

Compatibilidad con valores de punto flotante de 16 bits en WGSL
En WGSL, el tipo f16 es el conjunto de valores de punto flotante de 16 bits del formato IEEE-754 binary16 (precisión media). Esto significa que usa 16 bits para representar un número de punto flotante, en lugar de los 32 bits del punto flotante de precisión simple convencional (f32). Este tamaño más pequeño puede generar mejoras significativas en el rendimiento, en especial cuando se procesan grandes cantidades de datos.
A modo de comparación, en un dispositivo Apple M1 Pro, la implementación de f16 de los modelos Llama2 7B que se usan en la demostración de chat de WebLLM es significativamente más rápida que la implementación de f32, con una mejora del 28% en la velocidad de prellenado y una mejora del 41% en la velocidad de decodificación, como se muestra en las siguientes capturas de pantalla.
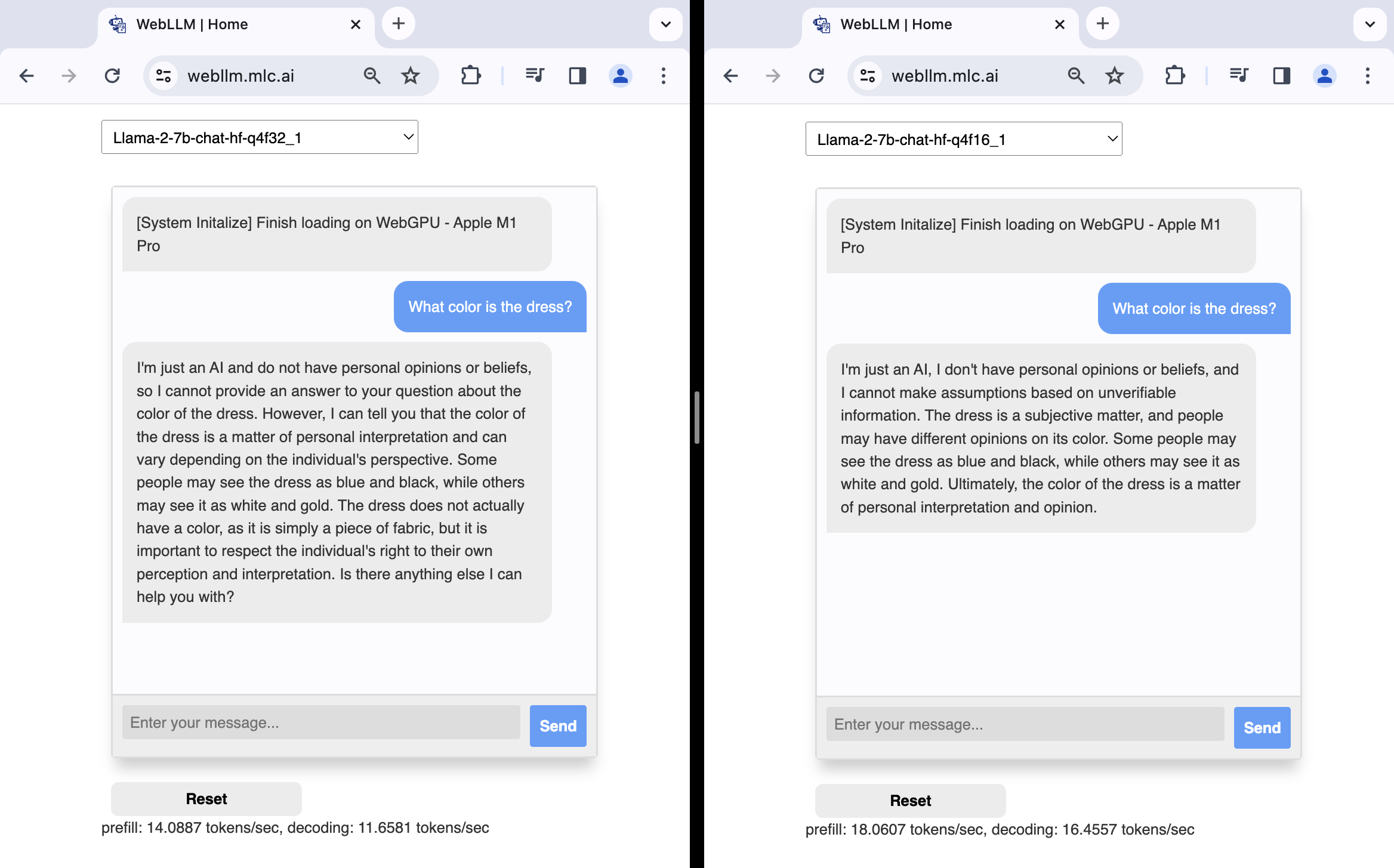
f32 (izquierda) y f16 (derecha) de Llama2 7B.No todas las GPUs admiten valores de punto flotante de 16 bits. Cuando la función "shader-f16" está disponible en un GPUAdapter, ahora puedes solicitar un GPUDevice con esta función y crear un módulo de sombreador WGSL que aproveche el tipo de punto flotante de media precisión f16. Este tipo solo es válido para usar en el módulo de sombreador WGSL si habilitas la extensión f16 de WGSL con enable f16;. De lo contrario, createShaderModule() generará un error de validación. Consulta el siguiente ejemplo mínimo y el problema dawn:1510.
