

Fecha de publicación: 30 de abril de 2026
Con la IA integrada, tu sitio web o aplicación web puede realizar tareas potenciadas por IA sin necesidad de implementar, administrar ni alojar modelos por tu cuenta. Es posible que te resulte difícil pasar de una demostración a una función lista para producción. En este documento, se abordan consideraciones técnicas y de UX para ayudarte a evitar errores comunes.
Prepara el modelo en un tiempo razonable
Se aplica a: todas las APIs, por ejemplo, Summarizer, Translator y Writer.
Haz lo siguiente: Inicializa la sesión en cuanto hayas establecido claramente la intención del usuario de usar la función de IA, por ejemplo, cuando un usuario navega a una superficie de herramientas de IA relevante, coloca el cursor sobre un espacio de trabajo de IA o interactúa con la IU circundante de la función. El precalentamiento de la sesión permite que el modelo se cargue en la memoria de forma silenciosa en segundo plano mientras el usuario configura su tarea, lo que elimina la latencia evitable de inicio en frío. Intenta adelantarte un paso iniciando la siguiente tarea de IA más probable en cuanto comiences a renderizar el resultado actual, por ejemplo, si la función está diseñada para un uso iterativo.
No hagas lo siguiente: A menos que sea necesario, no esperes a que el usuario haga clic en "Generar" para inicializar la sesión. Esto genera una demora de inicio en frío, ya que el modelo primero debe cargarse en la memoria y preparar su canalización de ejecución.
Configura las instrucciones iniciales durante la creación
Se aplica a: API de Prompt.
Haz lo siguiente: Proporciona instrucciones del sistema durante la inicialización de la sesión para mejorar la velocidad de la primera instrucción.
No hagas lo siguiente: No comiences con una sesión vacía y envíes instrucciones del sistema como parte de
la primera llamada a prompt(). Esto aumenta la latencia porque obliga al modelo a procesar esas instrucciones en el último momento.
// ✅ DO: Create the session as early as possible (tip on warming up the model early) and use initialPrompts for system instructions in the create call
const session = await LanguageModel.create({
initialPrompts: [
{ role: 'system', content: 'You are a helpful assistant specialized in code reviews.' }
]
});
// A few moments later, when the user triggers the AI feature
const review = await session.prompt(`Review the following code:\n\n${code}`);
// ❌ DON'T: Send instructions using prompt() after creation
// const slowerSession = await LanguageModel.create();
// await slowerSession.prompt(`You are a helpful assistant specialized in code reviews.\n\nReview the following code:\n\n${code}`); // Higher latency
Clona sesiones para tareas repetitivas
Se aplica a: API de Prompt.
En el caso de la API de Prompt, cada sesión realiza un seguimiento del contexto de la conversación, y tiene en cuenta todas las interacciones anteriores. Debido a que un clon hereda todo de su sesión superior, incluidas las instrucciones iniciales y todo el historial de interacciones hasta el punto de clonación, estructura tu uso para heredar solo lo que necesitas.
Haz lo siguiente:
- Crea una sesión base: Para controlar las tareas no relacionadas de manera eficiente, crea una sesión base que contenga solo las instrucciones del sistema y ningún contexto conversacional anterior.
- Clona la línea de base: Usa
clone()en esa sesión base para las tareas nuevas para guardar la sobrecarga de volver a analizar las instrucciones del sistema. Esto te permite crear conversaciones paralelas o restablecer una tarea a su línea de base.
No hagas lo siguiente:
- No reutilices la misma sesión para tareas no relacionadas y evita clonar cualquier sesión que ya contenga un historial de interacciones innecesario. Ambos patrones pueden hacer que el contexto anterior no relacionado interfiera con tu tarea actual.
- No llames a
create()repetidamente con instrucciones del sistema idénticas. En su lugar, usa el patrón de clonación para optimizar el rendimiento.
// ✅ DO: Create a baseline session and clone it for each new task
const baseSession = await LanguageModel.create({
initialPrompts: [{
role: 'system',
content: 'You are a technical editor...',
}],
});
// Clone the base session once for the first task
const task1 = await baseSession.clone();
const response1 = await task1.prompt("Review this first draft...");
// ... Repeat the cloning pattern for subsequent independent tasks
// Each task starts fresh from the baseline system instructions
// ❌ DON'T:
// Bad performance pattern: repeated create() calls for identical tasks.
// This forces the model to re-parse instructions every time, increasing latency.
// const sessionA = await LanguageModel.create({ initialPrompts: [...] });
// await sessionA.prompt("Task 1...");
// const sessionB = await LanguageModel.create({ initialPrompts: [...] });
// await sessionB.prompt("Task 2...");
// Bad quality pattern: reusing the same session for unrelated tasks.
