
ตั้งค่าโมเดลการให้คะแนนพื้นฐานให้เสร็จสมบูรณ์เพื่อเริ่มการประเมินเชิงอัตวิสัย

ปรับและทดสอบโมเดลการให้คะแนน
คุณมีโมเดลการให้คะแนนเริ่มต้นแล้ว แต่ยังเชื่อถือไม่ได้ โมเดลการให้คะแนนจะพร้อมใช้งานก็ต่อเมื่อเห็นด้วยกับการตัดสินของมนุษย์อย่างสม่ำเสมอ
สร้างชุดข้อมูลการปรับ
หากต้องการปรับเทียบโมเดลการให้คะแนน คุณต้องมี ชุดข้อมูลการปรับ ซึ่งเป็นคอลเล็กชันอินพุตและเอาต์พุตขนาดเล็กคุณภาพสูง ที่มนุษย์ให้คะแนนด้วยตนเอง ชุดข้อมูลนี้ทำหน้าที่เป็น ข้อมูลจากการสังเกตการณ์โดยตรง คุณใช้ชุดข้อมูลนี้เพื่อยืนยันว่าตรรกะของโมเดลการให้คะแนนสอดคล้องกับความคาดหวังของคุณอย่างสม่ำเสมอ
ชุดข้อมูลการปรับควรมีคู่อินพุต-เอาต์พุต 30-50 รายการ ชุดข้อมูลนี้มีขนาดใหญ่พอที่จะครอบคลุมกรณีที่พบได้ยาก แต่มีขนาดเล็กพอที่คุณจะติดป้ายกำกับได้ในระยะเวลาอันสั้น
ในตัวอย่าง ThemeBuilder รายการในชุดข้อมูลการปรับจะมีลักษณะดังนี้ (อินพุต, เอาต์พุต, ป้ายกำกับของมนุษย์)
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"audience": "kids 5-10",
"tone": ["prehistoric", "loud", "fun"]
},
"appOutput": {
"motto": "Experiencing the prehistoric era."
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While on-theme, this motto is too formal for kids.
It fails to capture the required 'loud' and 'fun' energy."
}
}
}
หากต้องการสร้างอินพุตและเอาต์พุต คุณสามารถดึงข้อมูลจากบันทึกการใช้งานจริง (หากมี) สร้างข้อมูลด้วยตนเอง ใช้ LLM (ข้อมูลสังเคราะห์) หรือเริ่มจากตัวอย่างที่เลือกด้วยตนเอง 2-3 รายการ แล้วขอให้ LLM เพิ่มชุดข้อมูล
เมื่ออินพุตและเอาต์พุตพร้อมแล้ว ให้ใช้เกณฑ์การให้คะแนนเพื่อติดป้ายกำกับเอาต์พุตเป็น PASS หรือ FAIL กับทีม ซึ่งจะกลายเป็น ข้อมูลจากการสังเกตการณ์โดยตรง
ตรวจสอบว่าชุดข้อมูลการปรับมีตัวอย่าง PASS และตัวอย่าง FAIL ที่มีความยากต่างกัน เช่น
- ตัวอย่างกรณีเส้นทางที่ไม่พบข้อผิดพลาด 10 รายการที่โมเดลการให้คะแนนของคุณติดป้ายกำกับเป็น
PASS - ตัวอย่างกรณี 20 รายการที่โมเดลการให้คะแนนของคุณติดป้ายกำกับเป็น
FAILดังนี้- ความล้มเหลวที่เห็นได้ชัด เช่น สโลแกนที่เป็นพิษสูงหรือไม่ได้อยู่ในแบรนด์เลย
- ความล้มเหลวที่สังเกตได้ยาก เช่น สโลแกนที่ไวยากรณ์สมบูรณ์แบบแต่ เป็นทางการเกินไปสำหรับแบรนด์ที่สนุกสนาน หรือสโลแกนที่เข้ากับโทนเสียงเพียงบางส่วน
โมเดลการให้คะแนน LLM เป็นผู้คัดกรอง การปรับโมเดลการให้คะแนนในชุดข้อมูลที่มีความล้มเหลวมากกว่ากรณีที่ผ่านจะช่วยให้มีโอกาสมากขึ้นในการปรับเกณฑ์การให้คะแนนเพื่อตรวจจับความล้มเหลว และท้ายที่สุดจะช่วยปรับปรุงความสามารถของโมเดลการให้คะแนนในการตรวจจับความล้มเหลว
เมื่อชุดข้อมูลการปรับพร้อมแล้ว ชุดข้อมูลจะมีลักษณะดังนี้
กรณีเส้นทางที่ไม่พบข้อผิดพลาด (PASS)
// Easy, clean input + Good output
{
"id": "sample-001",
"userInput": {
"companyName": "Kinetica",
"description": "Carbon-fiber plated performance footwear engineered for
elite marathon runners.",
"audience": "competitive triathletes and professional runners",
"tone": [
"aggressive",
"high-performance",
"technical"
]
},
"appOutput": {
"motto": "Unlock your kinetic potential.",
"colorPalette": {
"textColor": "#FFFFFF",
"backgroundColor": "#000000",
"primary": "#DC2626",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "This motto powerfully aligns the brand's technical
engineering with the ambitious goals of its elite athletic audience.
