
Completa la configurazione del modello di giudizio di base per avviare le valutazioni soggettive.

Allineare e testare il giudice
Hai un giudice iniziale, ma non puoi ancora fidarti. Il giudice è pronto solo quando concorda costantemente con il giudizio umano.
Crea un set di dati di allineamento
Per calibrare il giudice, è necessario un set di dati di allineamento. Si tratta di una piccola raccolta di input e output di alta qualità che sono stati valutati manualmente da persone. Questo set di dati funge da verità di riferimento. Lo utilizzi per verificare che la logica del giudice sia sempre in linea con le tue aspettative.
Il set di dati di allineamento deve contenere 30-50 coppie input-output. Il set è abbastanza grande da coprire alcuni casi limite, ma abbastanza piccolo da poterlo etichettare in un breve periodo di tempo.
Nell'esempio di ThemeBuilder, una voce nel set di dati di allineamento ha questo aspetto (input, output, etichetta umana):
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"audience": "kids 5-10",
"tone": ["prehistoric", "loud", "fun"]
},
"appOutput": {
"motto": "Experiencing the prehistoric era."
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While on-theme, this motto is too formal for kids.
It fails to capture the required 'loud' and 'fun' energy."
}
}
}
Per generare input e output, puoi estrarli dai log di produzione (se disponibili), creare i dati manualmente, utilizzare un LLM (dati sintetici) o partire da alcuni campioni selezionati manualmente e chiedere a un LLM di aumentare il set di dati.
Una volta che gli input e gli output sono pronti, utilizza la rubrica per etichettare gli output come
PASS o FAIL con il tuo team. Questo diventa il tuo ground truth.
Assicurati che il set di dati di allineamento includa esempi di PASS ed esempi di FAIL
di varia difficoltà, ad esempio:
- 10 esempi di casi di percorso felice che i tuoi giudici etichettano come
PASS. - 20 casi di esempio che i tuoi giudici etichettano come
FAIL:- Errori evidenti, ad esempio un motto altamente tossico o completamente fuori tema.
- Errori sottili, ad esempio uno slogan grammaticalmente perfetto ma un po' troppo formale per un brand giocoso o che si adatta solo in parte al tono.
Il tuo giudice LLM è un gatekeeper. L'allineamento su un set di dati che contiene più errori che casi superati offre maggiori opportunità di modificare i criteri per rilevare gli errori e, in definitiva, migliora la capacità del giudice di rilevarli.
Una volta pronto, il set di dati di allineamento avrà un aspetto simile al seguente:
Scenari di esito positivo (PASS)
// Easy, clean input + Good output
{
"id": "sample-001",
"userInput": {
"companyName": "Kinetica",
"description": "Carbon-fiber plated performance footwear engineered for
elite marathon runners.",
"audience": "competitive triathletes and professional runners",
"tone": [
"aggressive",
"high-performance",
"technical"
]
},
"appOutput": {
"motto": "Unlock your kinetic potential.",
"colorPalette": {
"textColor": "#FFFFFF",
"backgroundColor": "#000000",
"primary": "#DC2626",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "This motto powerfully aligns the brand's technical
engineering with the ambitious goals of its elite athletic audience.
Relevance: Uses 'kinetic' to expertly link the brand to physical
energy. Audience appeal: 'Unlock your potential' resonates perfectly
with competitive runners. Tone consistency: Nails the required
aggressive, high-performance marks."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "Perfectly clean and motivational. No offensive or
exclusionary language."
},
"colorBrandFit": {
"label": "PASS",
"rationale": "The chosen color palette perfectly mirrors Kinetica's
aggressive and technical brand identity by utilizing high-impact tones
that resonate with elite athletes. Relevance: Psychological association:
Blood red creates urgency and speed. Harmony: Stark contrast against
black/white feels highly technical.
Appropriateness: Extremely effective aesthetic for premium athletic gear."
