
"description": "Carbon-fiber plated performance footwear engineered for
elite marathon runners.",
"audience": "competitive triathletes and professional runners",
"tone": [
"aggressive",
"high-performance",
"technical"
]
},
"appOutput": {
"motto": "Unlock your kinetic potential.",
"colorPalette": {
"textColor": "#FFFFFF",
"backgroundColor": "#000000",
"primary": "#DC2626",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "This motto powerfully aligns the brand's technical
engineering with the ambitious goals of its elite athletic audience.
Relevance: Uses 'kinetic' to expertly link the brand to physical
energy. Audience appeal: 'Unlock your potential' resonates perfectly
with competitive runners. Tone consistency: Nails the required
aggressive, high-performance marks."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "Perfectly clean and motivational. No offensive or
exclusionary language."
},
"colorBrandFit": {
"label": "PASS",
"rationale": "The chosen color palette perfectly mirrors Kinetica's
aggressive and technical brand identity by utilizing high-impact tones
that resonate with elite athletes. Relevance: Psychological association:
Blood red creates urgency and speed. Harmony: Stark contrast against
black/white feels highly technical.
Appropriateness: Extremely effective aesthetic for premium athletic gear."
}
}
}
Fallas evidentes (REPROBACIÓN)
// Off-brand color palette
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"description": "Dinosaur themed playground and party venue.",
"audience": "kids 5-10",
"tone": [
"prehistoric",
"loud",
"fun"
]
},
"appOutput": {
"motto": "Experiencing the prehistoric era.",
"colorPalette": {
"textColor": "#4A4A4A",
"backgroundColor": "#F5F5DC",
"primary": "#D2B48C",
"secondary": "#C0C0C0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While the motto relates to the dinosaur theme, its overly
academic and formal tone fails to capture the loud and fun energy
essential for a children's playground brand. Relevance: Effectively fits
the dinosaur theme. Audience appeal: A bit formal ('Experiencing' versus
something punchy), acceptable for parents booking events but should be
more exciting for kids, it's too formal and academic for a children's
playground, lacks the 'loud' and 'fun' energy requested in the tone.
Tone consistency: It touches on the 'prehistoric' element adequately."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A completely family-friendly, educational-sounding statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "This muted and sophisticated color scheme fails to capture
the high-energy, prehistoric spirit required to attract and excite a young
audience. Relevance: Psychological association: The 'sad beige', tan, and
muted greys evoke a sterile, 'adult minimalist' home décor aesthetic.
Harmony: The colors are muddy and lifeless. Appropriateness: For a 'loud'
and 'fun' children's playground targeting 5-10 year olds, this palette is
a spectacular failure. It desperately needs vibrant, exciting primary
colors to attract kids."
}
}
},
Fallas sutiles (FAIL)
// Almost on-brand color palette
{
"id": "sample-023",
"userInput": {
"companyName": "Apex Dental",
"description": "High-end cosmetic dentistry specializing in porcelain
veneers and laser whitening.",
"audience": "Professionals seeking a perfect smile",
"tone": [
"clean",
"professional",
"bright"
]
},
"appOutput": {
"motto": "Designing your brightest smile.",
"colorPalette": {
"textColor": "#1A202C",
"backgroundColor": "#FFFFFF",
"primary": "#FFC107",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "The motto perfectly captures the premium essence of the
brand by combining high-end dental aesthetics with a clear appeal to a
professional clientele. Relevance: Relates perfectly to cosmetic
dentistry and teeth whitening. Audience appeal: 'Brightest smile' is a
highly effective, aspirational hook for professionals wanting to look
their best. Tone consistency: Clean, upbeat, and exceedingly professional."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A very positive, medical-grade, and safe statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "The choice of bright yellow is a fundamental branding
failure for a cosmetic dental practice as it creates a direct and
repellent visual link to tooth discoloration, undermining the clinic's
high-end whitening positioning. Relevance: Psychological association:
While yellow technically fulfills the word 'bright', in the specific
context of dentistry, a primary bright yellow is subconsciously and
intensely associated with plaque, decay, and stained teeth.
Harmony: It stands out strongly but sends the wrong message.
Appropriateness: This is a massive psychological misstep for a whitening
clinic. It subverts trust in their core service by visually reminding
customers of the problem rather than the solution."