// const session = await LanguageModel.create();
// await session.prompt("Analyze this financial report...");
// Unrelated task in the same session:
// await session.prompt("Now write a children's story...");
Destruye las sesiones no utilizadas
Se aplica a: todas las APIs.
Haz lo siguiente: Llama a destroy() de forma explícita en
las sesiones que ya no necesites para liberar memoria cuando una función
ya no esté en uso. Si usas un patrón de clonación, conserva la sesión base y destruye los clones que ya no necesites.
No hagas lo siguiente: No mantengas activas varias sesiones grandes. Cada sesión consume memoria, lo que crea un uso innecesario de recursos y podría convertirse en un problema. El recolector de elementos no utilizados limpiará las sesiones de forma natural, pero llamar a destroy() libera memoria más rápido.
// ✅ DO: Use the clone and destroy it immediately after
const clone = await baseSession.clone();
const response = await clone.prompt("Quick task...");
// Free memory right away: destry the clone, keep the baseSession
clone.destroy();
Renderiza respuestas de transmisión de forma segura y eficiente
Se aplica a: todas las APIs con compatibilidad con transmisión (Prompt, Summarizer, Writer, Rewriter y Translator).
Haz lo siguiente: Trata toda la salida de LLM como contenido no confiable. Sanea la salida combinada completa, no solo los fragmentos, ya que el código malicioso se puede dividir en varias actualizaciones. Antes de renderizar, usa la Sanitizer API cuando sea compatible. Para evitar una disminución en el rendimiento, usa un analizador de Markdown de transmisión como streaming-markdown.
No hagas lo siguiente: No configures innerHTML directamente en cada actualización de fragmento. Esto es lento, en especial con un formato complejo como el resaltado de sintaxis, y vulnerable a la inyección.
import * as smd from "streaming-markdown";
// Set up virtual buffer and Sanitizer API
const sanitizer = new Sanitizer({
allowElements: ['figure', 'figcaption', 'p', 'br', 'strong', 'em', 'img', 'a'],
allowAttributes: {
'loading': ['img'], 'decoding': ['img'], 'src': ['img'], 'href': ['a']
}
});
// Create an off-screen fragment so the parser doesn't cause flicker
// or trigger XSS in the live DOM during the building process.
const buffer = new DocumentFragment();
const parser = smd.parser_new(buffer);
// Use sanitizer as a gatekeeper / cleaner function so we can combine it with the streaming Markdown parser
function syncSanitized(target, sourceFragment) {
// .sanitize() returns a fresh, clean DocumentFragment
const cleanFragment = sanitizer.sanitize(sourceFragment);
// replaceChildren is the modern high-performance way to swap DOM content
target.replaceChildren(cleanFragment);
}
// Streaming Logic
// `chunks` keeps track of the raw string (useful for logs/debug)
chunks += chunk;
// Let the parser build the DOM incrementally in the buffer.
// This is high-performance because the buffer is not live
smd.parser_write(parser, chunk);
// Use the Sanitizer API to port the content safely to the container.
syncSanitized(container, buffer);
Optimiza la entrada para obtener velocidad
Se aplica a: todas las APIs.
Haz lo siguiente: Solo pasa al modelo lo que sea estrictamente necesario. Quita todo lo que no sea relevante para la tarea en cuestión. Para conjuntos de datos grandes, proporciona una descripción general breve y una pequeña selección de elementos relevantes.
No hagas lo siguiente: No envíes texto sin procesar, metadatos innecesarios, etiquetas HTML ni listas grandes sin filtrar a las APIs. La latencia aumenta significativamente con el tamaño de la entrada, lo que puede hacer que la función de IA parezca dañada en muchos dispositivos.
// ✅ DO: Send only relevant text
const cleanText = document.querySelector('#article').innerText;
const summary = await Summarizer.summarize(cleanText);
// ❌ DON'T: Send the entire DOM structure
// const dirtyText = document.querySelector('#article').innerHTML;
Usa una salida estructurada para obtener resultados predecibles
Se aplica a: API de Prompt.
Haz lo siguiente: Cuando necesites que el modelo muestre datos en un formato específico, usa
una salida estructurada
proporcionando un campo responseConstraint para proporcionar un esquema JSON. Esto garantiza que el resultado sea predecible y evita que necesites un procesamiento posterior complejo o un análisis manual.
No hagas lo siguiente: No te bases solo en instrucciones de lenguaje natural (como "solo salida JSON") solo. Los modelos pueden incluir un relleno conversacional que interrumpa tu analizador.
