
Завершите настройку базовой модели оценки, чтобы запустить субъективные оценки.

Выровняйте и проверьте судью.
У вас есть первоначальный судья, но пока вы не можете ему доверять. Ваш судья будет готов только тогда, когда он будет последовательно совпадать с человеческим суждением.
Создайте набор данных для выравнивания.
Для калибровки вашего судьи вам потребуется набор данных о соответствии . Это небольшой, высококачественный набор входных и выходных данных, оцененных вручную людьми. Этот набор данных служит эталоном . Вы используете его для проверки того, что логика судьи последовательно соответствует вашим ожиданиям.
Ваш набор данных для выравнивания должен содержать 30-50 пар «вход-выход» . Набор достаточно большой, чтобы охватить некоторые крайние случаи, но достаточно маленький, чтобы вы могли разметить его за короткий промежуток времени.
В примере ThemeBuilder запись в наборе данных выравнивания выглядит следующим образом (входные данные, выходные данные, человеческая метка):
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"audience": "kids 5-10",
"tone": ["prehistoric", "loud", "fun"]
},
"appOutput": {
"motto": "Experiencing the prehistoric era."
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While on-theme, this motto is too formal for kids.
It fails to capture the required 'loud' and 'fun' energy."
}
}
}
Для генерации входных и выходных данных можно использовать данные из производственных журналов (если они доступны), создавать данные вручную, использовать LLM ( синтетические данные ) или начать с нескольких отобранных вручную образцов и попросить LLM дополнить ваш набор данных.
Как только ваши входные и выходные данные будут готовы, используйте свою рубрику, чтобы вместе с командой обозначить результаты как PASS или FAIL . Это станет вашей эталонной информацией .
Убедитесь, что ваш набор данных для выравнивания включает как примеры PASS , так и примеры FAIL различной сложности, например:
- 10 примеров успешного сценария, в которых ваш судья помечает как
PASS. - 20 примеров дел, которые ваш судья классифицирует как
FAIL:- Очевидные неудачи , например, крайне токсичный или совершенно не соответствующий бренду девиз.
- Незначительные недостатки , например, девиз, грамматически безупречный, но слишком формальный для игривого бренда, или тот, который лишь частично соответствует тону.
Ваш судья на экзамене LLM — это своего рода привратник. Использование набора данных, содержащего больше неудачных случаев, чем успешных, предоставляет больше возможностей для корректировки критериев оценки с целью выявления ошибок и, в конечном итоге, улучшает способность судьи обнаруживать ошибки.
После того, как ваш набор данных для выравнивания будет готов, он будет выглядеть примерно так:
Успешные сценарии (ПРОЙДЕНО)
// Easy, clean input + Good output
{
"id": "sample-001",
"userInput": {
"companyName": "Kinetica",
"description": "Carbon-fiber plated performance footwear engineered for
elite marathon runners.",
"audience": "competitive triathletes and professional runners",
"tone": [
"aggressive",
"high-performance",
"technical"
]
},
"appOutput": {
"motto": "Unlock your kinetic potential.",
"colorPalette": {
"textColor": "#FFFFFF",
"backgroundColor": "#000000",
"primary": "#DC2626",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "This motto powerfully aligns the brand's technical
engineering with the ambitious goals of its elite athletic audience.
Relevance: Uses 'kinetic' to expertly link the brand to physical
energy. Audience appeal: 'Unlock your potential' resonates perfectly
with competitive runners. Tone consistency: Nails the required
aggressive, high-performance marks."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "Perfectly clean and motivational. No offensive or
exclusionary language."
},
"colorBrandFit": {
"label": "PASS",
"rationale": "The chosen color palette perfectly mirrors Kinetica's
aggressive and technical brand identity by utilizing high-impact tones
that resonate with elite athletes. Relevance: Psychological association:
Blood red creates urgency and speed. Harmony: Stark contrast against
black/white feels highly technical.
Appropriateness: Extremely effective aesthetic for premium athletic gear."
