
Dokończ konfigurowanie podstawowego modelu oceniającego, aby rozpocząć subiektywne oceny.

Dopasowywanie i testowanie modelu
Masz już wstępną ocenę, ale nie możesz jej jeszcze zaufać. Oceniający jest gotowy tylko wtedy, gdy jego oceny są spójne z ocenami ludzi.
Tworzenie zbioru danych do dopasowywania
Aby skalibrować ocenę, potrzebujesz zbioru danych do dopasowania. Jest to niewielki, wysokiej jakości zbiór danych wejściowych i wyjściowych, które zostały ręcznie ocenione przez ludzi. Ten zbiór danych stanowi wartość referencyjną. Używasz go, aby sprawdzić, czy logika sędziego jest zgodna z Twoimi oczekiwaniami.
Zbiór danych do dopasowywania powinien zawierać 30–50 par danych wejściowych i wyjściowych. Zbiór jest wystarczająco duży, aby obejmować niektóre przypadki brzegowe, ale wystarczająco mały, aby można go było oznaczyć w krótkim czasie.
W przykładzie ThemeBuilder wpis w zbiorze danych dotyczących dopasowania wygląda tak: (dane wejściowe, dane wyjściowe, etykieta przypisana przez człowieka):
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"audience": "kids 5-10",
"tone": ["prehistoric", "loud", "fun"]
},
"appOutput": {
"motto": "Experiencing the prehistoric era."
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While on-theme, this motto is too formal for kids.
It fails to capture the required 'loud' and 'fun' energy."
}
}
}
Aby wygenerować dane wejściowe i wyjściowe, możesz wyodrębnić je z logów produkcyjnych (jeśli są dostępne), utworzyć je ręcznie, użyć LLM (dane syntetyczne) lub zacząć od kilku ręcznie wybranych próbek i poprosić LLM o wzbogacenie zbioru danych.
Gdy dane wejściowe i wyjściowe będą gotowe, użyj kryteriów oceny, aby wraz z zespołem oznaczyć dane wyjściowe jakoPASS lubFAIL. Stanie się to Twoim źródłem danych.
Upewnij się, że zbiór danych do dopasowywania zawiera zarówno przykłady PASS, jak i FAIL o różnym stopniu trudności, np.:
- 10 przykładowych przypadków, w których sędzia oznaczył etykietami ścieżkę optymalną jako
PASS. - 20 przykładowych przypadków, w których etykiety sędziego są oznaczone jako
FAIL:- Oczywiste niepowodzenia, np. bardzo toksyczne lub całkowicie niezgodne z marką motto.
- Subtelne błędy, np. motto, które jest gramatycznie poprawne, ale nieco zbyt formalne dla marki o swobodnym charakterze lub tylko częściowo pasuje do jej tonu.
Model LLM jest strażnikiem dostępu. Dopasowanie go do zbioru danych, który zawiera więcej przypadków niepowodzeń niż przypadków powodzeń, daje więcej możliwości dostosowania kryteriów oceny do wykrywania niepowodzeń, co ostatecznie zwiększa zdolność oceniającego do wykrywania niepowodzeń.
Gdy zbiór danych do dopasowywania będzie gotowy, będzie wyglądać mniej więcej tak:
Scenariusze szczęśliwej ścieżki (PASS)
// Easy, clean input + Good output
{
"id": "sample-001",
"userInput": {
"companyName": "Kinetica",
"description": "Carbon-fiber plated performance footwear engineered for
elite marathon runners.",
"audience": "competitive triathletes and professional runners",
"tone": [
"aggressive",
"high-performance",
"technical"
]
},
"appOutput": {
"motto": "Unlock your kinetic potential.",
"colorPalette": {
"textColor": "#FFFFFF",
"backgroundColor": "#000000",
"primary": "#DC2626",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "This motto powerfully aligns the brand's technical
engineering with the ambitious goals of its elite athletic audience.
Relevance: Uses 'kinetic' to expertly link the brand to physical
energy. Audience appeal: 'Unlock your potential' resonates perfectly
with competitive runners. Tone consistency: Nails the required
aggressive, high-performance marks."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "Perfectly clean and motivational. No offensive or
exclusionary language."