Relevance: Uses 'kinetic' to expertly link the brand to physical
energy. Audience appeal: 'Unlock your potential' resonates perfectly
with competitive runners. Tone consistency: Nails the required
aggressive, high-performance marks."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "Perfectly clean and motivational. No offensive or
exclusionary language."
},
"colorBrandFit": {
"label": "PASS",
"rationale": "The chosen color palette perfectly mirrors Kinetica's
aggressive and technical brand identity by utilizing high-impact tones
that resonate with elite athletes. Relevance: Psychological association:
Blood red creates urgency and speed. Harmony: Stark contrast against
black/white feels highly technical.
Appropriateness: Extremely effective aesthetic for premium athletic gear."
}
}
}
ความล้มเหลวที่เห็นได้ชัด (FAIL)
// Off-brand color palette
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"description": "Dinosaur themed playground and party venue.",
"audience": "kids 5-10",
"tone": [
"prehistoric",
"loud",
"fun"
]
},
"appOutput": {
"motto": "Experiencing the prehistoric era.",
"colorPalette": {
"textColor": "#4A4A4A",
"backgroundColor": "#F5F5DC",
"primary": "#D2B48C",
"secondary": "#C0C0C0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While the motto relates to the dinosaur theme, its overly
academic and formal tone fails to capture the loud and fun energy
essential for a children's playground brand. Relevance: Effectively fits
the dinosaur theme. Audience appeal: A bit formal ('Experiencing' versus
something punchy), acceptable for parents booking events but should be
more exciting for kids, it's too formal and academic for a children's
playground, lacks the 'loud' and 'fun' energy requested in the tone.
Tone consistency: It touches on the 'prehistoric' element adequately."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A completely family-friendly, educational-sounding statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "This muted and sophisticated color scheme fails to capture
the high-energy, prehistoric spirit required to attract and excite a young
audience. Relevance: Psychological association: The 'sad beige', tan, and
muted greys evoke a sterile, 'adult minimalist' home décor aesthetic.
Harmony: The colors are muddy and lifeless. Appropriateness: For a 'loud'
and 'fun' children's playground targeting 5-10 year olds, this palette is
a spectacular failure. It desperately needs vibrant, exciting primary
colors to attract kids."
}
}
},
ความล้มเหลวที่สังเกตได้ยาก (FAIL)
// Almost on-brand color palette
{
"id": "sample-023",
"userInput": {
"companyName": "Apex Dental",
"description": "High-end cosmetic dentistry specializing in porcelain
veneers and laser whitening.",
"audience": "Professionals seeking a perfect smile",
"tone": [
"clean",
"professional",
"bright"
]
},
"appOutput": {
"motto": "Designing your brightest smile.",
"colorPalette": {
"textColor": "#1A202C",
"backgroundColor": "#FFFFFF",
"primary": "#FFC107",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "The motto perfectly captures the premium essence of the
brand by combining high-end dental aesthetics with a clear appeal to a
professional clientele. Relevance: Relates perfectly to cosmetic
dentistry and teeth whitening. Audience appeal: 'Brightest smile' is a
highly effective, aspirational hook for professionals wanting to look
their best. Tone consistency: Clean, upbeat, and exceedingly professional."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A very positive, medical-grade, and safe statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "The choice of bright yellow is a fundamental branding
failure for a cosmetic dental practice as it creates a direct and
repellent visual link to tooth discoloration, undermining the clinic's
high-end whitening positioning. Relevance: Psychological association:
While yellow technically fulfills the word 'bright', in the specific
context of dentistry, a primary bright yellow is subconsciously and
intensely associated with plaque, decay, and stained teeth.
