

Künstliche Intelligenz (KI) umfasst viele komplexe, neue Technologien, für die früher menschliche Eingaben erforderlich waren und die jetzt von einem Computer ausgeführt werden können. Im Allgemeinen ist KI ein nicht menschliches Programm oder Modell, das ein breites Spektrum an Problemlösungs- und Kreativitätsfähigkeiten aufweist.
Das Akronym KI wird oft synonym für verschiedene Arten von Technologien im Bereich der künstlichen Intelligenz verwendet, die sich jedoch in ihrem Umfang stark unterscheiden können.
Es gibt eine Reihe von Begriffen und Konzepten, die künstliche Intelligenz und maschinelles Lernen definieren und die für Sie nützlich sein können. Hier finden Sie Begriffe, die in der Dokumentation zu Chrome häufig verwendet werden, insbesondere im Zusammenhang mit clientseitiger KI.
Clientseitige KI
Während die meisten KI-Funktionen im Web auf Servern ausgeführt werden, wird clientseitige KI im Browser des Nutzers ausgeführt und die Inferenz erfolgt auf dem Gerät des Nutzers. Das hat zahlreiche Vorteile, darunter eine geringere Latenz, geringere Kosten für die Entwicklung von Funktionen, ein verbesserter Datenschutz und Offlinezugriff.
Clientseitige KI basiert auf kleineren, optimierten Modellen, die auf Leistung optimiert sind. Es ist möglich, dass solche Modelle bei bestimmten Aufgaben leistungsfähiger sind als größere serverseitige Modelle. Bewerten Sie Ihren Anwendungsfall, um zu ermitteln, welche Lösung für Sie geeignet ist.
Integrierte KI-Funktionen
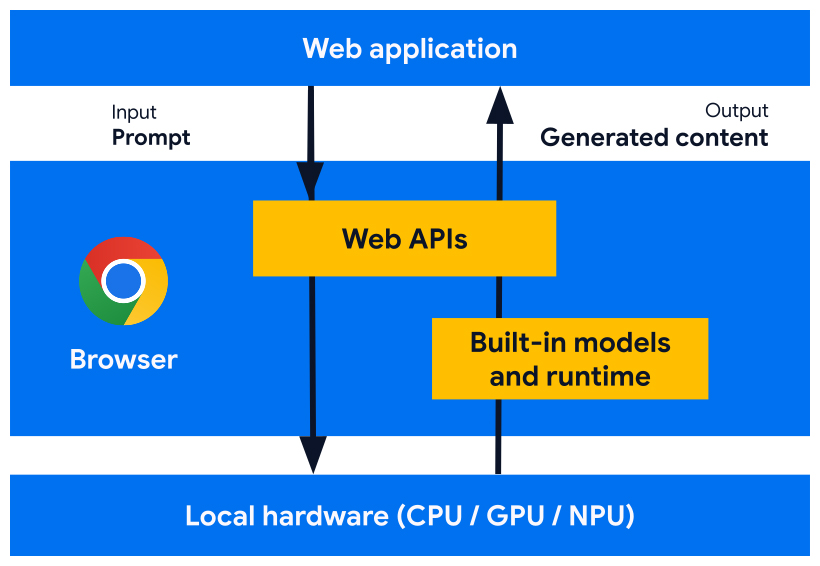
Integrierte KI ist eine Form der clientseitigen KI, bei der die kleineren Modelle in den Browser integriert sind. Für Chrome umfasst dies Gemini Nano und Expertenmodelle. Sobald diese Modelle heruntergeladen wurden, können alle Websites und Webanwendungen, die integrierte KI verwenden, die Downloadzeit überspringen und direkt mit der Ausführung von Funktionen und der lokalen Inferenz beginnen.
Die integrierten KI-APIs sind so konzipiert, dass sie Inferenz für den richtigen Modelltyp für die Aufgabe ausführen. Die Prompt API führt beispielsweise Inferenz für ein Sprachmodell aus, während die Translator API Inferenz für ein integriertes Expertenmodell ausführt.
Serverseitige KI
Serverseitige KI umfasst cloudbasierte KI-Dienste. Stellen Sie sich Gemini 1.5 Pro in der Cloud vor. Diese Modelle sind in der Regel viel größer und leistungsfähiger. Das gilt insbesondere für Large Language Models.
Hybride KI
Hybride KI bezieht sich auf jede Lösung, die sowohl eine Client- als auch eine Serverkomponente umfasst. Beispiel:
- Clientseitige Modelle mit Fallback auf serverseitige Modelle, die für Aufgaben entwickelt wurden, die auf dem Gerät nicht effektiv ausgeführt werden können.