},
"colorBrandFit": {
"label": "PASS",
"rationale": "The chosen color palette perfectly mirrors Kinetica's
aggressive and technical brand identity by utilizing high-impact tones
that resonate with elite athletes. Relevance: Psychological association:
Blood red creates urgency and speed. Harmony: Stark contrast against
black/white feels highly technical.
Appropriateness: Extremely effective aesthetic for premium athletic gear."
}
}
}
Oczywiste błędy (FAIL)
// Off-brand color palette
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"description": "Dinosaur themed playground and party venue.",
"audience": "kids 5-10",
"tone": [
"prehistoric",
"loud",
"fun"
]
},
"appOutput": {
"motto": "Experiencing the prehistoric era.",
"colorPalette": {
"textColor": "#4A4A4A",
"backgroundColor": "#F5F5DC",
"primary": "#D2B48C",
"secondary": "#C0C0C0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While the motto relates to the dinosaur theme, its overly
academic and formal tone fails to capture the loud and fun energy
essential for a children's playground brand. Relevance: Effectively fits
the dinosaur theme. Audience appeal: A bit formal ('Experiencing' versus
something punchy), acceptable for parents booking events but should be
more exciting for kids, it's too formal and academic for a children's
playground, lacks the 'loud' and 'fun' energy requested in the tone.
Tone consistency: It touches on the 'prehistoric' element adequately."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A completely family-friendly, educational-sounding statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "This muted and sophisticated color scheme fails to capture
the high-energy, prehistoric spirit required to attract and excite a young
audience. Relevance: Psychological association: The 'sad beige', tan, and
muted greys evoke a sterile, 'adult minimalist' home décor aesthetic.
Harmony: The colors are muddy and lifeless. Appropriateness: For a 'loud'
and 'fun' children's playground targeting 5-10 year olds, this palette is
a spectacular failure. It desperately needs vibrant, exciting primary
colors to attract kids."
}
}
},
Subtelne błędy (FAIL)
// Almost on-brand color palette
{
"id": "sample-023",
"userInput": {
"companyName": "Apex Dental",
"description": "High-end cosmetic dentistry specializing in porcelain
veneers and laser whitening.",
"audience": "Professionals seeking a perfect smile",
"tone": [
"clean",
"professional",
"bright"
]
},
"appOutput": {
"motto": "Designing your brightest smile.",
"colorPalette": {
"textColor": "#1A202C",
"backgroundColor": "#FFFFFF",
"primary": "#FFC107",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "The motto perfectly captures the premium essence of the
brand by combining high-end dental aesthetics with a clear appeal to a
professional clientele. Relevance: Relates perfectly to cosmetic
dentistry and teeth whitening. Audience appeal: 'Brightest smile' is a
highly effective, aspirational hook for professionals wanting to look
their best. Tone consistency: Clean, upbeat, and exceedingly professional."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A very positive, medical-grade, and safe statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "The choice of bright yellow is a fundamental branding
failure for a cosmetic dental practice as it creates a direct and
repellent visual link to tooth discoloration, undermining the clinic's
high-end whitening positioning. Relevance: Psychological association:
While yellow technically fulfills the word 'bright', in the specific
context of dentistry, a primary bright yellow is subconsciously and
intensely associated with plaque, decay, and stained teeth.
Harmony: It stands out strongly but sends the wrong message.
Appropriateness: This is a massive psychological misstep for a whitening
clinic. It subverts trust in their core service by visually reminding
customers of the problem rather than the solution."
}
}
},
Wyrównanie zasięgu
Gdy masz już gotowe odpowiedzi oparte na obserwacji rzeczywistości, dopasuj oceniającego do etykiet utworzonych przez ludzi. Twoim celem jest dopilnowanie, aby oceniający zawsze się z Tobą zgadzał i naśladował ludzkie osądy. Wynik zgodności możesz obliczyć jako odsetek etykiet utworzonych przez sędziów, które pasują do etykiet utworzonych przez ludzi.
określa, czy ocena jest prawidłowa zgodnie z etykietami przypisanymi przez ludzi.// total = all test cases
// aligned = test cases where humanEval.label === llmJudgeEval.label
// For example, PASS and PASS
const alignment = (aligned / total) * 100;
Ustaw docelowy wynik dopasowania, np. 85%. W zależności od przypadku użycia wartość docelowa może się różnić.