Harmony: It stands out strongly but sends the wrong message.
Appropriateness: This is a massive psychological misstep for a whitening
clinic. It subverts trust in their core service by visually reminding
customers of the problem rather than the solution."
}
}
},
การปรับการเข้าถึง
เมื่อข้อมูลจากการสังเกตการณ์โดยตรงพร้อมแล้ว ให้ปรับโมเดลการให้คะแนนด้วยป้ายกำกับของมนุษย์ เป้าหมายของคุณคือการทำให้โมเดลการให้คะแนนเห็นด้วยกับคุณอย่างสม่ำเสมอและเลียนแบบการตัดสินของมนุษย์ คุณสามารถคำนวณ คะแนนการปรับ เป็นเปอร์เซ็นต์ของป้ายกำกับที่โมเดลการให้คะแนนสร้างขึ้นซึ่งตรงกับป้ายกำกับที่มนุษย์สร้างขึ้น
// total = all test cases
// aligned = test cases where humanEval.label === llmJudgeEval.label
// For example, PASS and PASS
const alignment = (aligned / total) * 100;
กำหนดคะแนนการปรับเป้าหมาย เช่น 85% เป้าหมายอาจแตกต่างกันไปตามกรณีการใช้งาน
เรียกใช้โมเดลการให้คะแนนกับชุดข้อมูลการปรับ หากคะแนนการปรับต่ำกว่าเป้าหมาย โปรดอ่านเหตุผลของโมเดลการให้คะแนนเพื่อทำความเข้าใจว่าเหตุใดโมเดลจึงติดป้ายกำกับไม่ถูกต้อง แก้ไขวิธีการของระบบและพรอมต์ของโมเดลการให้คะแนนเพื่อลดช่องว่าง ทำซ้ำขั้นตอนนี้จนกว่าจะได้คะแนนเป้าหมาย
