
手書き入力認識 API を使用すると、手書き入力のテキストをリアルタイムで認識できます。


Handwriting Recognition API とは
Handwriting Recognition API を使用すると、ユーザーの手書き文字(インク)をテキストに変換できます。一部のオペレーティング システムには、このような API が以前から含まれており、この新機能により、ウェブアプリでこの機能をようやく使用できるようになりました。変換はユーザーのデバイス上で直接行われ、オフライン モードでも動作します。サードパーティのライブラリやサービスを追加する必要はありません。
この API は、いわゆる「オンライン」または準リアルタイムの認識を実装します。つまり、ユーザーが手書き入力している間、ストロークをキャプチャして分析することで、手書き入力が認識されます。光学式文字認識(OCR)などの「オフライン」の手順では最終的な結果しかわかりませんが、オンライン アルゴリズムでは、個々のインク ストロークの時間順序や圧力などの追加のシグナルにより、精度を高めることができます。
手書き文字認識 API のユースケースの例
使用例:
- 手書きのメモをキャプチャしてテキストに変換したいユーザー向けのメモアプリ。
- 時間制限があるため、ユーザーがタッチペンや指で入力できるフォーム アプリケーション。
- クロスワード、ハングマン、数独など、文字や数字を埋める必要があるゲーム。
現在のステータス
Handwriting Recognition API は(Chromium 99)から利用できます。
手書き認識 API の使用方法
特徴検出
navigator オブジェクトに createHandwritingRecognizer() メソッドが存在するかどうかをチェックして、ブラウザのサポートを検出します。
if ('createHandwritingRecognizer' in navigator) {
// 🎉 The Handwriting Recognition API is supported!
}
基本コンセプト
手書き入力認識 API は、入力方法(マウス、タッチ、タッチペン)に関係なく、手書き入力をテキストに変換します。この API には、次の 4 つの主要なエンティティがあります。
- ポイントは、特定の時点でのポインタの位置を表します。
- ストロークは 1 つ以上のポイントで構成されます。ストロークの記録は、ユーザーがポインタを置いたとき(つまり、マウスの主ボタンをクリックしたとき、またはスタイラスや指で画面に触れたとき)に始まり、ポインタを再び上げたときに終わります。
- 図形は 1 つ以上のストロークで構成されます。実際の認識はこのレベルで行われます。
- 認識ツールは、想定される入力言語で構成されています。認識ツールの構成が適用された描画のインスタンスを作成するために使用されます。
これらのコンセプトは、特定のインターフェースと辞書として実装されています。これについては、後ほど説明します。

認識ツールを作成する
手書き入力からテキストを認識するには、navigator.createHandwritingRecognizer() を呼び出して HandwritingRecognizer のインスタンスを取得し、制約を渡す必要があります。制約によって、使用する手書き認識モデルが決定されます。現在、優先順位の高い順に言語のリストを指定できます。
const recognizer = await navigator.createHandwritingRecognizer({
languages: ['en'],
});
ブラウザがリクエストを満たせる場合、このメソッドは HandwritingRecognizer のインスタンスで解決される Promise を返します。それ以外の場合は、エラーで Promise を拒否し、手書き文字認識は利用できません。そのため、まず特定の認識機能に対する認識機能のサポートをクエリすることをおすすめします。
認識ツールのサポートをクエリする
navigator.queryHandwritingRecognizer() を呼び出すことで、使用する手書き文字認識機能をターゲット プラットフォームがサポートしているかどうかを確認できます。このメソッドは、リクエストされた言語のリストを含む navigator.createHandwritingRecognizer() メソッドと同じ制約オブジェクトを受け取ります。互換性のある認識ツールが見つかった場合、このメソッドは結果オブジェクトで解決される Promise を返します。それ以外の場合、Promise は null に解決されます。次の例では、デベロッパーは次の処理を行います。