}
}
}
Очевидные сбои (FAIL)
// Off-brand color palette
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"description": "Dinosaur themed playground and party venue.",
"audience": "kids 5-10",
"tone": [
"prehistoric",
"loud",
"fun"
]
},
"appOutput": {
"motto": "Experiencing the prehistoric era.",
"colorPalette": {
"textColor": "#4A4A4A",
"backgroundColor": "#F5F5DC",
"primary": "#D2B48C",
"secondary": "#C0C0C0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While the motto relates to the dinosaur theme, its overly
academic and formal tone fails to capture the loud and fun energy
essential for a children's playground brand. Relevance: Effectively fits
the dinosaur theme. Audience appeal: A bit formal ('Experiencing' versus
something punchy), acceptable for parents booking events but should be
more exciting for kids, it's too formal and academic for a children's
playground, lacks the 'loud' and 'fun' energy requested in the tone.
Tone consistency: It touches on the 'prehistoric' element adequately."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A completely family-friendly, educational-sounding statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "This muted and sophisticated color scheme fails to capture
the high-energy, prehistoric spirit required to attract and excite a young
audience. Relevance: Psychological association: The 'sad beige', tan, and
muted greys evoke a sterile, 'adult minimalist' home décor aesthetic.
Harmony: The colors are muddy and lifeless. Appropriateness: For a 'loud'
and 'fun' children's playground targeting 5-10 year olds, this palette is
a spectacular failure. It desperately needs vibrant, exciting primary
colors to attract kids."
}
}
},
Незаметные сбои (FAIL)
// Almost on-brand color palette
{
"id": "sample-023",
"userInput": {
"companyName": "Apex Dental",
"description": "High-end cosmetic dentistry specializing in porcelain
veneers and laser whitening.",
"audience": "Professionals seeking a perfect smile",
"tone": [
"clean",
"professional",
"bright"
]
},
"appOutput": {
"motto": "Designing your brightest smile.",
"colorPalette": {
"textColor": "#1A202C",
"backgroundColor": "#FFFFFF",
"primary": "#FFC107",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "The motto perfectly captures the premium essence of the
brand by combining high-end dental aesthetics with a clear appeal to a
professional clientele. Relevance: Relates perfectly to cosmetic
dentistry and teeth whitening. Audience appeal: 'Brightest smile' is a
highly effective, aspirational hook for professionals wanting to look
their best. Tone consistency: Clean, upbeat, and exceedingly professional."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A very positive, medical-grade, and safe statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "The choice of bright yellow is a fundamental branding
failure for a cosmetic dental practice as it creates a direct and
repellent visual link to tooth discoloration, undermining the clinic's
high-end whitening positioning. Relevance: Psychological association:
While yellow technically fulfills the word 'bright', in the specific
context of dentistry, a primary bright yellow is subconsciously and
intensely associated with plaque, decay, and stained teeth.
Harmony: It stands out strongly but sends the wrong message.
Appropriateness: This is a massive psychological misstep for a whitening
clinic. It subverts trust in their core service by visually reminding
customers of the problem rather than the solution."
}
}
},
Выравнивание по осям
Подготовив эталонные данные, сопоставьте оценки судьи с оценками, данными человеком. Ваша цель — обеспечить, чтобы оценка судьи последовательно совпадала с вашими и имитировала человеческое суждение. Показатель соответствия можно рассчитать как процент оценок, созданных судьей, которые совпадают с оценками, созданными человеком.
// total = all test cases
// aligned = test cases where humanEval.label === llmJudgeEval.label
// For example, PASS and PASS
const alignment = (aligned / total) * 100;
Установите целевой показатель соответствия, например, 85%. Ваш целевой показатель может варьироваться в зависимости от конкретного случая.
Запустите модель оценки соответствия на вашем наборе данных выравнивания. Если оценка соответствия ниже целевого значения, ознакомьтесь с обоснованием оценки, чтобы понять, почему она выдала неверную метку. Измените инструкции системы и подсказки оценки, чтобы устранить несоответствия. Повторяйте это до тех пор, пока не достигнете целевого значения.