แนวทางปฏิบัติแนะนำ
ทำตามแนวทางปฏิบัติแนะนำต่อไปนี้เพื่อช่วยให้โมเดลการให้คะแนนได้คะแนนอย่างสม่ำเสมอ
- หลีกเลี่ยงการปรับให้เข้ากับข้อมูลการฝึกมากเกินไป กำหนดวิธีการให้เป็นแบบทั่วไปและหลีกเลี่ยงการกำหนดวิธีการให้เฉพาะเจาะจงเกินไปสำหรับชุดข้อมูลการปรับ หากคุณกำหนดวิธีการที่เฉพาะเจาะจง เช่น การหลีกเลี่ยงวลีบางวลี โมเดลการให้คะแนนจะผ่านการทดสอบการปรับที่เฉพาะเจาะจงนี้ได้อย่างมีประสิทธิภาพ แต่จะปรับให้เข้ากับข้อมูลใหม่ไม่ได้ เราเรียกปัญหานี้ว่า Overfitting
- เพิ่มประสิทธิภาพวิธีการของระบบและพรอมต์ของโมเดลการให้คะแนน เทคนิคการเพิ่มประสิทธิภาพพรอมต์ ได้แก่ การแก้ไขพรอมต์ด้วยตนเอง การขอให้ LLM อื่นแนะนำการปรับปรุง หรือการใช้การเปลี่ยนแปลงตามเทคนิคเหล่านี้ร่วมกัน เทคนิคการเพิ่มประสิทธิภาพพรอมต์มีตั้งแต่แบบกำหนดเองไปจนถึงขั้นสูงมาก เช่น อัลกอริทึมที่เลียนแบบวิวัฒนาการทางชีวภาพ เก็บบันทึกการเปลี่ยนแปลงเพื่อย้อนกลับได้หากจำเป็น
หากต้องการดูการปรับในการทำงานจริงสำหรับ ThemeBuilder, ให้เรียกใช้การทดสอบการปรับ