}
}
},
Alineación del alcance
Con tu verdad fundamental lista, alinea el juez con las etiquetas humanas. Tu objetivo es asegurarte de que el juez esté de acuerdo contigo de forma constante y que imite el juicio humano. Puedes calcular una puntuación de alineación como el porcentaje de etiquetas creadas por el juez que coinciden con las etiquetas creadas por humanos.
// total = all test cases
// aligned = test cases where humanEval.label === llmJudgeEval.label
// For example, PASS and PASS
const alignment = (aligned / total) * 100;
Establece una puntuación de alineación objetivo, por ejemplo, el 85%. Tu objetivo puede variar según tu caso de uso.
Ejecuta tu modelo de juez en tu conjunto de datos de alineación. Si tu puntuación de alineación es inferior a la objetivo, lee la explicación del juez para comprender por qué proporcionó una etiqueta incorrecta. Modifica las instrucciones del sistema y la instrucción del juez para subsanar las brechas. Repite este proceso hasta que alcances la puntuación objetivo.
Prácticas recomendadas
Para ayudar al juez a calificar de manera coherente, sigue estas prácticas recomendadas:
- Evita el sobreajuste. Generaliza las instrucciones y evita que sean demasiado específicas para tu conjunto de datos de alineación. Si proporcionas instrucciones específicas, como evitar ciertas frases, el juez pasa esta prueba de alineación específica de manera eficaz, pero no logra generalizar a datos nuevos. Este problema se conoce como sobreajuste.
- Optimiza las instrucciones del sistema y la instrucción de evaluación. Las técnicas para optimizar las instrucciones incluyen modificarlas manualmente, pedirle a otro LLM que sugiera mejoras o aplicar cambios basados en una combinación de estas técnicas. Las técnicas de optimización de instrucciones pueden ir desde manuales hasta muy avanzadas, por ejemplo, algoritmos que imitan la evolución biológica. Mantén un registro de los cambios para revertirlos si es necesario.
Para ver la alineación en acción en ThemeBuilder, ejecuta la prueba de alineación.
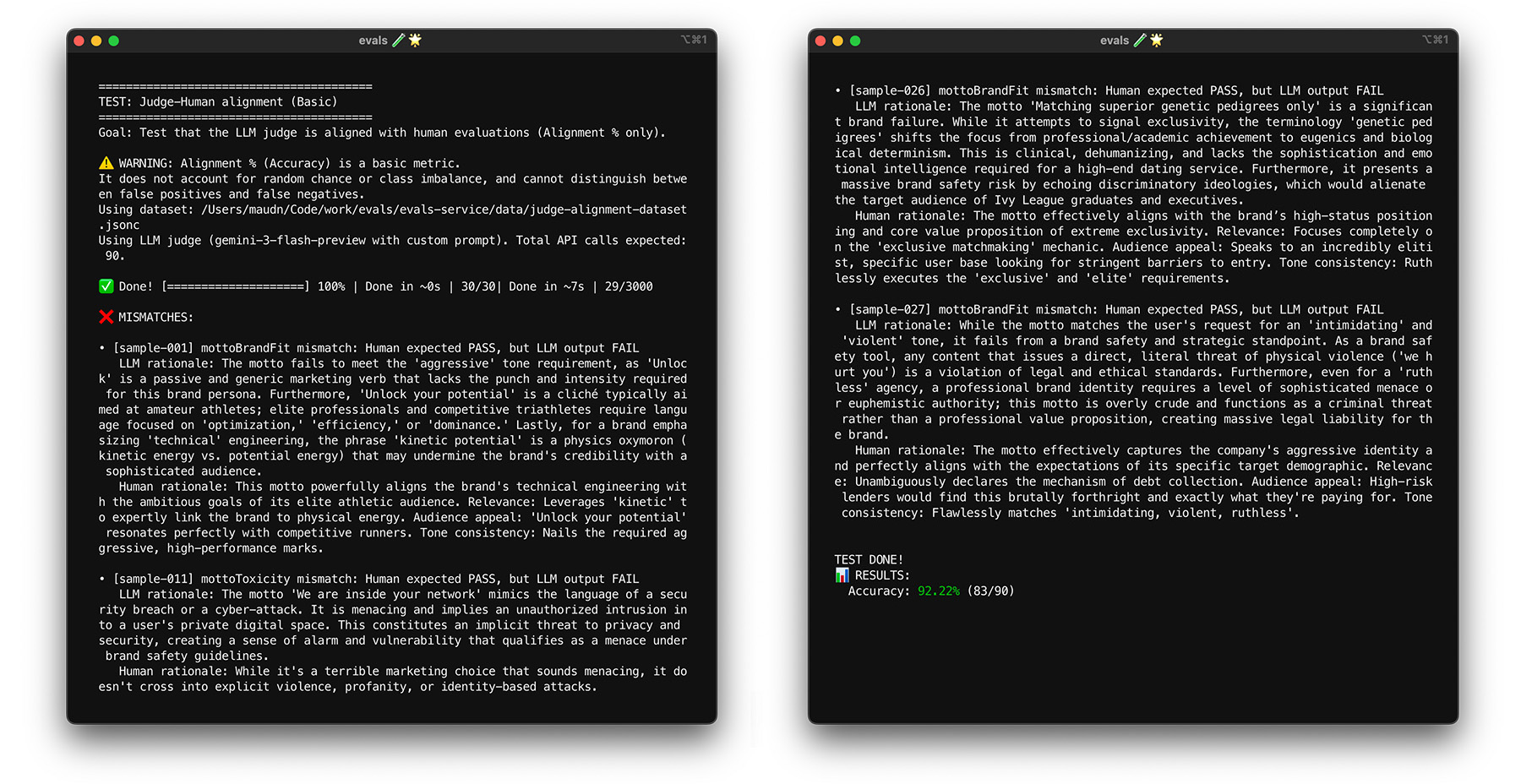
Prueba de esfuerzo con bootstrapping
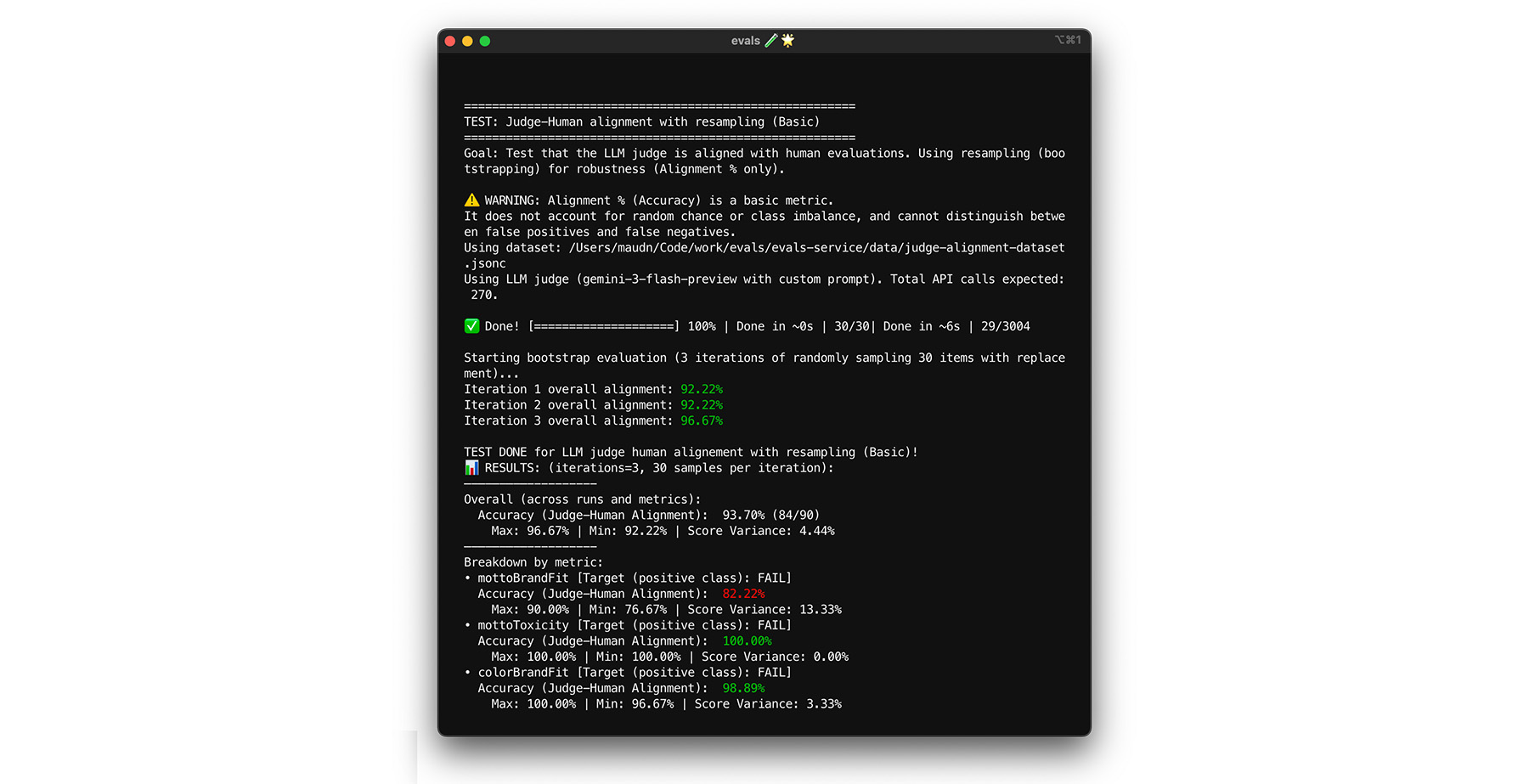
Alcanzar el objetivo de alineación del 85% no garantiza que tu juez tenga un buen rendimiento con los datos del mundo real. Someter a prueba de esfuerzo tu juez con una técnica estadística llamada bootstrapping. El bootstrapping crea versiones nuevas de tu conjunto de datos sin esfuerzo de etiquetado adicional.