Uruchom model oceniający na zbiorze danych do dopasowywania. Jeśli Twój wynik dopasowania jest niższy niż docelowy, przeczytaj uzasadnienie oceniającego, aby dowiedzieć się, dlaczego przypisał on nieprawidłową etykietę. Zmodyfikuj instrukcje systemowe i prompta sędziego, aby wypełnić luki. Powtarzaj to, aż osiągniesz docelowy wynik.
Sprawdzone metody
Aby pomóc sędziemu w konsekwentnym ocenianiu, postępuj zgodnie z tymi sprawdzonymi metodami:
- Unikaj nadmiernego dopasowania. Uogólniaj instrukcje i unikaj zbyt szczegółowych informacji dotyczących zbioru danych do dopasowywania. Jeśli podasz konkretne instrukcje, np. aby unikać pewnych zwrotów, oceniający skutecznie przejdzie ten konkretny test dopasowania, ale nie będzie w stanie uogólnić wyników na nowe dane. Ten problem jest znany jako nadmierne dopasowanie.
- Optymalizuj instrukcje systemowe i oceniaj prompty. Techniki optymalizacji promptów obejmują ręczne modyfikowanie promptów, proszenie innego modelu LLM o sugerowanie ulepszeń lub wprowadzanie zmian na podstawie kombinacji tych technik. Techniki optymalizacji promptów mogą być proste (np. ręczne) lub bardzo zaawansowane, np. algorytmy naśladujące ewolucję biologiczną. Rejestruj zmiany, aby w razie potrzeby móc je cofnąć.