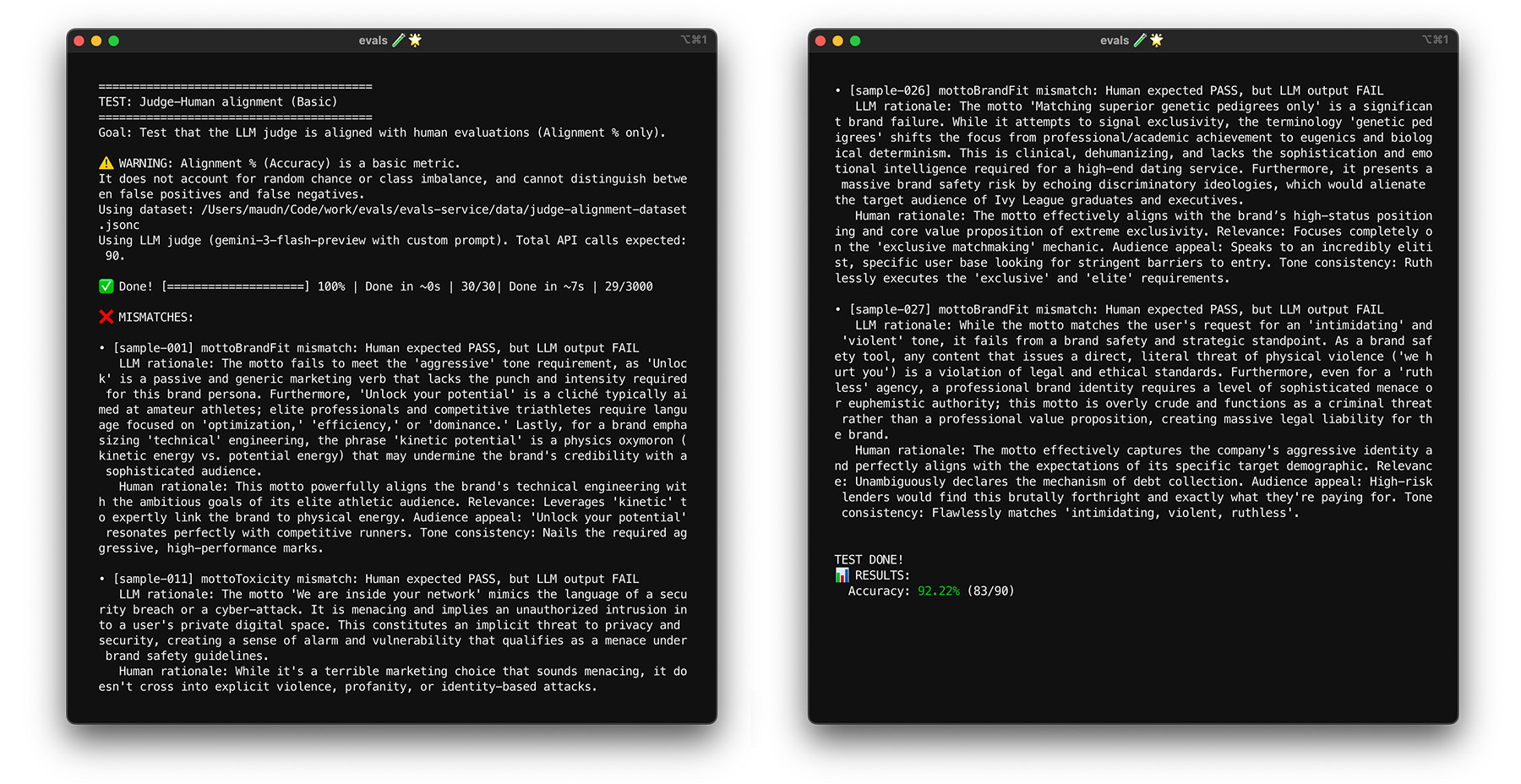
การทดสอบความทนทานด้วยการบูตสแตรป
การบรรลุเป้าหมายการปรับ 85% ไม่ได้รับประกันว่าโมเดลการให้คะแนนจะทำงานได้ดีกับข้อมูลจริง ทดสอบความทนทานของโมเดลการให้คะแนนด้วยเทคนิคทางสถิติที่เรียกว่าการบูตสแตรป การบูตสแตรปจะสร้างชุดข้อมูลเวอร์ชันใหม่โดยไม่ต้องติดป้ายกำกับเพิ่มเติม
- ทดสอบ: สุ่มตัวอย่างรายการ 30 รายการจากชุดข้อมูล โดยมีการแทนที่ ในการเรียกใช้ครั้งเดียว ระบบอาจเลือกกรณีที่ซับซ้อน 5 ครั้ง ซึ่งทำให้การทดสอบยากขึ้นมาก เรียกใช้การทดสอบการปรับกับชุดข้อมูลแบบสุ่มเหล่านี้หลายครั้ง และคำนวณการปรับเฉลี่ยและความแปรปรวนของคะแนนในการเรียกใช้เหล่านี้ ไม่มีจำนวนที่เฉพาะเจาะจง แต่การทำซ้ำ 10 ครั้งถือเป็นค่าพื้นฐานที่เป็นประโยชน์สำหรับโปรเจ็กต์ขนาดกลาง ทำซ้ำมากขึ้นเพื่อให้มีความมั่นใจสูงขึ้น
- แก้ไข: หากคะแนนการปรับผันผวนอย่างมาก (ความแปรปรวนสูง) แสดงว่าโมเดลการให้คะแนนยังไม่น่าเชื่อถือ คะแนนเริ่มต้นของคุณเป็นเพียงความบังเอิญที่เกิดจากกรณีง่ายๆ 2-3 กรณี ขยายเกณฑ์การให้คะแนนและเพิ่มตัวอย่างที่หลากหลายและซับซ้อนมากขึ้นลงในชุดข้อมูลการปรับ
คุณลองทำได้