const adapter = await navigator.gpu.requestAdapter();
if (!adapter.features.has("shader-f16")) {
throw new Error("16-bit floating-point value support is not available");
}
// Explicitly request 16-bit floating-point value support.
const device = await adapter.requestDevice({
requiredFeatures: ["shader-f16"],
});
const code = `
enable f16;
@compute @workgroup_size(1)
fn main() {
const c : vec3h = vec3<f16>(1.0h, 2.0h, 3.0h);
}
`;
const shaderModule = device.createShaderModule({ code });
// Create a compute pipeline with this shader module
// and run the shader on the GPU...
Es posible admitir los tipos f16 y f32 en el código del módulo de sombreador WGSL con un alias según la compatibilidad con la función "shader-f16", como se muestra en el siguiente fragmento.
const adapter = await navigator.gpu.requestAdapter();
const hasShaderF16 = adapter.features.has("shader-f16");
const device = await adapter.requestDevice({
requiredFeatures: hasShaderF16 ? ["shader-f16"] : [],
});
const header = hasShaderF16
? `enable f16;
alias min16float = f16;`
: `alias min16float = f32;`;
const code = `
${header}
@compute @workgroup_size(1)
fn main() {
const c = vec3<min16float>(1.0, 2.0, 3.0);
}
`;
Supera los límites
La cantidad máxima de bytes necesarios para almacenar una muestra (píxel o subpíxel) de los datos de salida de la canalización de renderización, en todos los archivos adjuntos de color, es de 32 bytes de forma predeterminada. Ahora es posible solicitar hasta 64 con el límite de maxColorAttachmentBytesPerSample. Consulta el siguiente ejemplo y el problema dawn:2036.
const adapter = await navigator.gpu.requestAdapter();
if (adapter.limits.maxColorAttachmentBytesPerSample < 64) {
// When the desired limit isn't supported, take action to either fall back to
// a code path that does not require the higher limit or notify the user that
// their device does not meet minimum requirements.
}
// Request highest limit of max color attachments bytes per sample.
const device = await adapter.requestDevice({
requiredLimits: { maxColorAttachmentBytesPerSample: 64 },
});
Se aumentaron los límites de maxInterStageShaderVariables y maxInterStageShaderComponents que se usan para la comunicación entre etapas en todas las plataformas. Consulta el problema dawn:1448 para obtener más detalles.
Para cada etapa del sombreador, la cantidad máxima de entradas de diseño de grupos de vinculación en un diseño de canalización que son búferes de almacenamiento es de 8 de forma predeterminada. Ahora es posible solicitar hasta 10 con el límite de maxStorageBuffersPerShaderStage. Consulta el problema dawn:2159.
Se agregó un nuevo límite de maxBindGroupsPlusVertexBuffers. Consiste en la cantidad máxima de ranuras de búfer de vértices y grupos de vinculación que se usan de forma simultánea, y se cuentan las ranuras vacías por debajo del índice más alto. Su valor predeterminado es 24. Consulta el problema dawn:1849.
Cambios en el estado de profundidad y stencil
Para mejorar la experiencia del desarrollador, ya no siempre se requieren los atributos de estado de profundidad y estencil depthWriteEnabled y depthCompare: depthWriteEnabled solo se requiere para los formatos con profundidad, y depthCompare no se requiere para los formatos con profundidad si no se usa en absoluto. Consulta el problema dawn:2132.