// ✅ DO: Use a JSON Schema for predictable results
const schema = {
type: "object",
properties: {
isTopicCats: { type: "boolean" }
}
};
const result = await session.prompt(`Is this post about cats?\n\n${post}`, {
responseConstraint: schema,
});
console.log(JSON.parse(result).isTopicCats);
Desvincula la generación de las restricciones de longitud
Se aplica a: API de Prompt, ya que es la única API que admite esquemas de salida estructurados.
Haz lo siguiente: Permite que el modelo genere su respuesta de forma natural y, luego, usa la lógica del cliente para truncar el texto y adaptarlo a tu IU.
No hagas lo siguiente: No apliques límites estrictos de caracteres como maxLength: 125 con
esquemas de salida estructurados. Cuando la respuesta de un modelo es más larga que el límite que estableces, el modelo puede cambiar a tokens de alta densidad, como idiomas extranjeros o emojis, para comprimir el significado, lo que genera una salida sin sentido.
/* DO: Handle overflow using CSS */
.result {
overflow: hidden;
white-space: nowrap;
text-overflow: ellipsis; /* Displays '…' */
}
// ❌ DON'T: Force length in the prompt
const result = await session.prompt("Write a bio in exactly 50 characters.");
Cómo mantener informado al usuario
Se aplica a: todas las APIs.
Haz lo siguiente: Según la complejidad y la duración esperada de la tarea, usa animaciones, indicadores visuales y de progreso para mantener informado al usuario. El enfoque óptimo depende de tu caso de uso y de la longitud esperada de la salida de la API. Estas son algunas ideas:
- Transmisión para contenido largo: En el caso de los resúmenes o el chat, la transmisión crea un efecto de máquina de escribir por token de forma predeterminada. Esto puede parecer natural y proporcionar comentarios inmediatos.
- Sin transmisión para tareas cortas (o tareas asíncronas largas): En el caso de las salidas cortas, por ejemplo, el texto alternativo, la transmisión puede crear una IU más refinada. También proporciona tiempo para preparar de forma especulativa la siguiente tarea de IA mientras se renderiza la actual. Este enfoque también funciona para tareas asíncronas o en segundo plano más largas. Si el usuario no está bloqueado en el resultado para continuar su recorrido, no es necesario producir el resultado de forma urgente a medida que sucede. Indica que el proceso está en curso en la IU.
- Transiciones visuales para actualizaciones: Cuando traduzcas o reescribas texto, usa animaciones, por ejemplo, la transformación de palabras.
No hagas lo siguiente: No actualices la IU sin indicadores visuales.
Alinea con el modelo mental del usuario sobre el tiempo y el trabajo
Se aplica a: todas las APIs.
Haz lo siguiente: Considera una demora artificial de uno o dos segundos si una respuesta es casi instantánea. Paradójicamente, los usuarios pueden encontrar resultados más confiables cuando perciben un proceso de generación que se alinea con la dificultad percibida de la tarea. Usa animaciones para indicar que se produjo un proceso de IA.
No hagas lo siguiente: No sorprendas a los usuarios con reemplazos instantáneos de la IU.