- 英語のテキストを検出したい
- 代替の可能性の低い予測を取得する(利用可能な場合)
- セグメンテーション結果(認識された文字、それらを構成する点とストロークを含む)にアクセスする
const result =
await navigator.queryHandwritingRecognizerSupport({
languages: ['en']
});
console.log(result?.textAlternatives); // true if alternatives are supported
console.log(result?.textSegmentation); // true if segmentation is supported
ブラウザがデベロッパーが必要とする機能をサポートしている場合、結果オブジェクトの値は true に設定されます。それ以外の場合は、false に設定されます。この情報を使用して、アプリケーション内の特定の機能を有効または無効にしたり、別の言語セットの新しいクエリを送信したりできます。
図形描画を開始する
アプリ内に、ユーザーが手書きで入力できる入力エリアを提供する必要があります。パフォーマンス上の理由から、キャンバス オブジェクトを使用して実装することをおすすめします。この部分の具体的な実装は、この記事の範囲外ですが、デモでその方法を確認できます。
新しい描画を開始するには、認識ツールで startDrawing() メソッドを呼び出します。このメソッドは、認識アルゴリズムを微調整するためのさまざまなヒントを含むオブジェクトを受け取ります。ヒントはすべて省略可能です。
- 入力されるテキストの種類: テキスト、メールアドレス、数字、または個々の文字(
recognitionType) - 入力デバイスのタイプ: マウス、タップ、タッチペン入力(
inputType) - 前のテキスト(
textContext) - 返される可能性の低い代替予測の数(
alternatives) - ユーザーが入力する可能性が高いユーザー識別可能な文字(「書記素」)のリスト(
graphemeSet)
手書き認識 API は、任意のポインティング デバイスからの入力を利用するための抽象インターフェースを提供する Pointer Events とうまく連携します。ポインタ イベントの引数には、使用されているポインタの種類が含まれています。つまり、ポインタ イベントを使用して入力タイプを自動的に判断できます。次の例では、手書き入力領域で pointerdown イベントが最初に発生したときに、手書き入力認識用の描画が自動的に作成されます。pointerType は空の場合や、独自の値を設定している場合があるため、描画の入力タイプにサポートされている値のみが設定されるように、一貫性チェックを導入しました。
let drawing;
let activeStroke;
canvas.addEventListener('pointerdown', (event) => {
if (!drawing) {
drawing = recognizer.startDrawing({
recognitionType: 'text', // email, number, per-character
inputType: ['mouse', 'touch', 'stylus'].find((type) => type === event.pointerType),
textContext: 'Hello, ',
alternatives: 2,
graphemeSet: ['f', 'i', 'z', 'b', 'u'], // for a fizz buzz entry form
});
}
startStroke(event);
});
ストロークを追加する
pointerdown イベントは、新しいストロークを開始するのに適した場所でもあります。そのためには、HandwritingStroke の新しいインスタンスを作成します。また、後続のポイントの基準点として、現在の時刻を保存する必要があります。
function startStroke(event) {
activeStroke = {
stroke: new HandwritingStroke(),
startTime: Date.now(),
};
addPoint(event);
}
Wifi 拡張ポイントを追加する