Actualizaciones de la información del adaptador
Los atributos de información del adaptador type y backend no estándares ahora están disponibles cuando se llama a requestAdapterInfo() si el usuario habilitó la marca "Funciones para desarrolladores de WebGPU" en chrome://flags/#enable-webgpu-developer-features. El type puede ser "GPU discreta", "GPU integrada", "CPU" o "desconocido". El backend puede ser "WebGPU", "D3D11", "D3D12", "metal", "vulkan", "openGL", "openGLES" o "null". Consulta los problemas dawn:2112 y dawn:2107.
Se quitó el parámetro de lista unmaskHints opcional en requestAdapterInfo(). Consulta el problema dawn:1427.
Cuantificación de consultas de marcas de tiempo
Las consultas de marcas de tiempo permiten que las aplicaciones midan el tiempo de ejecución de los comandos de la GPU con una precisión de nanosegundos. Sin embargo, la especificación de WebGPU hace que las consultas de marcas de tiempo sean opcionales debido a las preocupaciones sobre los ataques de sincronización. El equipo de Chrome cree que la cuantificación de las consultas de marcas de tiempo proporciona un buen equilibrio entre precisión y seguridad, ya que reduce la resolución a 100 microsegundos. Consulta el problema dawn:1800.
En Chrome, los usuarios pueden inhabilitar la cuantificación de marcas de tiempo habilitando la marca "WebGPU Developer Features" en chrome://flags/#enable-webgpu-developer-features. Ten en cuenta que esta marca por sí sola no habilita la función "timestamp-query". Su implementación aún es experimental y, por lo tanto, requiere la marca "Unsafe WebGPU Support" en chrome://flags/#enable-unsafe-webgpu.
En Dawn, se agregó un nuevo interruptor de dispositivo llamado "timestamp_quantization", que está habilitado de forma predeterminada. En el siguiente fragmento, se muestra cómo permitir la función experimental "timestamp-query" sin cuantificación de marcas de tiempo cuando se solicita un dispositivo.
wgpu::DawnTogglesDescriptor deviceTogglesDesc = {};
const char* allowUnsafeApisToggle = "allow_unsafe_apis";
deviceTogglesDesc.enabledToggles = &allowUnsafeApisToggle;
deviceTogglesDesc.enabledToggleCount = 1;
const char* timestampQuantizationToggle = "timestamp_quantization";
deviceTogglesDesc.disabledToggles = ×tampQuantizationToggle;
deviceTogglesDesc.disabledToggleCount = 1;
wgpu::DeviceDescriptor desc = {.nextInChain = &deviceTogglesDesc};
// Request a device with no timestamp quantization.
myAdapter.RequestDevice(&desc, myCallback, myUserData);
Funciones de limpieza de primavera
Se cambió el nombre de la función experimental "timestamp-query-inside-passes" a "chromium-experimental-timestamp-query-inside-passes" para que los desarrolladores sepan que esta función es experimental y, por el momento, solo está disponible en los navegadores basados en Chromium. Consulta el problema dawn:1193.
Se quitó la función experimental "pipeline-statistics-query", que solo se implementó parcialmente, porque ya no se está desarrollando. Consulta el problema chromium:1177506.
Esto solo abarca algunos de los aspectos destacados clave. Consulta la lista exhaustiva de confirmaciones.