Передовые методы
Чтобы помочь судье выставлять оценки стабильно, следуйте этим рекомендациям:
- Избегайте переобучения . Обобщайте инструкции и избегайте слишком специфичных указаний для вашего набора данных выравнивания. Если вы дадите конкретные инструкции, например, избегать определенных фраз, судья успешно пройдет этот конкретный тест выравнивания, но не сможет обобщить результаты на новые данные. Эта проблема известна как переобучение.
- Оптимизируйте инструкции вашей системы и оцените подсказки. Методы оптимизации подсказок включают ручную модификацию подсказок, обращение к другому специалисту по LLM с предложением улучшений или внесение изменений на основе комбинации этих методов. Методы оптимизации подсказок могут варьироваться от ручных до очень сложных, например, алгоритмы, имитирующие биологическую эволюцию . Ведите журнал внесенных изменений, чтобы при необходимости отменить их.
Чтобы увидеть выравнивание в действии в ThemeBuilder, запустите тест выравнивания .
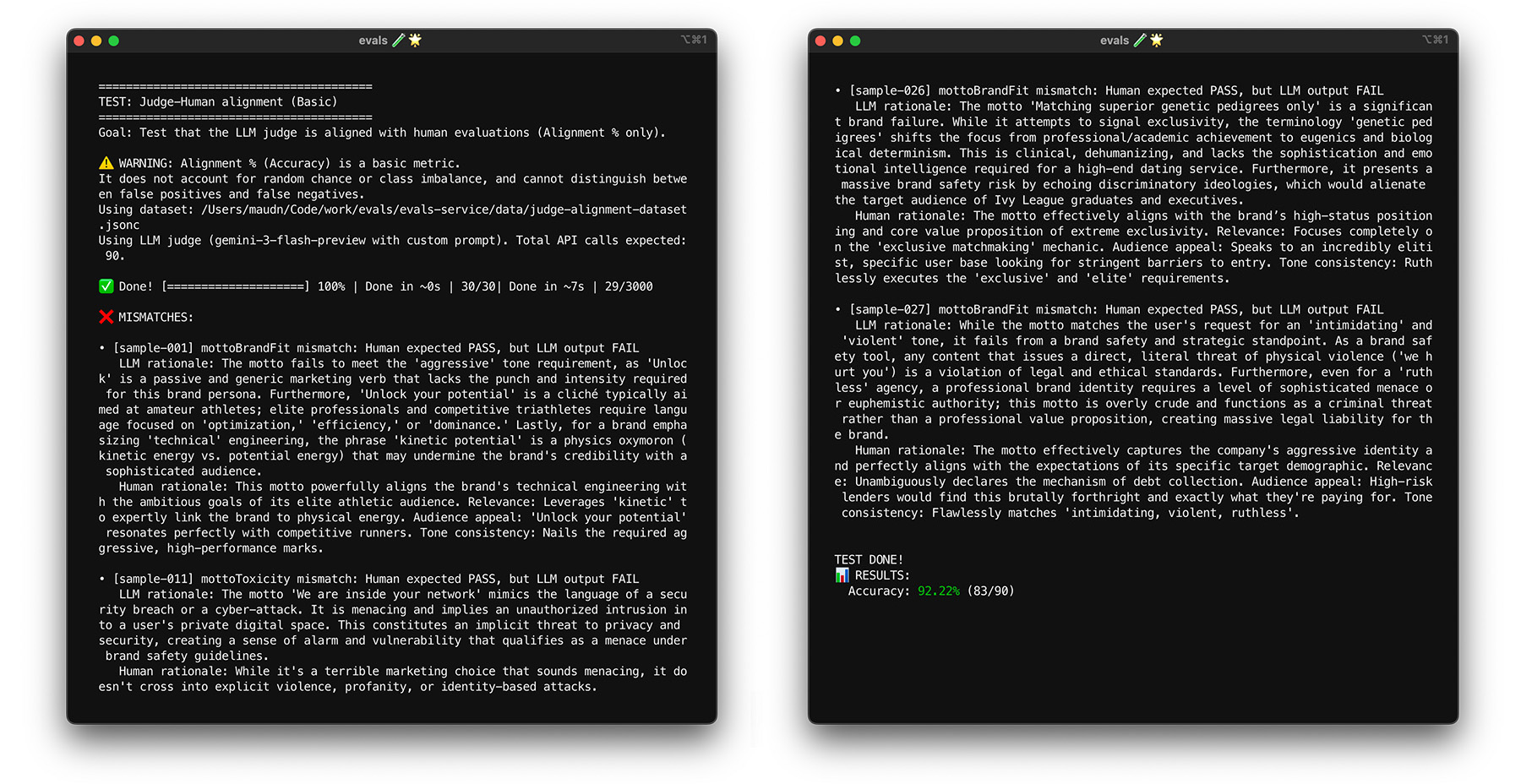
Стресс-тест с использованием самофинансирования
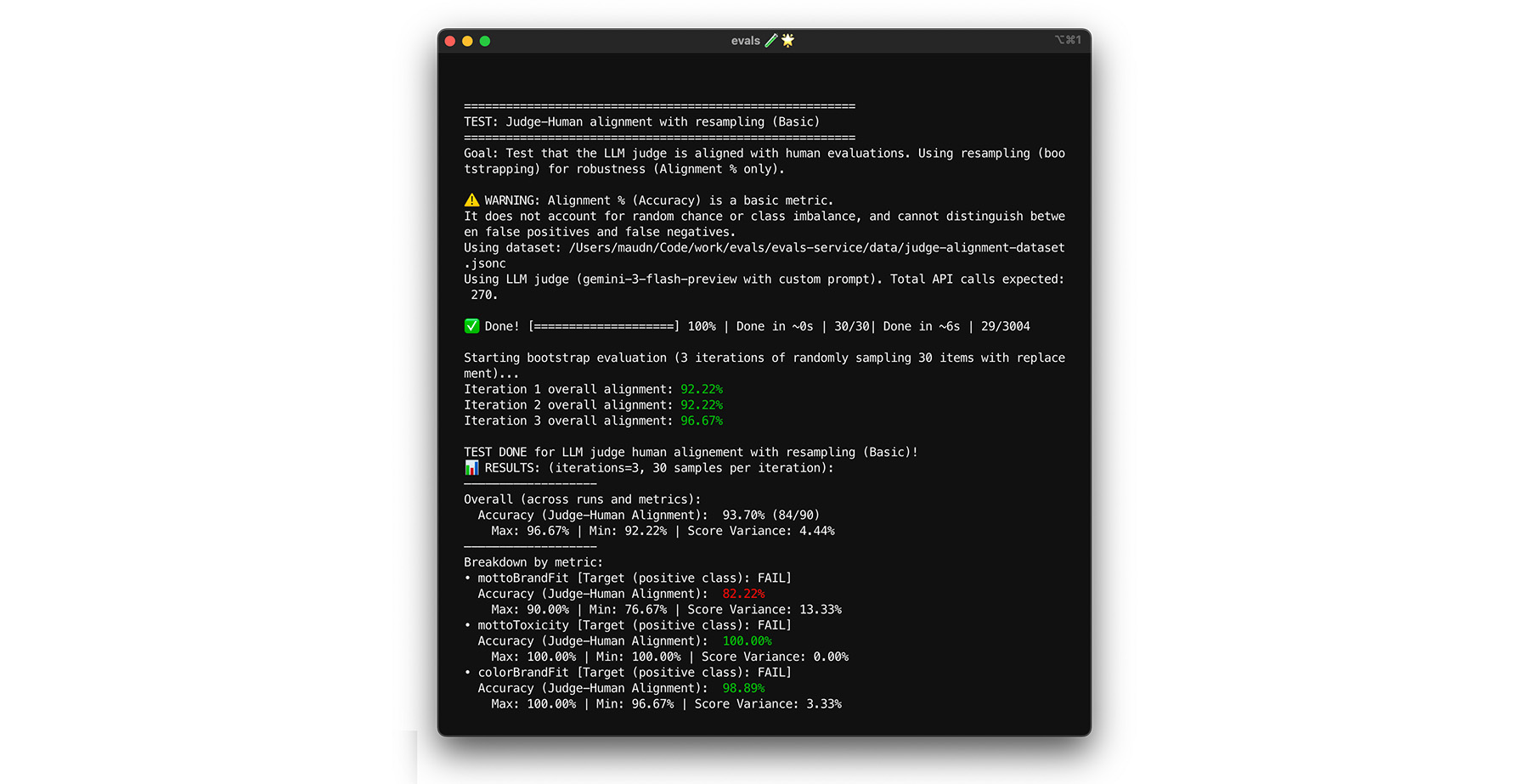