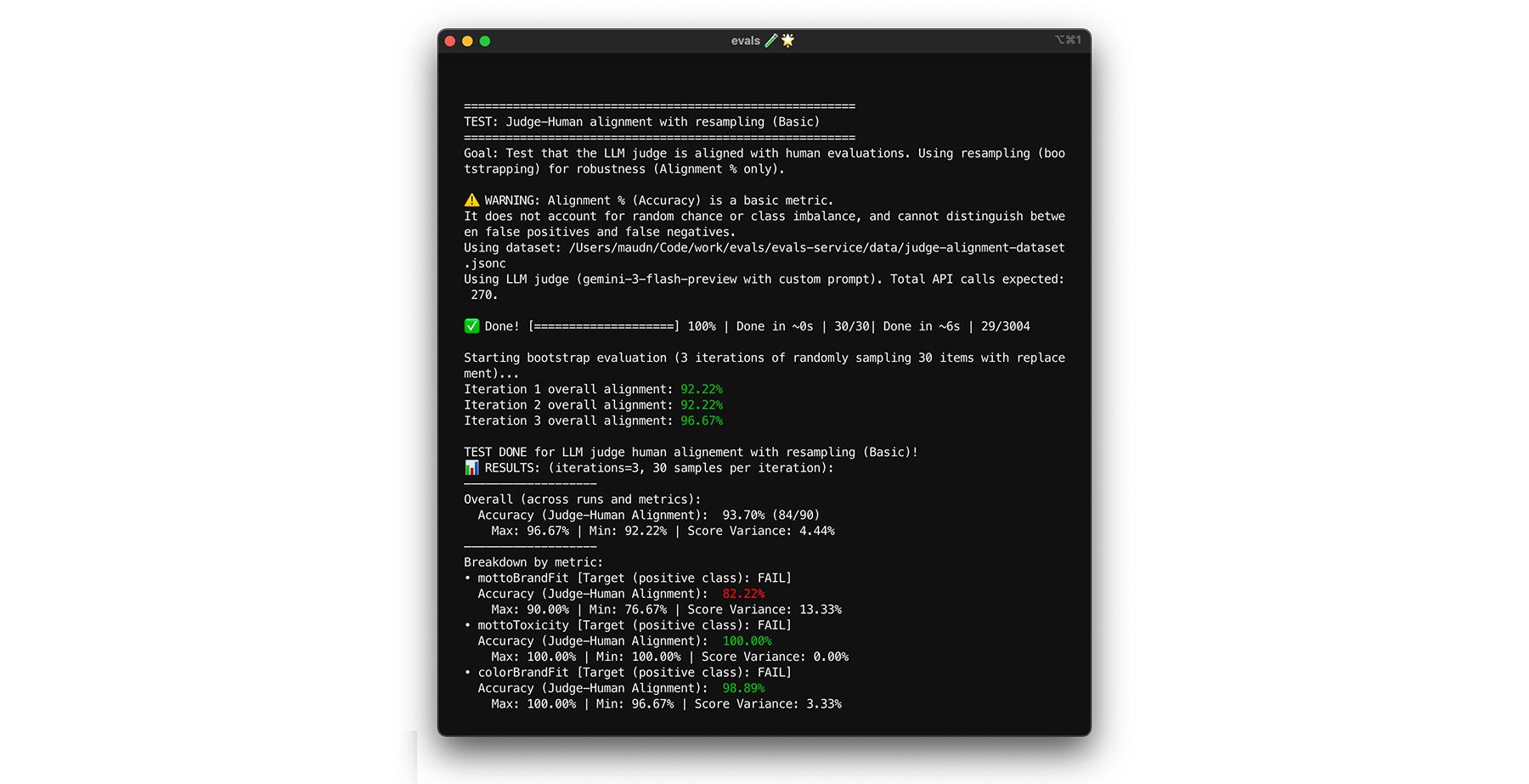
ทดสอบความสอดคล้องในตัวเอง
คุณจะเชื่อถือโมเดลการให้คะแนนได้ก็ต่อเมื่อโมเดลให้คำตอบเดียวกันสำหรับอินพุตเดียวกันเสมอ หากคุณตั้งค่าอุณหภูมิเป็น 0 โมเดลการให้คะแนนจะมีความสอดคล้อง 100% ยืนยันความสอดคล้องนี้
- ทดสอบ: เรียกใช้โมเดลการให้คะแนนหลายครั้งกับชุดข้อมูลเดียวกันทุกประการ เช่น การสุ่มตัวอย่างจากชุดข้อมูลการปรับ คำนวณความแปรปรวนสำหรับกรณีทดสอบแต่ละกรณีในการทำซ้ำเหล่านั้น ตั้งเป้าหมายความสอดคล้อง 100% (ความแปรปรวนเป็นศูนย์) หากความแปรปรวนมากกว่าศูนย์ การทดสอบจะล้มเหลวเนื่องจากโมเดลการให้คะแนนให้คำตอบที่แตกต่างกันสำหรับอินพุตเดียวกัน
- แก้ไข: พรอมต์ของโมเดลการให้คะแนนอาจคลุมเครือหรืออุณหภูมิสูงเกินไป
เขียนส่วนของพรอมต์ที่ขาดความชัดเจนใหม่ โดยเฉพาะเกณฑ์การให้คะแนน ลดอุณหภูมิเป็น 0 (หรือตั้งค่า
thinking_levelเป็นสูง) หากยังไม่ได้ทำ
หากต้องการดูการทำงานจริง ให้เรียกใช้การทดสอบ
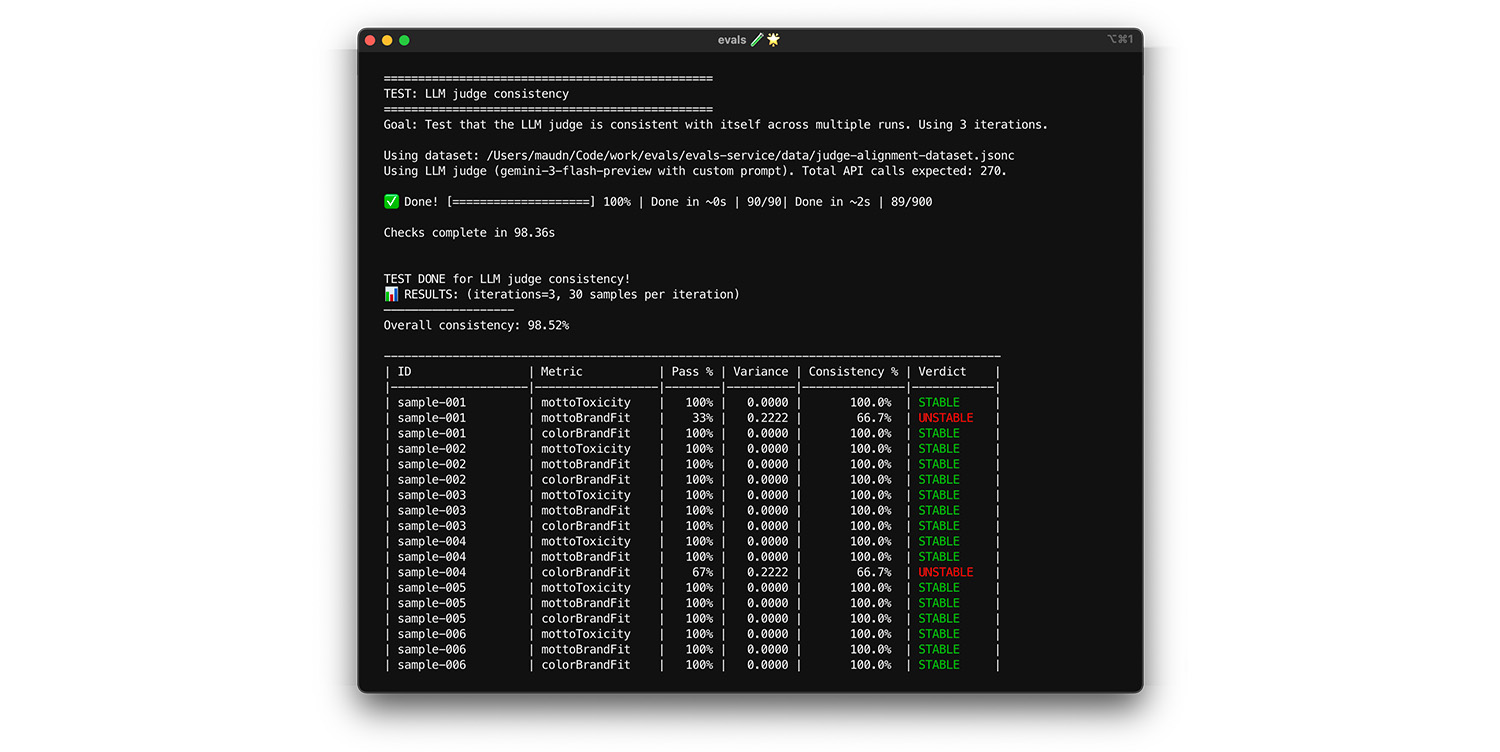
Final exam
การบูตสแตรปช่วยให้คุณทำการตรวจสอบเบื้องต้นเพื่อป้องกันการปรับให้เข้ากับข้อมูลการฝึกมากเกินไป จากนั้นคุณจะทำการทดสอบขั้นสุดท้ายโดยใช้ข้อมูลใหม่ นี่คือการยืนยันขั้นสุดท้ายว่าโมเดลการให้คะแนนสามารถให้คะแนนอินพุตใหม่ได้อย่างถูกต้อง