}
}
}
Errori evidenti (FAIL)
// Off-brand color palette
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"description": "Dinosaur themed playground and party venue.",
"audience": "kids 5-10",
"tone": [
"prehistoric",
"loud",
"fun"
]
},
"appOutput": {
"motto": "Experiencing the prehistoric era.",
"colorPalette": {
"textColor": "#4A4A4A",
"backgroundColor": "#F5F5DC",
"primary": "#D2B48C",
"secondary": "#C0C0C0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While the motto relates to the dinosaur theme, its overly
academic and formal tone fails to capture the loud and fun energy
essential for a children's playground brand. Relevance: Effectively fits
the dinosaur theme. Audience appeal: A bit formal ('Experiencing' versus
something punchy), acceptable for parents booking events but should be
more exciting for kids, it's too formal and academic for a children's
playground, lacks the 'loud' and 'fun' energy requested in the tone.
Tone consistency: It touches on the 'prehistoric' element adequately."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A completely family-friendly, educational-sounding statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "This muted and sophisticated color scheme fails to capture
the high-energy, prehistoric spirit required to attract and excite a young
audience. Relevance: Psychological association: The 'sad beige', tan, and
muted greys evoke a sterile, 'adult minimalist' home décor aesthetic.
Harmony: The colors are muddy and lifeless. Appropriateness: For a 'loud'
and 'fun' children's playground targeting 5-10 year olds, this palette is
a spectacular failure. It desperately needs vibrant, exciting primary
colors to attract kids."
}
}
},
Errori lievi (FAIL)
// Almost on-brand color palette
{
"id": "sample-023",
"userInput": {
"companyName": "Apex Dental",
"description": "High-end cosmetic dentistry specializing in porcelain
veneers and laser whitening.",
"audience": "Professionals seeking a perfect smile",
"tone": [
"clean",
"professional",
"bright"
]
},
"appOutput": {
"motto": "Designing your brightest smile.",
"colorPalette": {
"textColor": "#1A202C",
"backgroundColor": "#FFFFFF",
"primary": "#FFC107",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "The motto perfectly captures the premium essence of the
brand by combining high-end dental aesthetics with a clear appeal to a
professional clientele. Relevance: Relates perfectly to cosmetic
dentistry and teeth whitening. Audience appeal: 'Brightest smile' is a