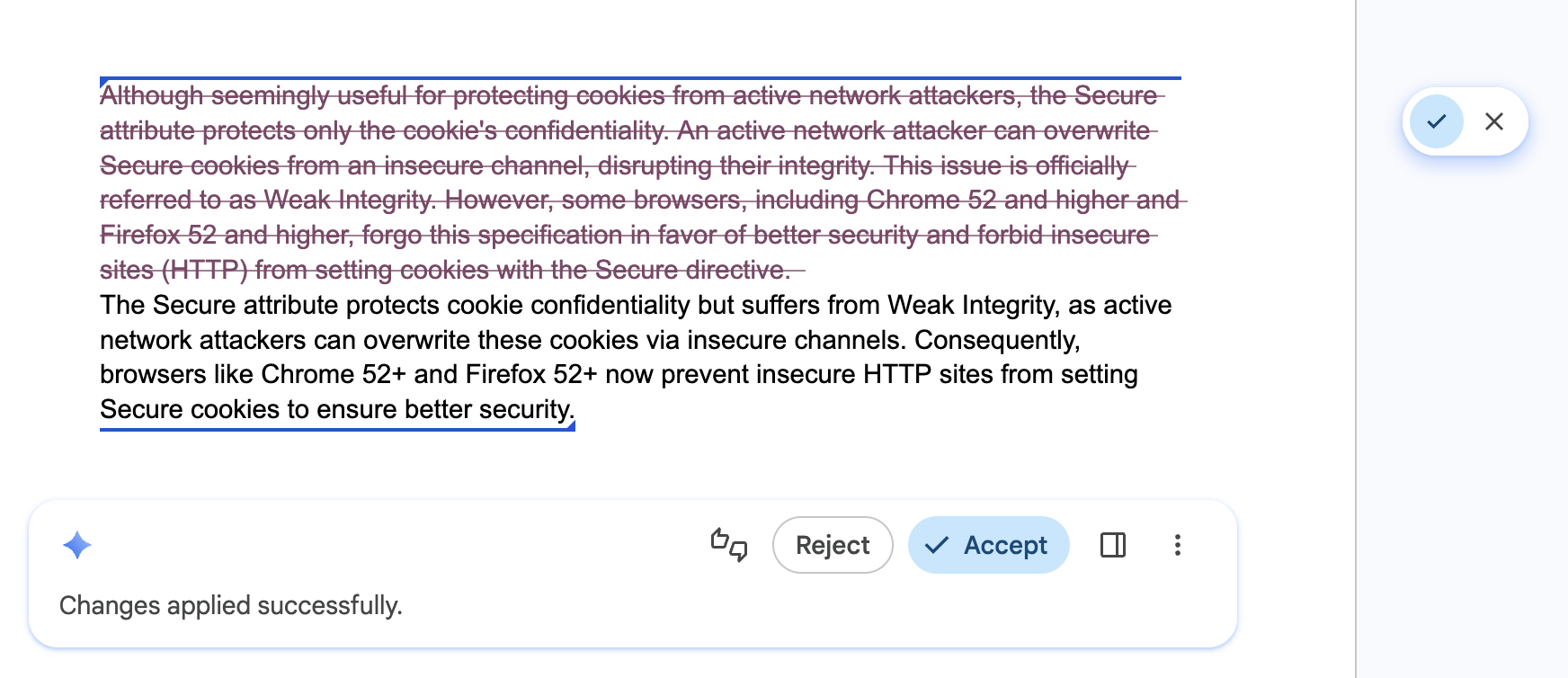
Permite que los usuarios naveguen rápidamente y deshagan las ediciones de IA
Se aplica a: todas las APIs.
Haz lo siguiente: Equipa tu IU con un stepper o un historial de navegación que permita a los usuarios explorar diferentes resultados con confianza y deshacer rápidamente las ediciones de IA. Esto garantiza que las diferentes versiones sigan estando disponibles con facilidad.
No hagas lo siguiente: No reemplaces el borrador anterior del usuario ni un resultado de IA que le haya gustado sin una forma de volver, revertir o comparar versiones.
Permite el control y las anulaciones del usuario
Se aplica a: todas las APIs.
Haz lo siguiente: Haz que el usuario sea el editor final de todo el contenido generado. Proporciona anulaciones intuitivas para que el usuario conserve la propiedad total del resultado final. Es posible que las APIs produzcan resultados incorrectos.
No hagas lo siguiente: No fuerces un resultado generado por IA como la única opción.
Almacena en caché los resultados de tareas repetidas
Se aplica a: todas las APIs.
Haz lo siguiente: Implementa una caché de resultados local (por ejemplo, con sessionStorage o IndexedDB) para entradas o consultas repetidas. Normaliza la entrada recortando los espacios en blanco y convirtiendo a minúsculas para aumentar los aciertos de caché. Para entradas pesadas, por ejemplo, imágenes, genera un hash para usarlo como clave de caché. Establece un tiempo de actividad (TTL) conservador para tu caché (o muestra los resultados almacenados en caché mientras los actualizas en segundo plano). Permite que el usuario active una inferencia nueva si el resultado no es satisfactorio.
No hagas lo siguiente: No vuelvas a ejecutar la misma inferencia para una consulta de búsqueda repetida o una entrada de datos idéntica en la que no se desea variabilidad, por ejemplo, cuando un usuario navega hacia atrás y hacia adelante entre los resultados de la búsqueda. Esto optimiza la capacidad de respuesta y el uso eficiente del procesamiento local.
// ✅ DO: Check a local cache before running inference
async function getAiResponse(userInput, forceRefresh = false) {
// Normalize the query to increase cache hits
const query = userInput.trim().toLowerCase();
const cacheKey = `ai_results_${query}`;
const TTL_MS = 3600000; // 1 hour conservative TTL
if (!forceRefresh) {
const itemStr = localStorage.getItem(cacheKey);
if (itemStr) {
const item = JSON.parse(itemStr);
const now = Date.now();
// Check if the item has expired
if (now < item.expiry) {
// Lightweight safety check before rendering
if (isValid(item.value)) return item.value;
} else {
// Delete the stale entry if the TTL has passed
localStorage.removeItem(cacheKey);
}
}
}
// Fallback: Run inference if no valid cache exists
const session = await LanguageModel.create();
const response = await session.prompt(userInput);
// Store the result for future use (with an expiration)
const cacheData = {
value: response,
expiry: Date.now() + TTL_MS
};
localStorage.setItem(cacheKey, JSON.stringify(cacheData));
return response;
}