- Möglicherweise sind nicht genügend Ressourcen auf dem Gerät vorhanden.
- Das Modell oder die API ist nur in bestimmten Umgebungen verfügbar.
- Ein Modell, das aus Sicherheitsgründen zwischen Client und Server aufgeteilt wird.
- Sie können ein Modell beispielsweise so aufteilen, dass 75% der Ausführung auf dem Client und die restlichen 25% auf einem Server erfolgen. Das bietet Vorteile auf Clientseite, während ein Teil des Modells auf dem Gerät verbleibt und somit privat bleibt.
Wenn Sie die Prompt API verwenden, können Sie eine Hybridarchitektur mit Firebase AI Logic einrichten.
Generative KI
Generative KI ist eine Form des maschinellen Lernens, die Nutzern hilft, Inhalte zu erstellen, die sich vertraut anfühlen und menschliche Kreativität nachahmen. Bei generativer KI werden Sprachmodelle verwendet, um Daten zu organisieren und Text, Bilder, Videos und Audioinhalte basierend auf dem bereitgestellten Kontext zu erstellen oder zu ändern. Generative KI geht über Mustervergleich und Vorhersagen hinaus.
Ein Large Language Model (LLM) hat zahlreiche (bis zu Milliarden) Parameter, mit denen Sie eine Vielzahl von Aufgaben ausführen können, z. B. das Generieren, Klassifizieren oder Zusammenfassen von Text oder Bildern.
Ein Small Language Model (SLM) hat deutlich weniger Parameter für ähnliche Aufgaben und kann möglicherweise clientseitig verwendet werden.
Natural Language Processing (NLP)
Natural Language Processing (NLP) ist eine Klasse von ML, die sich darauf konzentriert, Computern zu helfen, die menschliche Sprache zu verstehen – von den Regeln einer bestimmten Sprache bis hin zu den Eigenheiten, dem Dialekt und dem Slang, die von Einzelpersonen verwendet werden.
Agent oder KI-Agent
Ein Agent ist eine Software, die autonom eine Reihe von Aktionen plant und ausführt, um eine Aufgabe im Namen eines Nutzers zu erledigen, und sich dabei an Änderungen in ihrer Umgebung anpasst. Aktionen können API-Funktionen oder Datenbankabfragen umfassen, die auf einer Webseite oder über eine Drittanbieteranwendung wie Project Mariner ausgeführt werden.
Ein Chatbot ist nicht automatisch ein Agent. Während ein Chatbot auf einen Messenger (ob Mensch oder nicht) reagiert und sich auf ein Modell verlässt, um Inhalte wie Antworten auf Fragen zu generieren, interagiert ein Agent mit Tools oder einer Datenbank, um eine Aufgabe zu erledigen.
Eingabe und Ausgabe
Die Eingabe und Ausgabe des Modells können in verschiedenen Modalitäten erfolgen, darunter Text, Bild, Audio und Video. Ein Modell kann nur eine Modalität oder mehrere (multimodale Modelle) akzeptieren. Es ist wichtig, dass Sie bestätigen, welche Modalitäten Sie benötigen, bevor Sie Ihr Modell auswählen.
Ein- und Ausgaben können in Streaming-Chunks oder anfragebasiert gesendet und empfangen werden.
Streaming
Beim Streaming wird eine gesendete oder empfangene Ressource in kleinere Blöcke aufgeteilt, sodass Ergebnisse in Echtzeit verfügbar sind. Die Ausgabe wird fortlaufend angepasst, wenn Eingaben hinzugefügt und geändert werden.
Dies ist eine gängige Technik, die Browser beim Empfang von Media-Assets wie Videopufferung oder teilweises Laden von Bildern verwenden.
Anfragebasierte Ausgabe
Bei anfragebasierter Ausgabe (oder „Nicht-Streaming“) wartet das Modell, bis die gesamte Eingabe generiert wurde, verarbeitet diese Eingabe als Ganzes und gibt dann die Ausgabe aus.
In einem Chatfenster wartet das Modell beispielsweise, bis der Nutzer auf eine Schaltfläche zum Senden klickt, anstatt eine Antwort zu erstellen, während der Nutzer tippt. Sobald die Nachricht gesendet wurde, berücksichtigt das Modell alle Eingaben und antwortet dann.
Zusätzliche Ressourcen
Wenn Sie noch nicht mit KI im Web vertraut sind, sehen Sie sich unsere Sammlung von web.dev-KI-Ressourcen an.