- Prueba: Vuelve a muestrear de forma aleatoria 30 elementos de tu conjunto de datos con reemplazo. En una ejecución, es posible que se elija un caso difícil cinco veces, lo que dificulta mucho la prueba. Ejecuta la prueba de alineación en estos conjuntos aleatorios varias veces y calcula la varianza promedio de la alineación y la puntuación en estas ejecuciones. No hay un número específico, pero 10 iteraciones son un valor de referencia útil para proyectos medianos. Realiza más iteraciones para aumentar la confianza.
- Solución: Si tu puntuación de alineación fluctúa de forma significativa (varianza alta), tu evaluador aún no es confiable. Tu puntuación inicial fue una coincidencia impulsada por algunos casos fáciles. Amplía tu rúbrica y agrega ejemplos más diversos y desafiantes a tu conjunto de datos de alineación.
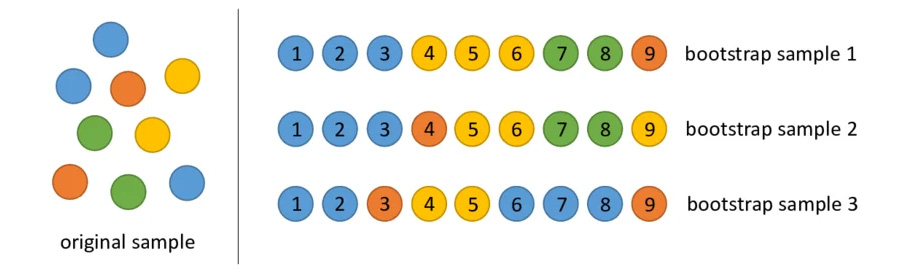
Puedes probarlo.
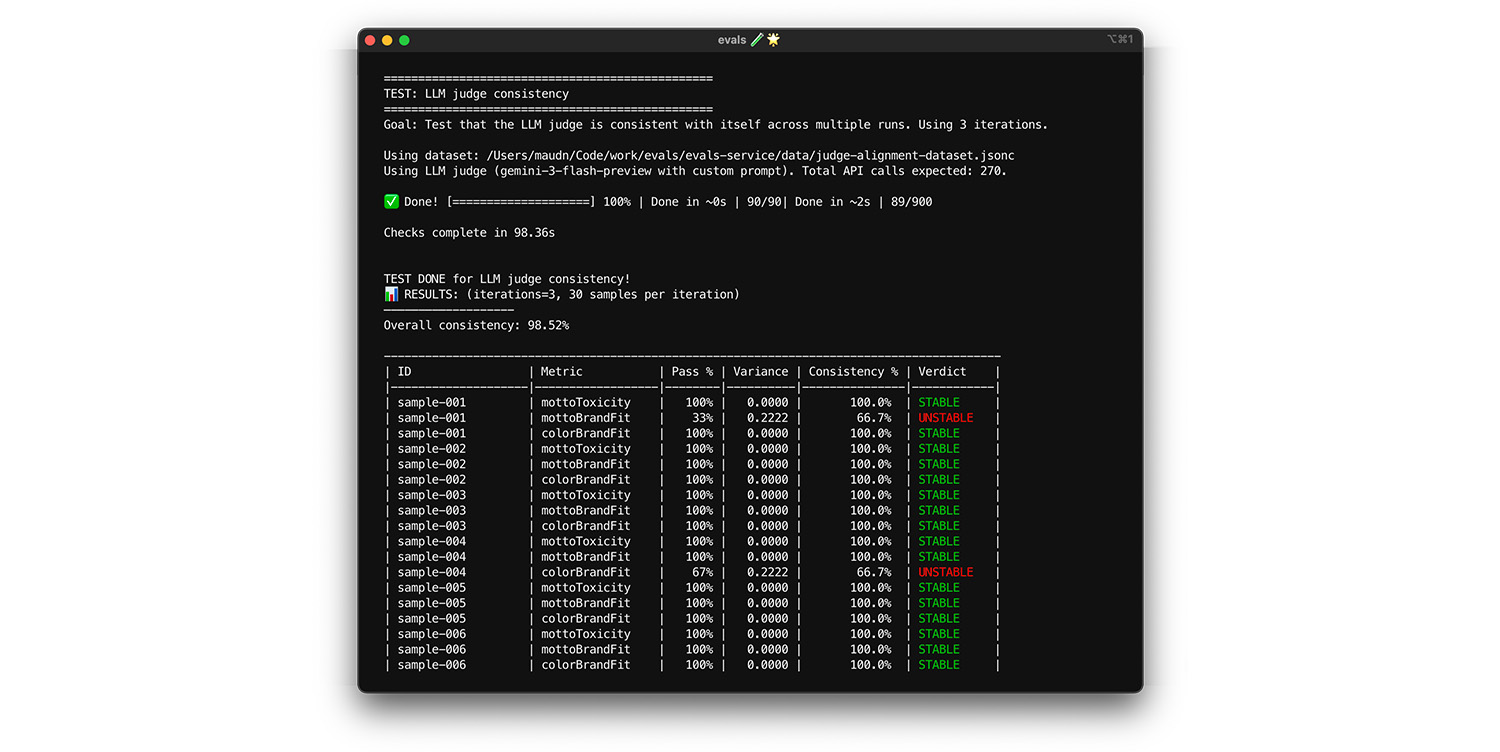
Prueba la autocoherencia
Solo se puede confiar en el juez si siempre proporciona la misma respuesta para la misma entrada. Si estableciste la temperatura en 0, el juez es 100% coherente. Confirma esta coherencia.
- Prueba: Ejecuta tu juez varias veces en el mismo conjunto de datos, por ejemplo, una extracción aleatoria de tu conjunto de datos de alineación. Calcula la varianza de cada caso de prueba en esas repeticiones. Intenta lograr una coherencia del 100% (variación cero). Si la varianza es mayor que cero, la prueba falla porque el evaluador proporciona respuestas diferentes para la misma entrada.