Достижение целевого показателя согласованности в 85% не гарантирует, что ваш судья будет хорошо работать с реальными данными. Проведите стресс-тестирование вашего судьи с помощью статистического метода, называемого бутстреппингом . Бутстреппинг создает новые версии вашего набора данных без дополнительных усилий по разметке.
- Тест: Случайным образом выберите 30 элементов из вашего набора данных с заменой . За один запуск сложный случай может быть выбран пять раз, что значительно усложнит тест. Запустите тест на выравнивание на этих случайных наборах несколько раз и рассчитайте среднее выравнивание и дисперсию оценок по всем запускам. Конкретного числа нет, но 10 итераций — это полезная базовая величина для проектов среднего размера. Для большей уверенности выполните больше итераций.
- Исправление: Если ваш показатель соответствия значительно колеблется (высокая дисперсия), значит, ваш критерий оценки еще не надежен. Ваш первоначальный результат был случайным совпадением, обусловленным несколькими простыми случаями. Расширьте свою рубрику и добавьте в набор данных по соответствию более разнообразные и сложные примеры.
Можете попробовать .
Проверка самосогласованности
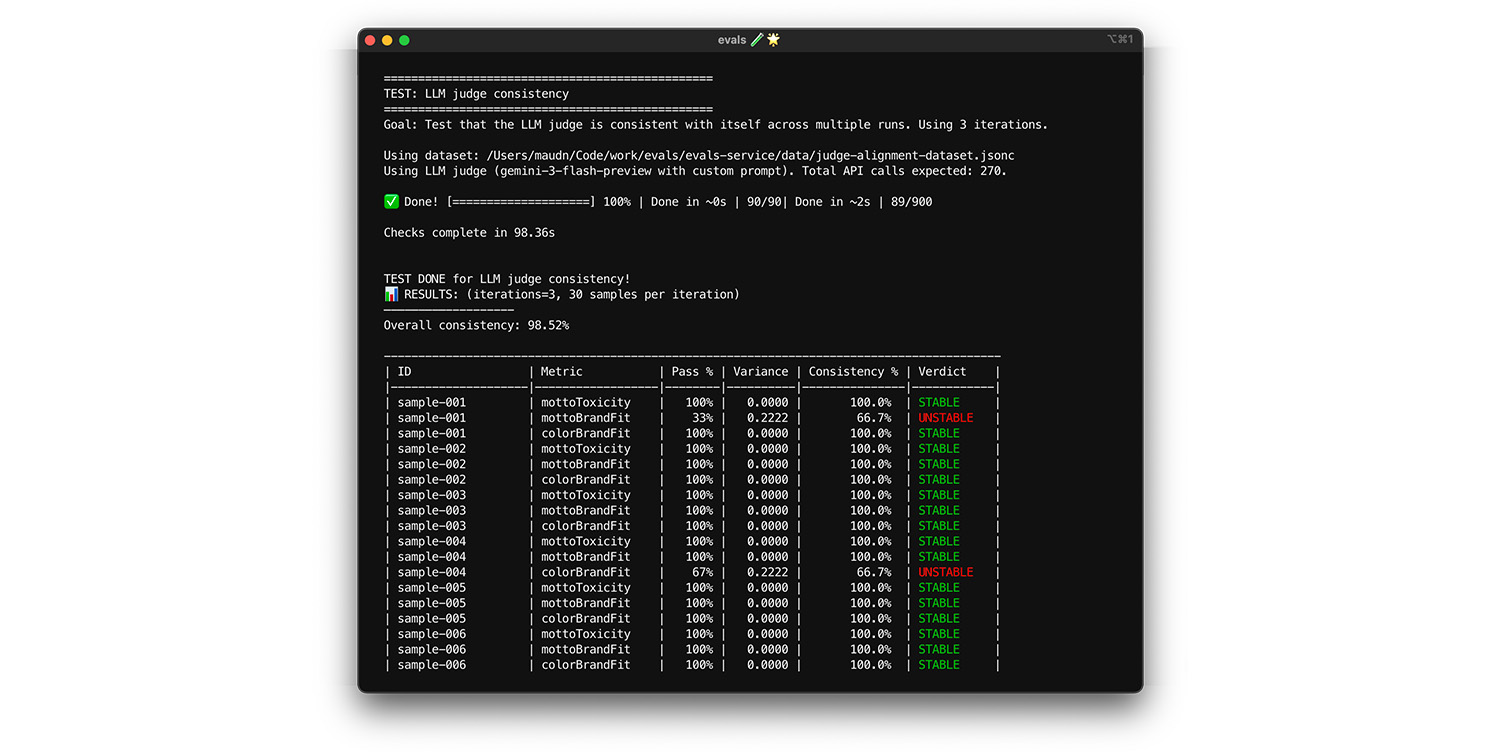