Novedades de WebGPU
Una lista de todo lo que se abordó en la serie Novedades de WebGPU
Chrome 149-150
Chrome 147-148
Chrome 146
- Se agregó compatibilidad con el modo de compatibilidad de WebGPU en OpenGL ES 3.1
- Adjuntos transitorios
- Extensión texture_and_sampler_let de WGSL
- Actualizaciones de Dawn
Chrome 145
- Extensión subgroup_uniformity de WGSL
- Asignación de búfer síncrono experimental en trabajadores
- Actualizaciones de Dawn
Chrome 144
- Extensión subgroup_id de WGSL
- Extensión uniform_buffer_standard_layout de WGSL
- WebGPU en Linux
- writeBuffer y writeTexture más rápidos
- Actualizaciones de Dawn
Chrome 143
- Combinación de componentes de textura
- Quita el uso de texturas de almacenamiento de solo lectura bgra8unorm
- Actualizaciones de Dawn
Chrome 142
- Se extendieron las capacidades de compatibilidad con formatos de texturas
- Índice de primitivas en WGSL
- Actualizaciones de Dawn
Chrome 141
- Se completó la IR de Tint
- Análisis de rango de números enteros en el compilador de WGSL
- Actualización de SPIR-V 1.4 para el backend de Vulkan
- Actualizaciones de Dawn
Chrome 140
- Las solicitudes de dispositivos consumen el adaptador
- Abreviatura para usar la textura donde se usa la vista de textura
- textureSampleLevel de WGSL admite texturas 1D
- Se da de baja el uso de texturas de almacenamiento de solo lectura bgra8unorm
- Se quitó el atributo isFallbackAdapter de GPUAdapter
- Actualizaciones de Dawn
Chrome 139
- Compatibilidad con texturas 3D para formatos comprimidos BC y ASTC
- Nueva función "core-features-and-limits"
- Prueba de origen para el modo de compatibilidad de WebGPU
- Actualizaciones de Dawn
Chrome 138
- Abreviatura para usar el búfer como recurso de vinculación
- Cambios en los requisitos de tamaño para los búferes asignados en la creación
- Informe de arquitectura para las GPUs recientes
- Se dejó de usar el atributo isFallbackAdapter de GPUAdapter
- Actualizaciones de Dawn
Chrome 137
- Usa la vista de textura para la vinculación de externalTexture
- Los búferes se copian sin especificar desplazamientos ni tamaño
- WGSL workgroupUniformLoad con puntero a atómico
- Atributo powerPreference de GPUAdapterInfo
- Se quitó el atributo compatibilityMode de GPURequestAdapterOptions
- Actualizaciones de Dawn
Chrome 136
- Atributo isFallbackAdapter de GPUAdapterInfo
- Mejoras en el tiempo de compilación de sombreadores en D3D12
- Cómo guardar y copiar imágenes de lienzos
- Restricciones del modo de compatibilidad de la efectividad
- Actualizaciones de Dawn
Chrome 135
- Permite crear un diseño de canalización con un diseño de grupo de vinculación nulo
- Permite que los puertos de visualización se extiendan más allá de los límites de los objetivos de renderización
- Acceso más fácil al modo de compatibilidad experimental en Android
- Se quitó el límite de maxInterStageShaderComponents
- Actualizaciones de Dawn
Chrome 134
- Mejora las cargas de trabajo de aprendizaje automático con subgrupos
- Se quitó la compatibilidad con tipos de texturas filtrables de coma flotante como combinables
- Actualizaciones de Dawn
Chrome 133
- Formatos de vértices adicionales de unorm8x4-bgra y de 1 componente
- Permitir que se soliciten límites desconocidos con un valor indefinido
- Cambios en las reglas de alineación de WGSL
- Mejoras en el rendimiento de WGSL con descarte
- Usa VideoFrame.displaySize para texturas externas
- Cómo controlar imágenes con orientaciones no predeterminadas con copyExternalImageToTexture
- Mejora de la experiencia de los desarrolladores
- Habilita el modo de compatibilidad con featureLevel
- Limpieza de las funciones de subgrupos experimentales
- Se baja el límite de maxInterStageShaderComponents
- Actualizaciones de Dawn
Chrome 132
- Uso de la vista de textura
- Combinación de texturas de punto flotante de 32 bits
- Atributo adapterInfo de GPUDevice
- Configurar el contexto del lienzo con un formato no válido arroja un error de JavaScript
- Restricciones del muestreador de filtrado en texturas
- Experimentación con subgrupos extendidos
- Mejora de la experiencia de los desarrolladores
- Compatibilidad experimental con formatos de texturas normalizados de 16 bits
- Actualizaciones de Dawn
Chrome 131
- Distancias de recorte en WGSL
- GPUCanvasContext getConfiguration()