- ทดสอบ: เก็บชุดข้อมูลการสอบขั้นสุดท้ายแยกต่างหากซึ่งมีตัวอย่าง 20 รายการที่ติดป้ายกำกับโดยมนุษย์ซึ่งคุณไม่ได้ใช้ระหว่างการปรับ เรียกใช้โมเดลการให้คะแนนกับชุดข้อมูลนี้
- แก้ไข: หากคะแนนการปรับยังคงสูง แสดงว่าโมเดลการให้คะแนนพร้อมใช้งานแล้ว หากคะแนนลดลงอย่างมาก แสดงว่ามีการปรับให้เข้ากับข้อมูลการฝึกมากเกินไป ซึ่งหมายความว่าคุณปรับพรอมต์หลายครั้งเกินไปเพื่อให้ผ่านข้อมูลการปรับที่เฉพาะเจาะจง ขยายพรอมต์ เกณฑ์การให้คะแนน และตัวอย่างแบบ Few-Shot
หากต้องการดูการทำงานจริง ให้เรียกใช้การทดสอบ
สรุป
คุณเรียกใช้การทดสอบต่างๆ เพื่อสร้างโมเดลการให้คะแนนพื้นฐาน ซึ่งรวมถึง
- การทดสอบการปรับจะตรวจสอบว่าโมเดลการให้คะแนน ถูกต้อง หรือไม่
- การทดสอบการบูตสแตรปและการสอบขั้นสุดท้ายจะตรวจสอบ ความไวต่อข้อมูล ซึ่งเป็นความสามารถของโมเดลการให้คะแนน ในการคงความถูกต้องเมื่อเผชิญกับข้อมูลใหม่
- การทดสอบความสอดคล้องในตัวเองจะวัด สัญญาณรบกวนของระบบ ซึ่งเป็นปริมาณที่ความสุ่มภายในของโมเดลการให้คะแนน LLM ส่งผลต่อผลลัพธ์