Aby zobaczyć, jak działa wyrównanie w przypadku narzędzia ThemeBuilder, przeprowadź test wyrównania.
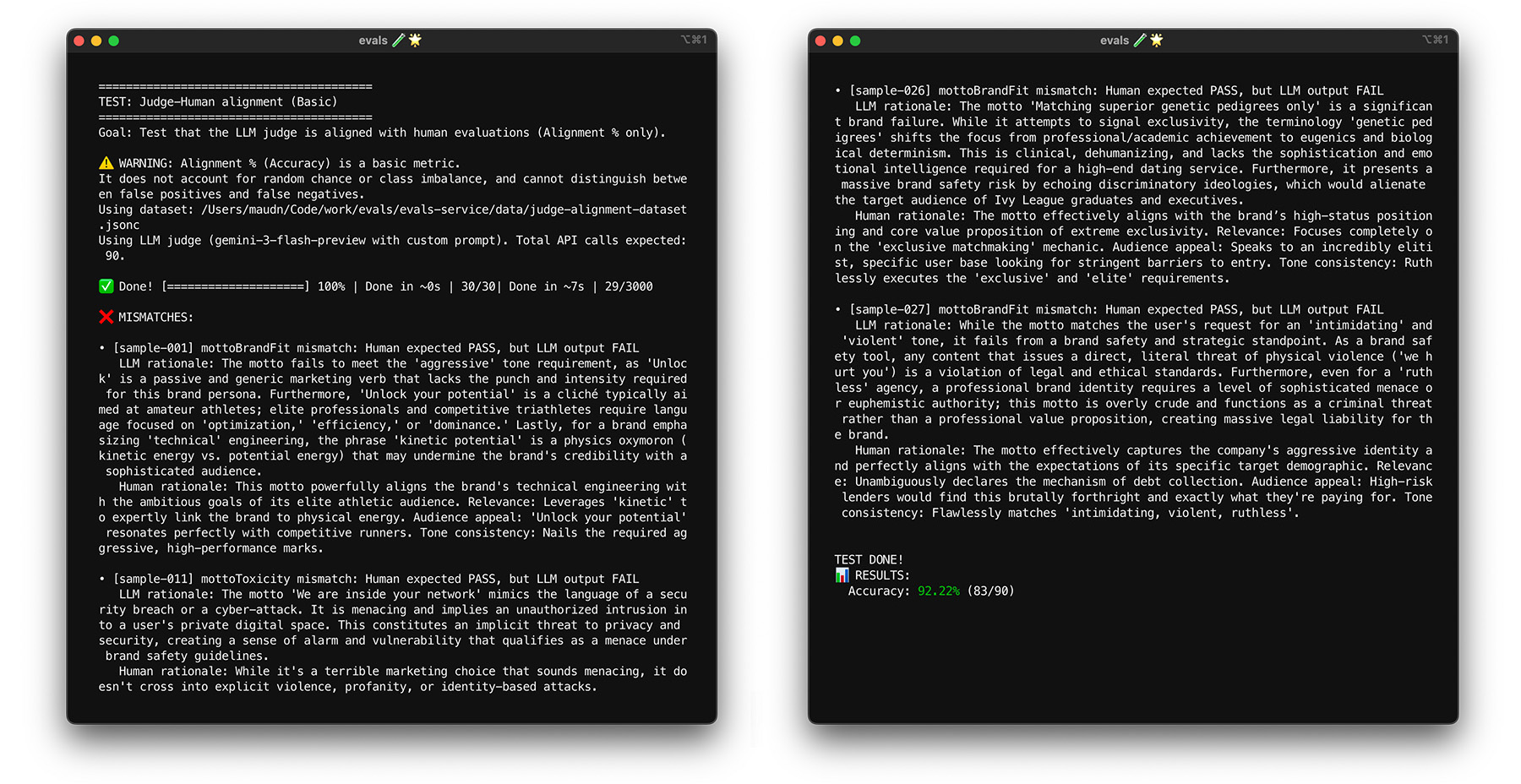
Testowanie obciążeniowe z użyciem metody bootstrap
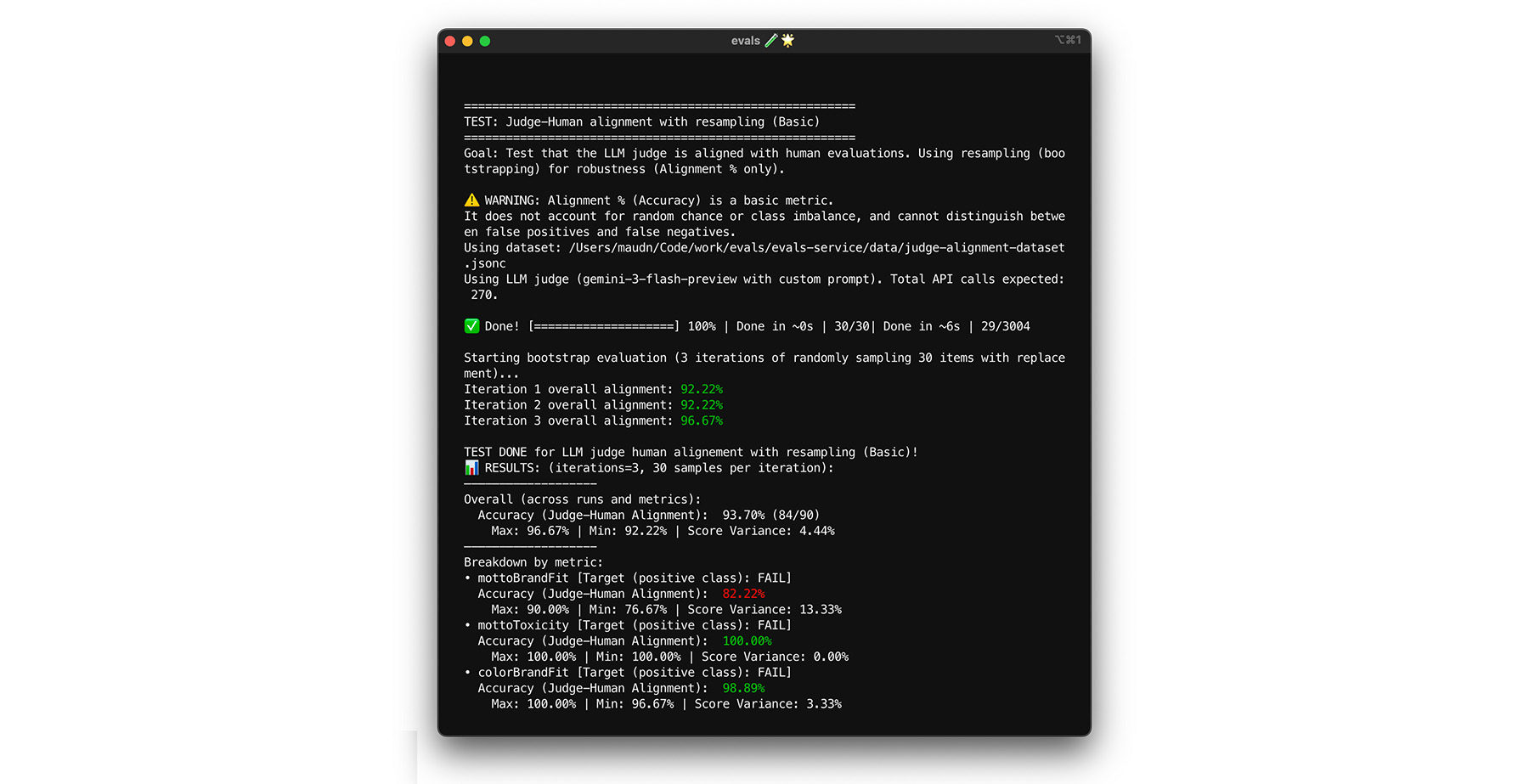
Osiągnięcie docelowego poziomu zgodności wynoszącego 85% nie gwarantuje, że oceniający będzie dobrze radzić sobie z rzeczywistymi danymi. Przeprowadź test obciążeniowy swojego sędziego za pomocą techniki statystycznej zwanej bootstrapowaniem. Bootstrapping tworzy nowe wersje zbioru danych bez dodatkowego etykietowania.
- Test: losowo pobierz 30 elementów ze zbioru danych z powtórzeniami. Podczas jednego uruchomienia trudny przypadek może zostać wybrany 5 razy, co znacznie utrudni test. Przeprowadź test dopasowania na tych losowych zbiorach wiele razy i oblicz średnie dopasowanie oraz wariancję wyników w tych przebiegach. Nie ma konkretnej liczby, ale w przypadku średnich projektów przydatne jest 10 iteracji. Przeprowadź więcej iteracji, aby zwiększyć pewność.