- Las primitivas de puntos y líneas no deben tener sesgo de profundidad
- Funciones integradas de análisis inclusivo para subgrupos
- Compatibilidad experimental con multi-draw indirect
- Opción de compilación del módulo de sombreador strict math
- Se quitó requestAdapterInfo() de GPUAdapter
- Actualizaciones de Dawn
Chrome 130
- Combinación de dos fuentes
- Mejoras en el tiempo de compilación de sombreadores en Metal
- Obsolescencia de requestAdapterInfo() de GPUAdapter
- Actualizaciones de Dawn
Chrome 129
- Compatibilidad con HDR con el modo de asignación de tono de Canvas
- Compatibilidad ampliada con subgrupos
- Actualizaciones de Dawn
Chrome 128
- Experimentación con subgrupos
- Se dejó de admitir el parámetro de configuración del sesgo de profundidad para líneas y puntos
- Oculta la advertencia de Herramientas para desarrolladores sobre errores no detectados si se usa preventDefault
- WGSL interpola el muestreo primero y
- Actualizaciones de Dawn
Chrome 127
- Compatibilidad experimental con OpenGL ES en Android
- Atributo info de GPUAdapter
- Mejoras en la interoperabilidad de WebAssembly
- Se mejoraron los errores del codificador de comandos
- Actualizaciones de Dawn
Chrome 126
- Aumenta el límite de maxTextureArrayLayers
- Optimización de la carga de búferes para el backend de Vulkan
- Mejoras en el tiempo de compilación de sombreadores
- Los búferes de comandos enviados deben ser únicos
- Actualizaciones de Dawn
Chrome 125
Chrome 124
- Texturas de almacenamiento de solo lectura y lectura/escritura
- Compatibilidad con service workers y shared workers
- Nuevos atributos de información del adaptador
- Correcciones de errores
- Actualizaciones de Dawn
Chrome 123
- Compatibilidad con funciones integradas de DP4a en WGSL
- Parámetros de puntero sin restricciones en WGSL
- Sintaxis edulcorada para la desreferenciación de compuestos en WGSL
- Estado de solo lectura independiente para los aspectos de profundidad y estarcido
- Actualizaciones de Dawn
Chrome 122
- Amplía el alcance con el modo de compatibilidad (función en desarrollo)
- Aumenta el límite de maxVertexAttributes
- Actualizaciones de Dawn
Chrome 121
- Compatibilidad con WebGPU en Android
- Usa DXC en lugar de FXC para la compilación de sombreadores en Windows
- Consultas de marcas de tiempo en pases de procesamiento y cómputos
- Puntos de entrada predeterminados a los módulos de sombreadores
- Admite display-p3 como espacio de color GPUExternalTexture
- Información de montones de memoria
- Actualizaciones de Dawn
Chrome 120
- Compatibilidad con valores de punto flotante de 16 bits en WGSL
- Desafía los límites
- Cambios en el estado de profundidad y stencil
- Actualizaciones de la información del adaptador
- Cuantificación de consultas de marca de tiempo
- Funciones de limpieza de primavera
Chrome 119
- Texturas de punto flotante de 32 bits filtrables
- Formato de vértice unorm10-10-10-2
- Formato de textura rgb10a2uint
- Actualizaciones de Dawn
Chrome 118
- Compatibilidad con HTMLImageElement y ImageData en
copyExternalImageToTexture() - Compatibilidad experimental con texturas de almacenamiento de lectura y escritura y de solo lectura
- Actualizaciones de Dawn
Chrome 117
- Anula la configuración del búfer de vértices
- Anula la configuración del grupo de vinculaciones
- Silencia los errores de la creación de canalizaciones asíncronas cuando se pierde el dispositivo
- Actualizaciones en la creación de módulos de sombreadores SPIR-V
- Mejora de la experiencia de los desarrolladores
- Canalizaciones de almacenamiento en caché con diseño generado automáticamente
- Actualizaciones de Dawn
Chrome 116
- Integración de WebCodecs
- Se devolvió el dispositivo perdido por GPUAdapter
requestDevice() - Mantener la reproducción de video fluida si se llama a
importExternalTexture() - Cumplimiento de las especificaciones
- Mejora de la experiencia de los desarrolladores
- Actualizaciones de Dawn
Chrome 115
- Extensiones de lenguaje de WGSL admitidas
- Compatibilidad experimental con Direct3D 11
- Obtén una GPU discreta de forma predeterminada con alimentación de CA
- Mejora de la experiencia de los desarrolladores
- Actualizaciones de Dawn
Chrome 114
- Optimiza JavaScript
- getCurrentTexture() en un lienzo sin configurar arroja InvalidStateError
- Actualizaciones de WGSL
- Actualizaciones de Dawn