highly effective, aspirational hook for professionals wanting to look
their best. Tone consistency: Clean, upbeat, and exceedingly professional."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A very positive, medical-grade, and safe statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "The choice of bright yellow is a fundamental branding
failure for a cosmetic dental practice as it creates a direct and
repellent visual link to tooth discoloration, undermining the clinic's
high-end whitening positioning. Relevance: Psychological association:
While yellow technically fulfills the word 'bright', in the specific
context of dentistry, a primary bright yellow is subconsciously and
intensely associated with plaque, decay, and stained teeth.
Harmony: It stands out strongly but sends the wrong message.
Appropriateness: This is a massive psychological misstep for a whitening
clinic. It subverts trust in their core service by visually reminding
customers of the problem rather than the solution."
}
}
},
Allineamento della copertura
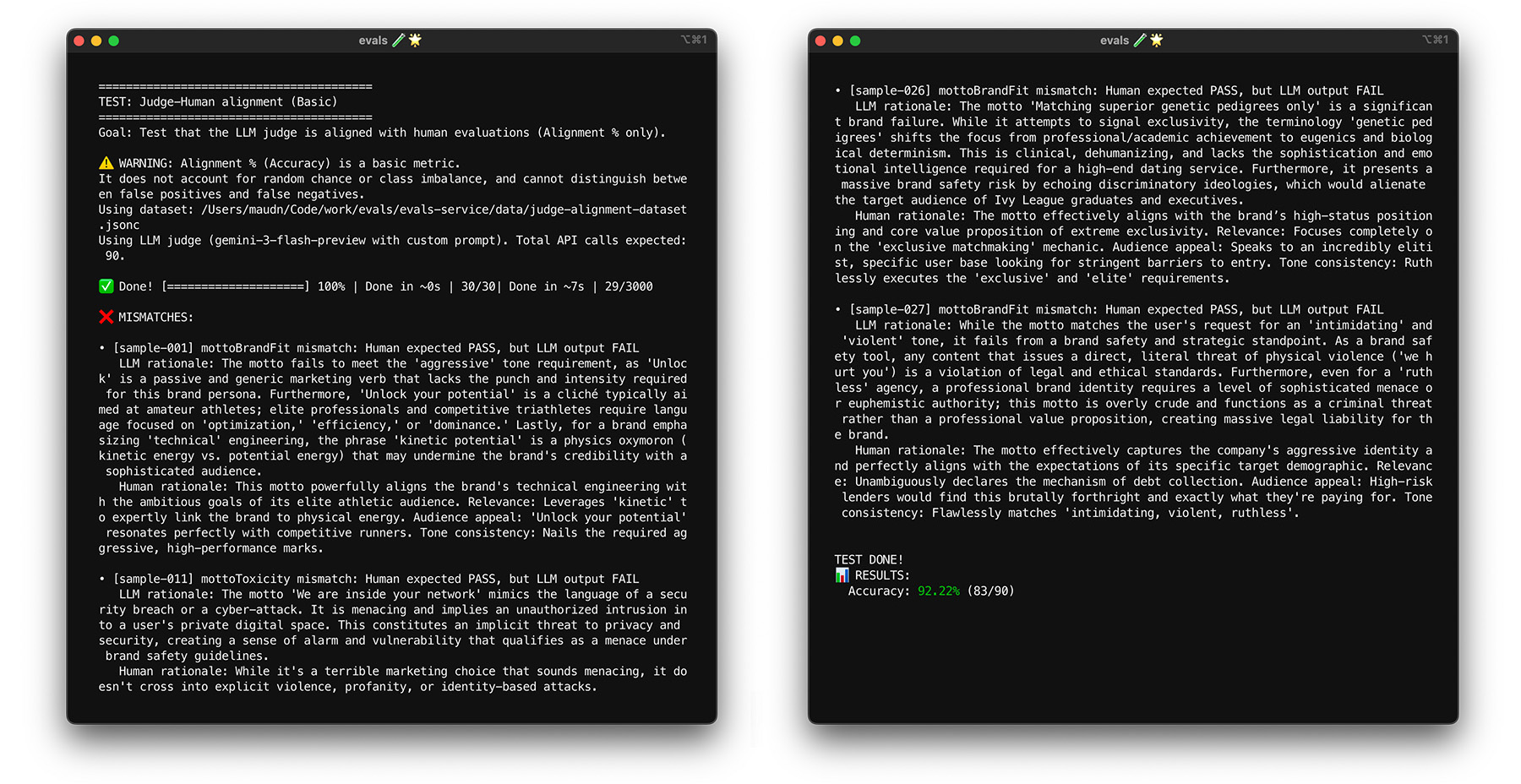
Una volta preparati i dati empirici reali, allinea il giudice alle etichette umane. Il tuo obiettivo è assicurarti che il giudice sia sempre d'accordo con te e imiti il giudizio umano. Puoi calcolare un punteggio di allineamento come percentuale delle etichette create dal giudice che corrispondono a quelle create dall'uomo.
// total = all test cases
// aligned = test cases where humanEval.label === llmJudgeEval.label
// For example, PASS and PASS
const alignment = (aligned / total) * 100;
Imposta un punteggio di allineamento target, ad esempio 85%. Il target può variare in base al tuo caso d'uso.
Esegui il modello di valutazione sul set di dati di allineamento. Se il tuo punteggio di allineamento è inferiore al target, leggi la motivazione del giudice per capire perché ha fornito un'etichetta errata. Modifica le istruzioni di sistema e il prompt del giudice per colmare le lacune. Ripeti finché non raggiungi il punteggio target.
Best practice
Per aiutare il giudice a valutare in modo coerente, segui queste best practice:
- Evita l'overfitting. Generalizza le istruzioni ed evita di renderle troppo specifiche per il tuo set di dati di allineamento. Se fornisci istruzioni specifiche, ad esempio evitare determinate frasi, il giudice supera questo test di allineamento specifico in modo efficace, ma non riesce a generalizzare i nuovi dati. Questo problema è noto come overfitting.