ストロークを作成したら、最初のポイントを直接追加する必要があります。後でポイントを追加するため、ポイント作成ロジックを別のメソッドに実装するのが妥当です。次の例では、addPoint() メソッドは参照タイムスタンプからの経過時間を計算します。時間情報は省略可能ですが、認識品質を向上させることができます。次に、ポインタ イベントから X 座標と Y 座標を読み取り、現在のストロークにポイントを追加します。
function addPoint(event) {
const timeElapsed = Date.now() - activeStroke.startTime;
activeStroke.stroke.addPoint({
x: event.offsetX,
y: event.offsetY,
t: timeElapsed,
});
}
ポインタが画面上を移動すると、pointermove イベント ハンドラが呼び出されます。これらのポイントはストロークにも追加する必要があります。ポインタが「ダウン」状態でない場合(マウスボタンを押さずに画面上でカーソルを移動する場合など)にも、イベントが発生することがあります。次の例のイベント ハンドラは、アクティブなストロークが存在するかどうかを確認し、新しいポイントをそのストロークに追加します。
canvas.addEventListener('pointermove', (event) => {
if (activeStroke) {
addPoint(event);
}
});
テキストを認識する
ユーザーがポインタを再び持ち上げると、addStroke() メソッドを呼び出して、ストロークを描画に追加できます。次の例では activeStroke もリセットされるため、pointermove ハンドラは完了したストロークにポイントを追加しません。
次に、描画の getPrediction() メソッドを呼び出して、ユーザーの入力を認識します。通常、認識には数百ミリ秒もかからないため、必要に応じて予測を繰り返し実行できます。次の例では、ストロークが完了するたびに新しい予測を実行します。
canvas.addEventListener('pointerup', async (event) => {
drawing.addStroke(activeStroke.stroke);
activeStroke = null;
const [mostLikelyPrediction, ...lessLikelyAlternatives] = await drawing.getPrediction();
if (mostLikelyPrediction) {
console.log(mostLikelyPrediction.text);
}
lessLikelyAlternatives?.forEach((alternative) => console.log(alternative.text));
});
このメソッドは、可能性の順に並べられた予測の配列で解決される Promise を返します。要素の数は、alternatives ヒントに渡した値によって異なります。この配列を使用して、ユーザーに一致候補の選択肢を提示し、オプションを選択させることができます。または、最も可能性の高い予測を使用することもできます。これは、この例で行っていることです。
予測オブジェクトには、認識されたテキストと、オプションのセグメンテーション結果が含まれます。これについては、次のセクションで説明します。
セグメンテーションの結果を含む詳細な分析情報
ターゲット プラットフォームでサポートされている場合、予測オブジェクトにセグメンテーション結果を含めることもできます。これは、認識されたすべての手書きセグメントを含む配列です。認識されたユーザー識別可能な文字(grapheme)とその認識されたテキスト内の位置(beginIndex、endIndex)、およびそれを作成したストロークとポイントの組み合わせです。
if (mostLikelyPrediction.segmentationResult) {
mostLikelyPrediction.segmentationResult.forEach(
({ grapheme, beginIndex, endIndex, drawingSegments }) => {
console.log(grapheme, beginIndex, endIndex);
drawingSegments.forEach(({ strokeIndex, beginPointIndex, endPointIndex }) => {
console.log(strokeIndex, beginPointIndex, endPointIndex);
});
},
