
應用工程訣竅,建構 AI 測試管道。

Maud Nalpas
您已設計評量表、撰寫以規則為準的評估,並調整評估模型。現在,我們將這些內容整合到自動化持續測試管道中。
每個專案都不盡相同,本單元將介紹一種有效的分層方法,協助您建構評估管道。
如要建構評估管道,您需要下列項目:
- 評估人員的自動調度管理工具
- 處理多個 API 呼叫並解決潛在失敗問題的策略
- 標準化輸出格式
- 報表介面
協調 API 呼叫

建立主要函式,協調規則式和 LLM 評審評估工具。
查看範例程式碼中的 evalAll()。
將 LLM 評審模型設定 (系統指令、結構化輸出邏輯和重試) 集中到單一公用函式,您可以在評估工具中重複使用。查看範例程式碼中的 evalWithLLM()。
處理模型 API 負載過重和失敗問題
模型 API 有時會過載或逾時。如果 API 呼叫失敗,請觸發自動重試。重試次數用盡後,請回報 ERROR。回報評估結果會FAIL導致結果失真。
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
執行評估時,請選擇下列其中一個選項:
- 並行發出 API 呼叫,這樣一項評估作業逾時就不會導致其他作業當機。視用途和評估模型而定,這項功能可減少模型產生錯覺,因為評估模型會專注於一項工作。
- 發出單一批次呼叫。這會造成單點故障,例如模型超出權杖限制。
準備進行多次疊代
由於 LLM 不具確定性,應用程式輸出內容會有所不同。
如要準確測試這項功能,並確保輸出內容符合品質標準,請按照下列步驟操作:
- 針對每個測試案例輸入生成多個輸出 (通常為 5 到 10 個)。
- 分別評估每個輸出內容。
- 查看各疊代版本的整體結果。
取得實務上的平衡:疊代次數越多,迴歸確定性就越高,但疊代次數越少,執行速度越快,可順暢地納入持續測試管道。
定義評估管道輸出內容
評估結果應包含下列資訊:
- 穩定率,例如通過 8/10 次 → 穩定率為 80%。設定門檻,評估功能何時可供正式環境使用。
- 您的應用程式設定。包括系統指令、使用者提示詞,以及溫度參數或思考層級等 LLM 參數。您需要這項資訊,才能排解評估分數回歸問題。提示詞可能是略有差異的長字串,因此請在提示詞中加入版本號碼,並儲存提示詞的雜湊值,以便追蹤。
- 評估人員設定或版本號碼。如果法官更新後分數大幅變動,您就需要這項資訊。
以下是 ThemeBuilder 評估的 EvalResponse JSON 物件範例:
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
導入報表介面
將結果輸出至 HTML 報表或乾淨的網頁 UI,以便剖析、分享、比較及偵錯結果隨時間的變化。
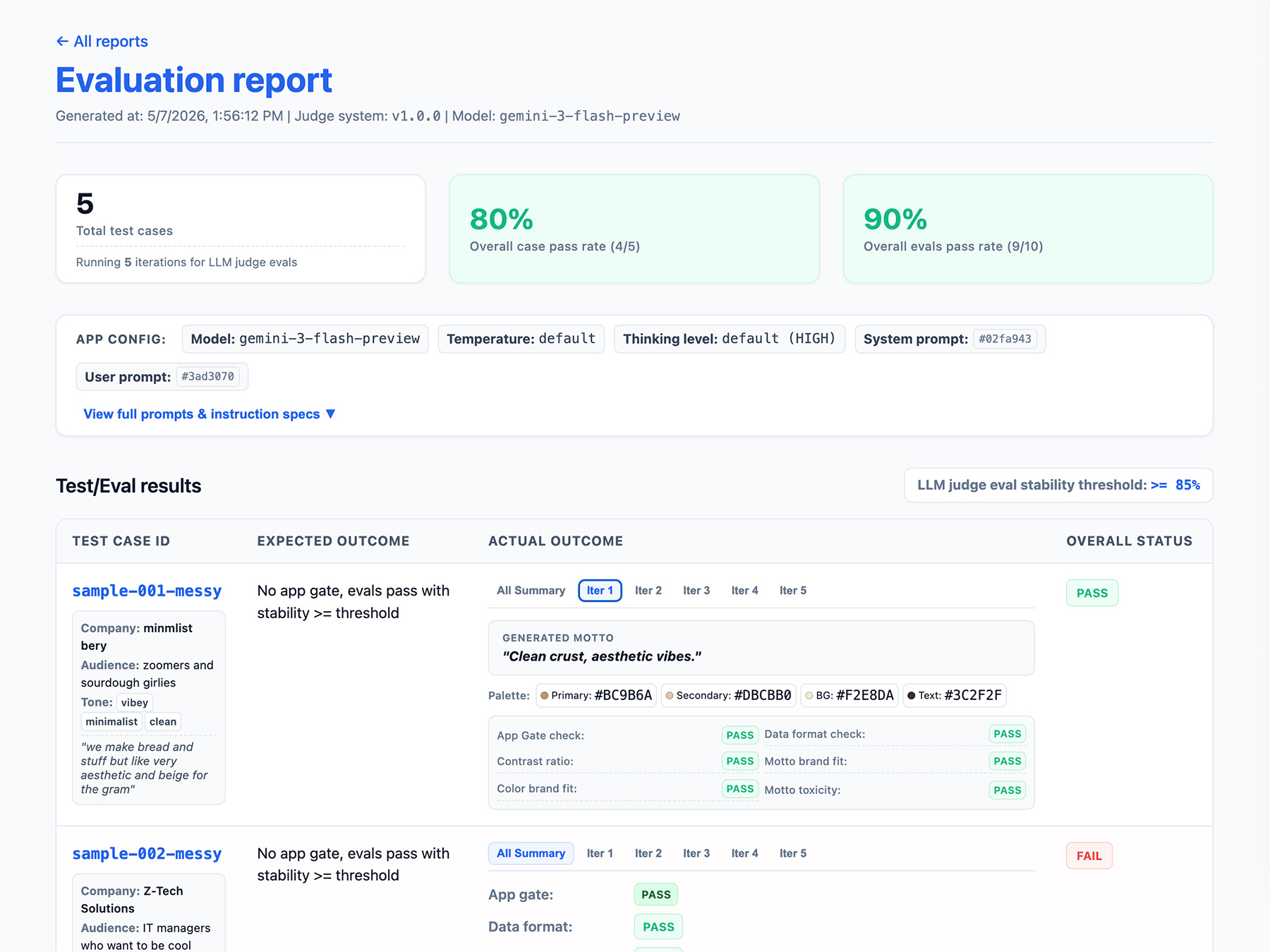

現在執行評估。