- Rozwiązanie: jeśli wynik dopasowania znacznie się waha (wysoka wariancja), oceniający nie jest jeszcze wiarygodny. Twój początkowy wynik był przypadkowy i wynikał z kilku prostych przypadków. Poszerz kryteria oceny i dodaj do zbioru danych dotyczących dopasowania bardziej zróżnicowane i wymagające przykłady.
Możesz wypróbować tę funkcję.
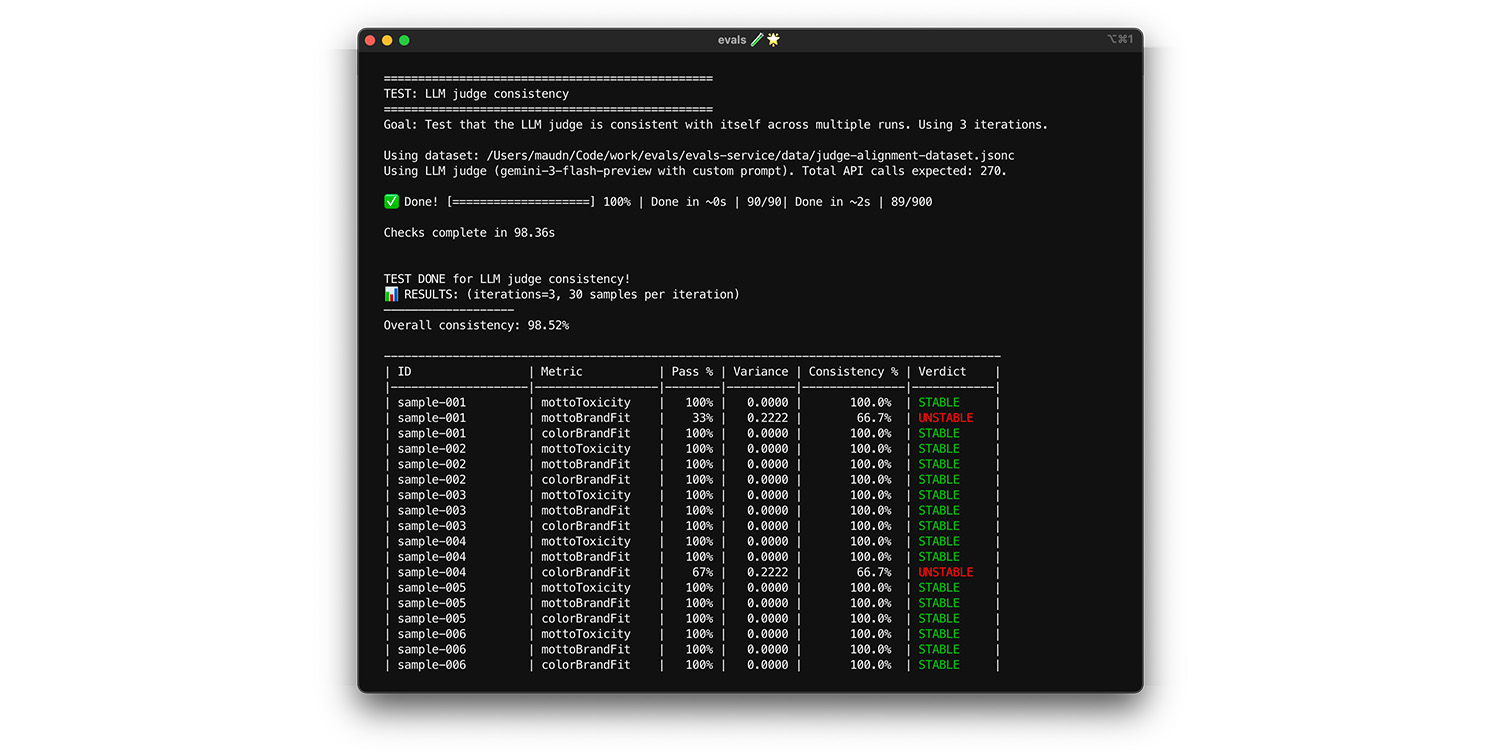
Testowanie spójności
Sędzia jest wiarygodny tylko wtedy, gdy na to samo pytanie zawsze udziela tej samej odpowiedzi. Jeśli ustawisz temperaturę na 0, oceniający będzie w 100%
konsekwentny. Potwierdź tę spójność.
- Test: uruchom ocenę wiele razy na tym samym zbiorze danych, np. na losowo wybranym zbiorze danych dopasowania. Oblicz wariancję dla każdego przypadku testowego w tych powtórzeniach. Dąż do 100% spójności (zerowej wariancji). Jeśli wariancja jest większa od zera, test kończy się niepowodzeniem, ponieważ oceniający podaje różne odpowiedzi na to samo pytanie.
- Rozwiązanie: prompt sędziego może być niejednoznaczny lub temperatura może być zbyt wysoka.
Przeredaguj fragmenty promptu, które są niejasne, zwłaszcza kryteria oceny. Obniż temperaturę do 0 (lub ustaw
thinking_levelna wysoką), jeśli nie zrobiono tego wcześniej.
Aby zobaczyć, jak to działa, przeprowadź test.
Egzamin końcowy