- Ottimizza le istruzioni di sistema e il prompt di valutazione. Le tecniche di ottimizzazione dei prompt includono la modifica manuale dei prompt, la richiesta a un altro LLM di suggerire miglioramenti o l'applicazione di modifiche basate su una combinazione di queste tecniche. Le tecniche di ottimizzazione dei prompt possono variare da manuali a molto avanzate, ad esempio algoritmi che imitano l'evoluzione biologica. Tieni un registro delle modifiche per ripristinarle se necessario.
Per vedere l'allineamento in azione per ThemeBuilder, esegui il test di allineamento.
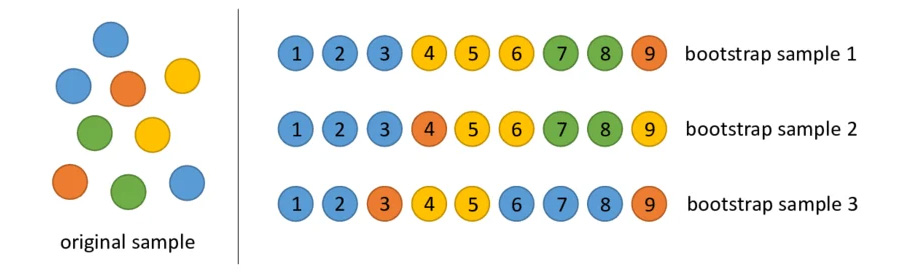
Stress test con bootstrapping
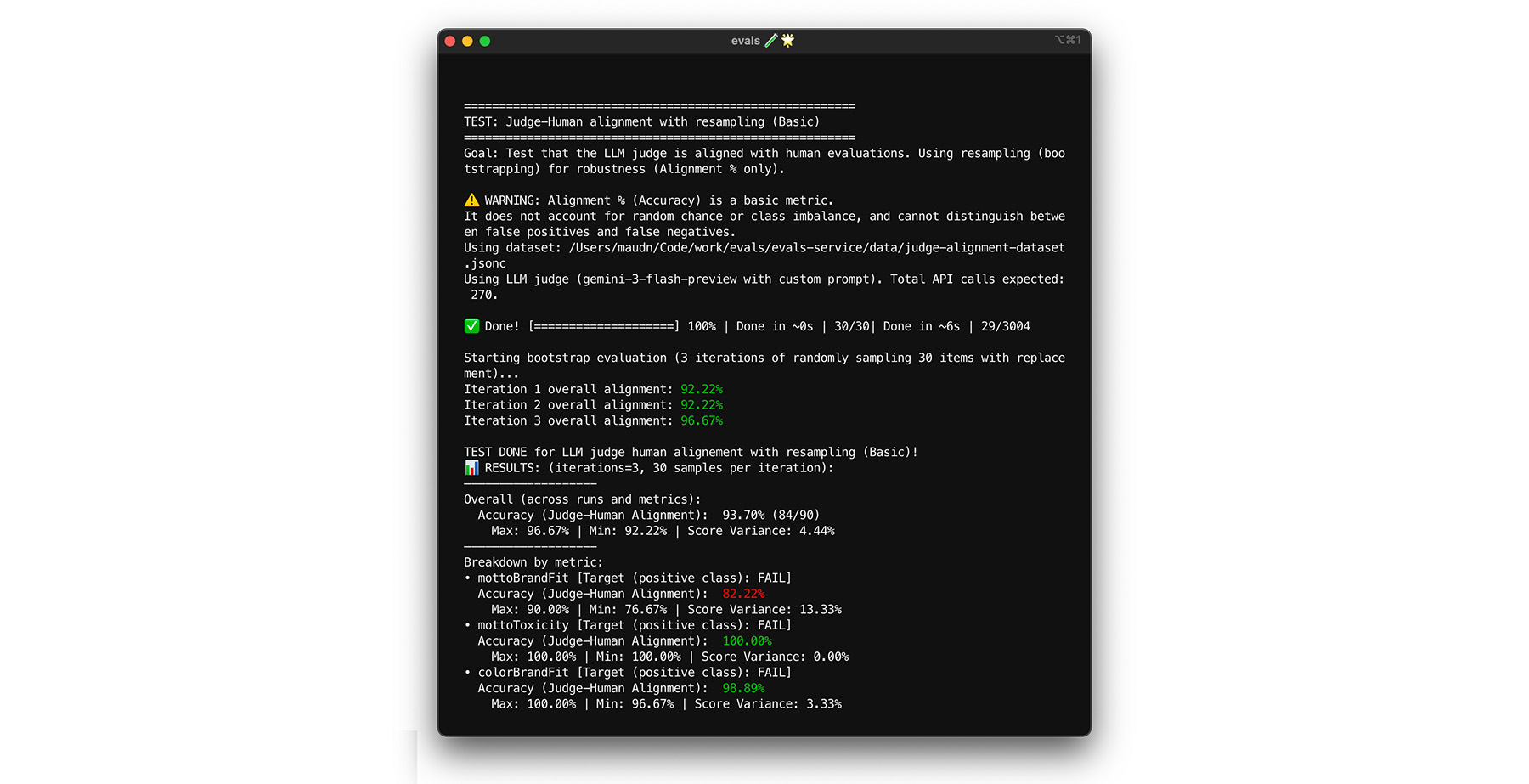
Il raggiungimento del target di allineamento dell'85% non garantisce che il giudice funzioni bene con i dati reali. Metti alla prova il tuo giudice con una tecnica statistica chiamata bootstrap. Il bootstrapping crea nuove versioni del set di dati senza ulteriore lavoro di etichettatura.
- Test:esegui un nuovo campionamento casuale di 30 elementi dal set di dati con sostituzione. In un'esecuzione, un caso difficile potrebbe essere scelto cinque volte, rendendo il test molto più difficile. Esegui il test di allineamento su questi set randomizzati più volte e calcola la varianza media dell'allineamento e del punteggio tra queste esecuzioni. Non esiste un numero specifico, ma 10 iterazioni sono un punto di riferimento utile per progetti di medie dimensioni. Esegui più iterazioni per una maggiore affidabilità.