);
}
この情報を使用して、キャンバス上で認識された書記素を再度追跡できます。
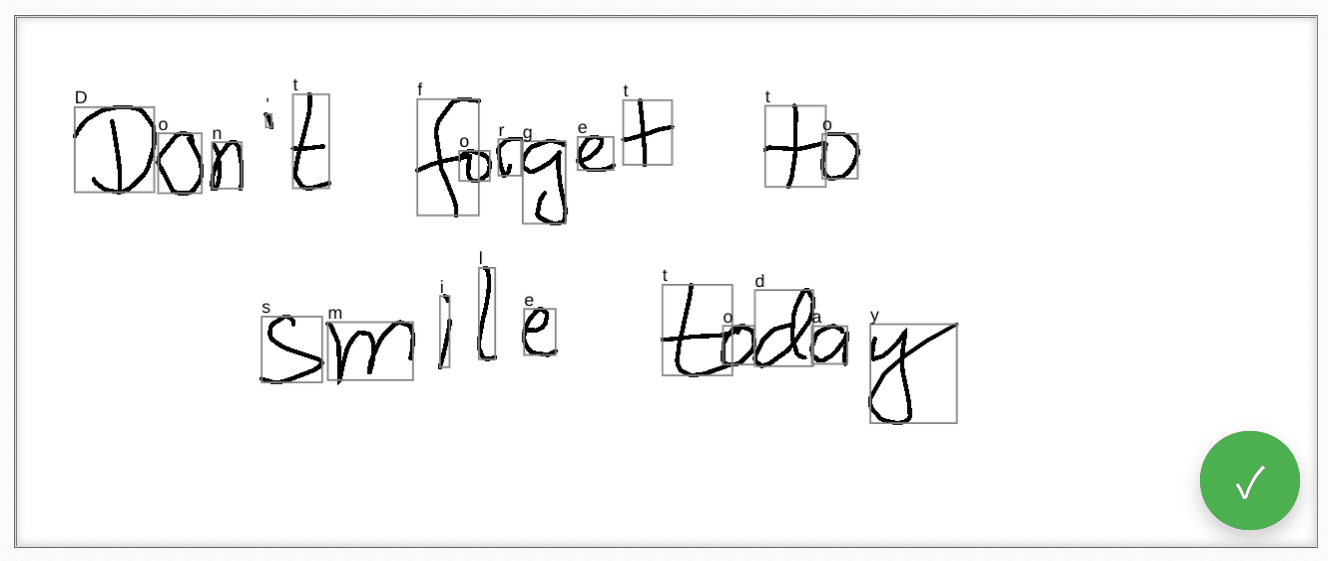
完全な認識
認識が完了したら、HandwritingDrawing の clear() メソッドと HandwritingRecognizer の finish() メソッドを呼び出して、リソースを解放できます。
drawing.clear();
recognizer.finish();
デモ
ウェブ コンポーネント <handwriting-textarea> は、段階的に強化された、手書き文字認識が可能な編集コントロールを実装します。編集コントロールの右下にあるボタンをクリックすると、描画モードが有効になります。描画が完了すると、ウェブ コンポーネントが自動的に認識を開始し、認識されたテキストを編集コントロールに追加します。手書き文字認識 API がまったくサポートされていない場合、またはプラットフォームがリクエストされた機能をサポートしていない場合、編集ボタンは非表示になります。ただし、基本的な編集コントロールは <textarea> として引き続き使用できます。
ウェブ コンポーネントは、languages や recognitiontype など、外部から認識動作を定義するためのプロパティと属性を提供します。コントロールのコンテンツは、value 属性で設定できます。
<handwriting-textarea languages="en" recognitiontype="text" value="Hello"></handwriting-textarea>
値の変更を通知するには、input イベントをリッスンします。
このコンポーネントは、GitHub のこちらのデモでお試しいただけます。ソースコードも必ずご覧ください。アプリケーションでコントロールを使用するには、npm から取得します。
セキュリティと権限
Chromium チームは、強力なウェブ プラットフォーム機能へのアクセスを制御するで定義されているユーザー制御、透明性、人間工学などの基本原則を使用して、手書き文字認識 API を設計、実装しました。
ユーザー コントロール
手書き入力認識 API はユーザーが無効にすることはできません。この API は、HTTPS 経由で配信されるウェブサイトでのみ使用でき、最上位のブラウジング コンテキストからのみ呼び出すことができます。
透明性
手書き文字認識が有効かどうかは表示されません。フィンガープリントを防止するため、ブラウザは、不正使用の可能性を検出したときにユーザーに権限プロンプトを表示するなどの対策を実装しています。
権限の永続性
現在、手書き文字認識 API では権限のプロンプトは表示されません。したがって、権限を永続化する必要はありません。
フィードバック
Chromium チームは、手書き認識 API の使用感について皆様のご意見をお待ちしています。
API 設計について教えてください
API が想定どおりに動作しない点はありますか?アイデアを実装するために必要なメソッドやプロパティが不足している場合はどうすればよいですか?セキュリティ モデルについてご質問やご意見がある場合は、対応する GitHub リポジトリで仕様に関する問題を報告するか、既存の問題に意見を追加します。
実装に関する問題を報告する
Chromium の実装でバグが見つかりましたか?それとも、実装が仕様と異なるのでしょうか?new.crbug.com でバグを報告します。できるだけ詳細な情報と、再現手順を記載し、[コンポーネント] ボックスに Blink>Handwriting と入力してください。
API のサポートを表示する
手書き認識 API を使用する予定はありますか?公開サポートは、Chromium チームが機能の優先順位を付け、他のブラウザ ベンダーにサポートの重要性を示すのに役立ちます。
WICG Discourse スレッドで、どのように使用する予定かを共有してください。ハッシュタグ #HandwritingRecognition を使用して @ChromiumDev にツイートし、どこでどのように使用しているかをお知らせください。
関連リンク
- 説明
- 仕様のドラフト
- GitHub リポジトリ
- ChromeStatus
- Chromium バグ
- TAG のレビュー
- プロトタイプを作成する目的
- WebKit-Dev スレッド
- Mozilla の標準規格への取り組み
謝辞
このドキュメントは、Joe Medley、Honglin Yu、Jiewei Qian によってレビューされました。