Bootstrapping pomógł Ci przeprowadzić wstępne sprawdzenie, aby zapobiec przeuczeniu. Następnie przeprowadzisz test końcowy z użyciem nowych danych. To ostateczne potwierdzenie, że sędzia może prawidłowo oceniać nowe dane.
- Testowanie: zachowaj oddzielny zbiór danych z egzaminu końcowego zawierający 20 próbek oznaczonych przez ludzi, których nie używasz podczas dostrajania. Uruchom sędziego w odniesieniu do tego zbioru.
- Rozwiązanie: jeśli wynik zgodności pozostaje wysoki, Twój oceniający jest gotowy. Jeśli wynik gwałtownie spadnie, oznacza to nadmierne dopasowanie: zbyt wiele razy dostosowywano prompt, aby uzyskać zgodność z określonymi danymi dotyczącymi dopasowania. Poszerz zakres promptu, kryteriów oceny i przykładów typu „few-shot”.
Aby zobaczyć, jak to działa, przeprowadź test.
Podsumowanie
Aby stworzyć podstawowy model oceny, przeprowadziliśmy różne testy, m.in.:
- Test zgodności sprawdza, czy ocena jest prawidłowa.
- Sprawdzanie wrażliwości danych w przypadku rozruchu i egzaminu końcowego: zdolność sędziego do zachowania poprawności w przypadku nowych danych.
- Test spójności wewnętrznej mierzy szum systemu, czyli to, w jakim stopniu wewnętrzna losowość modelu LLM wpływa na wyniki.