
AI テスト パイプラインを構築するための応用エンジニアリングのヒント。

ルーブリックを設計し、ルールベースの評価を作成し、ジャッジモデルを調整しました。次に、これらすべてを自動化された継続的テスト パイプラインに接続します。
プロジェクトはそれぞれ異なります。このモジュールでは、評価パイプラインを構築するための効果的な階層型アプローチの概要を説明します。
評価パイプラインを構築するには、次のものが必要です。
- エバリュエータのオーケストレーター
- 複数の API 呼び出しを処理し、潜在的な障害に対処する戦略
- 標準化された出力形式
- レポート インターフェース
API 呼び出しをオーケストレートする

ルールベースの評価ツールと LLM 判定評価ツールをオーケストレートするメイン関数を作成します。コード例の evalAll() を確認します。
LLM ジャッジの構成(システム指示、構造化出力ロジック、再試行)を、評価ツール全体で再利用できる単一のユーティリティ関数に一元化します。コード例の evalWithLLM() を確認します。
モデル API のオーバーロードと障害を処理する
モデル API が過負荷になったり、タイムアウトになったりすることがあります。API 呼び出しが失敗した場合は、自動再試行をトリガーします。再試行がなくなったら、ERROR を報告します。eval FAIL を報告すると、結果が歪みます。
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
評価を実行する際は、次のオプションから選択します。
- API 呼び出しを並行して行い、1 つの eval のタイムアウトが他の eval をクラッシュさせないようにします。ユースケースと判定モデルによっては、判定が 1 つのタスクに集中するため、ハルシネーションを減らすことができます。
- 単一のバッチ呼び出しを行います。これにより、モデルがトークン上限を超えた場合など、単一障害点が生じます。
複数のイテレーションに備える
LLM は非決定的であるため、アプリケーションの出力は異なります。
これを正確にテストし、出力が品質基準を満たしているという確信を得るには:
- 単一のテストケース入力ごとに複数の出力(通常は 5 ~ 10 個)を生成します。
- 各出力を個別に評価します。
- 手直し全体の成果を確認します。
実用的なバランスを見つける: イテレーションを増やすと回帰の確実性が高まりますが、イテレーションを減らすと、継続的テスト パイプラインにシームレスに適合するほど実行が高速になります。
評価パイプラインの出力を定義する
評価結果には次の情報を含めます。
- 安定率(例: 10 回中 8 回合格 → 安定率 80%)。機能を本番環境で使用できる状態になったタイミングを測定するためのしきい値を設定します。
- アプリケーション構成。これには、システム指示、ユーザー プロンプト、Temperature や思考レベルなどの LLM パラメータが含まれます。この情報は、評価スコアの回帰のトラブルシューティングに必要です。プロンプトはわずかなバリエーションを含む長い文字列になる可能性があるため、プロンプトにバージョン番号を追加し、そのハッシュを保存して追跡します。
- 判定構成またはバージョン番号。これは、審査員の更新後にスコアが大きく変動した場合に必要になります。
ThemeBuilder の評価用の EvalResponse JSON オブジェクトの例を次に示します。
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
レポート インターフェースを実装する
結果を HTML レポートまたはクリーンなウェブ UI に出力して、結果を解析、共有、比較し、デバッグします。
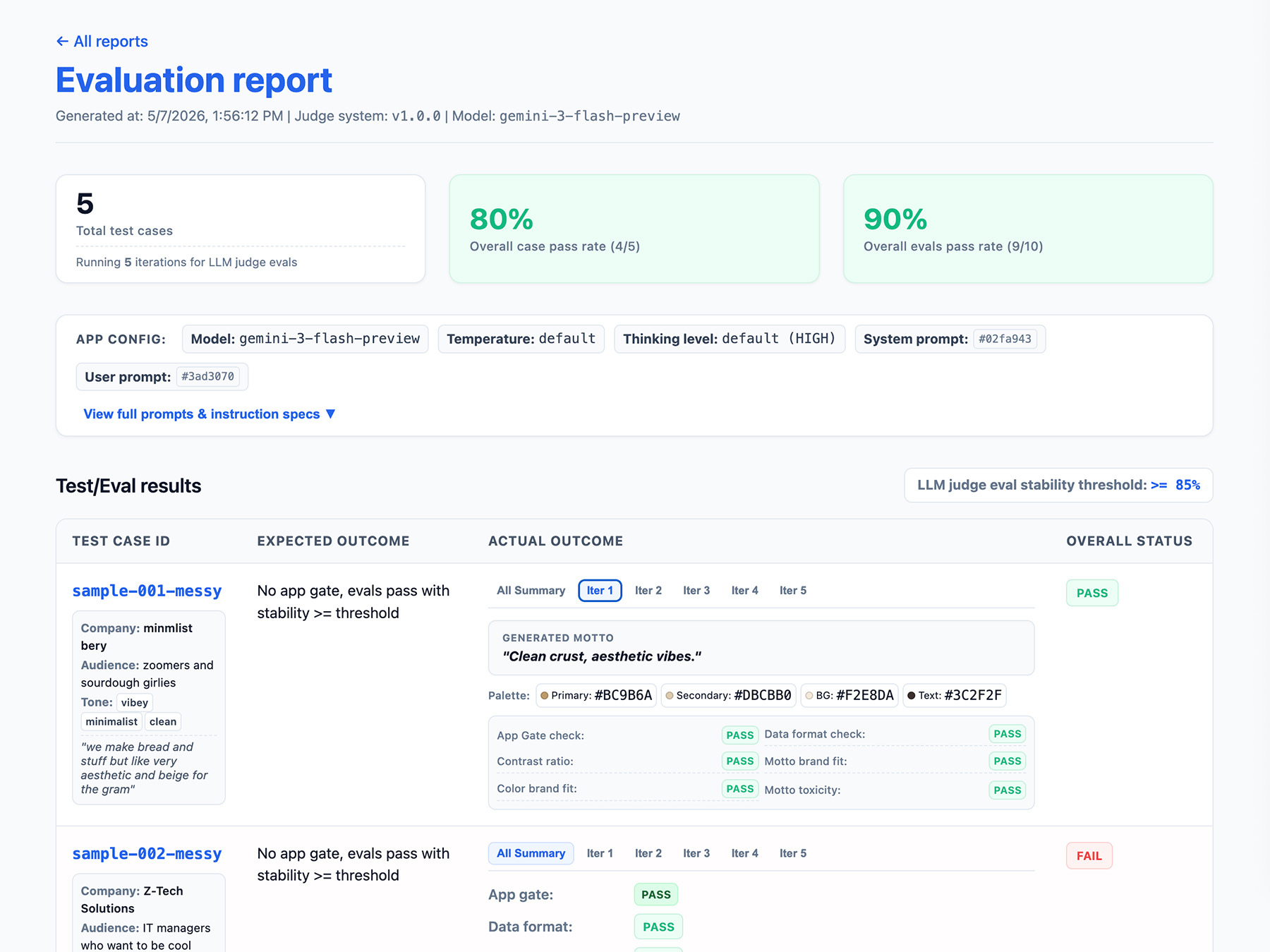

次に、評価を実行します。