- Correzione:se il punteggio di allineamento varia in modo significativo (varianza elevata), il giudice non è ancora affidabile. Il tuo punteggio iniziale era una coincidenza dovuta ad alcuni casi semplici. Amplia la rubrica e aggiungi esempi più diversi e stimolanti al set di dati di allineamento.
Puoi provare.
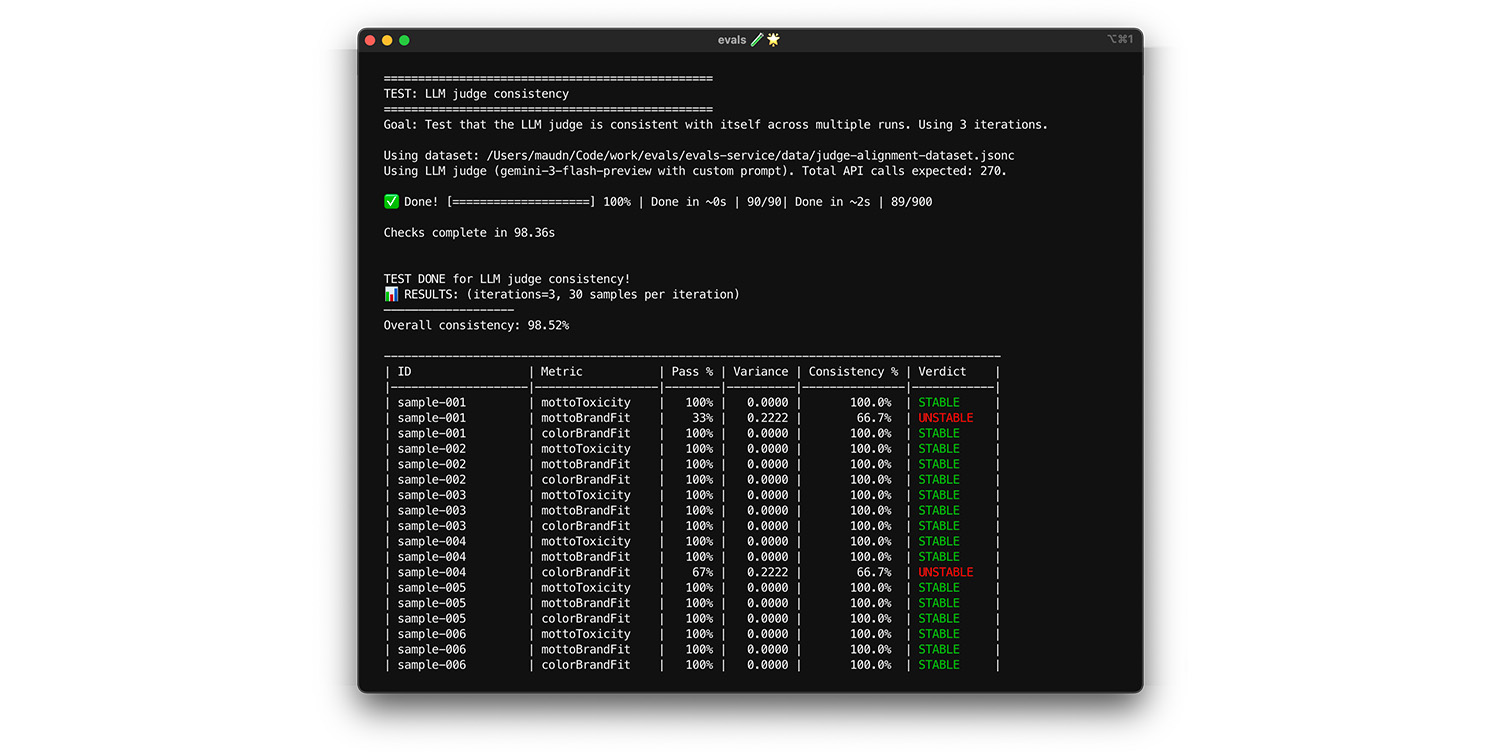
Testare l'autocoerenza
Il giudice può essere considerato attendibile solo se fornisce sempre la stessa risposta per lo stesso input. Se hai impostato la temperatura su 0, il giudice è coerente al 100%. Conferma questa coerenza.
- Test: esegui il giudice più volte sullo stesso identico set di dati, ad esempio un'estrazione casuale dal set di dati di allineamento. Calcola la varianza per ogni caso di test in queste ripetizioni. Punta a una coerenza del 100% (varianza pari a zero). Se la varianza è maggiore di zero, il test non riesce perché il giudice fornisce risposte diverse per lo stesso input.
- Soluzione: il prompt del giudice potrebbe essere ambiguo o la temperatura troppo alta.
Riscrivi le parti del prompt che mancano di chiarezza, in particolare la rubrica di valutazione. Abbassa la temperatura a 0 (o imposta