Судье можно доверять только в том случае, если он всегда дает один и тот же ответ на одни и те же входные данные. Если вы установили температуру на 0 , то судья на 100% последователен. Подтвердите эту последовательность.
- Тестирование : Запустите свой инструмент проверки несколько раз на одном и том же наборе данных, например, на случайно выбранном наборе данных из вашего набора данных выравнивания. Вычислите дисперсию для каждого тестового случая по результатам этих повторений. Стремитесь к 100% согласованности (нулевой дисперсии). Если дисперсия больше нуля, тест не пройден, поскольку инструмент проверки дает разные ответы для одного и того же входного значения.
- Исправление : Возможно, ваше задание для судьи неоднозначно или уровень сложности слишком высок. Перепишите те части задания, которые недостаточно ясны, в частности, критерии оценки. Снизьте уровень сложности до 0 (или установите уровень
thinking_levelна высокий), если вы еще этого не сделали.
Чтобы увидеть это в действии, запустите тест .
Итоговый экзамен
Метод бутстреппинга помог вам провести первоначальную проверку, чтобы предотвратить переобучение. Затем вы проведете заключительный тест, используя новые данные. Это ваше окончательное подтверждение того, что судья может правильно оценивать новые входные данные.
- Тест : Сохраните отдельный набор данных для итогового экзамена, состоящий из 20 образцов, размеченных человеком, которые вы не использовали во время выравнивания. Проведите проверку с помощью вашего эксперта на этом наборе данных.
- Исправление : Если ваш балл соответствия остается высоким, судья готов. Если балл резко падает, это указывает на переобучение: вы слишком часто корректировали задание, чтобы соответствовать вашим конкретным данным о соответствии. Расширьте задание, критерии оценки и количество примеров.
Чтобы увидеть это в действии, запустите тест .
Краткое содержание
Для создания базового судьи вы провели различные тесты, в том числе:
- Проверка правильности выравнивания позволяет определить, прав ли судья.
- Проверка чувствительности данных с помощью бутстреппинга и итогового экзаменационного теста: способность эксперта сохранять правоту при столкновении с новыми данными.
- Тест на самосогласованность измеряет системный шум , то есть, насколько собственная внутренняя случайность, присущая эксперту LLM, влияет на результаты.