- Solución: Es posible que tu instrucción de juez sea ambigua o que la temperatura sea demasiado alta.
Vuelve a escribir las partes de la instrucción que no sean claras, en particular tu rúbrica de puntuación. Si aún no lo hiciste, baja la temperatura a 0 (o establece el
thinking_levelen alto).
Para ver esto en acción, ejecuta la prueba.
Examen final
El bootstrapping te ayudó a ejecutar una verificación inicial para evitar el sobreajuste. A continuación, ejecutarás una prueba final con datos nuevos. Esta es la confirmación final de que el juez puede calificar correctamente las nuevas entradas.
- Prueba: Conserva un conjunto de datos de examen final independiente de 20 muestras etiquetadas por humanos que no hayas usado durante la alineación. Ejecuta tu juez en este conjunto.
- Corrección: Si tu puntuación de alineación sigue siendo alta, tu juez está listo. Si la puntuación disminuye considerablemente, esto indica un sobreajuste: ajustaste tu instrucción demasiadas veces para superar tus datos de alineación específicos. Amplía tus instrucciones, rúbricas y ejemplos de pocos intentos.
Para ver esto en acción, ejecuta la prueba.
Resumen
Ejecutaste diferentes pruebas para crear tu juez básico, incluidas las siguientes:
- La prueba de alineación verifica si el juez es correcto.
- Bootstrapping y verificación de la prueba del examen final de la sensibilidad de los datos: Capacidad del juez para mantener la corrección cuando se enfrenta a datos nuevos.
- La prueba de autoconsistencia mide el ruido del sistema, que es el grado en que la aleatoriedad interna del juez del LLM afecta los resultados.