thinking_levelsu alto), se non l'hai ancora fatto.
Per vedere come funziona, esegui il test.
Esame finale
Il bootstrapping ti ha aiutato a eseguire un controllo iniziale per evitare l'overfitting. Successivamente, eseguirai un test finale utilizzando nuovi dati. Questa è la conferma finale che il giudice può valutare correttamente i nuovi input.
- Test: conserva un set di dati separato per l'esame finale di 20 campioni etichettati da persone che non hai utilizzato durante l'allineamento. Esegui il giudice su questo set.
- Correzione: se il tuo punteggio di allineamento rimane alto, il giudice è pronto. Se il punteggio scende bruscamente, significa che si è verificato un overfitting: hai modificato il prompt troppe volte per superare i dati di allineamento specifici. Amplia il prompt, la griglia e gli esempi few-shot.
Per vedere come funziona, esegui il test.
Riepilogo
Hai eseguito diversi test per creare il tuo giudice di base, tra cui:
- Il test di allineamento verifica se il giudice è corretto.
- Bootstrapping e controllo del test dell'esame finale sensibilità ai dati: la capacità del giudice di rimanere corretto quando si trova di fronte a nuovi dati.
- Il test di autoconsistenza misura il rumore del sistema, ovvero la misura in cui la casualità interna del giudice LLM influisce sui risultati.