

公開日: 2026 年 4 月 30 日
AI が組み込まれているため、ウェブサイトやウェブ アプリケーションは、モデルのデプロイ、管理、セルフホスティングを行うことなく、AI を活用したタスクを実行できます。デモからプロダクション レディ(な)機能に移行するのは難しい場合があります。このドキュメントでは、よくある落とし穴を回避するために考慮すべき技術面と UX 面について説明します。
妥当な時間内にモデルを準備する
対象: Summarizer、Translator、Writer などのすべての API。
推奨: ユーザーが AI 機能を使用する意図を明確に示した時点でセッションを初期化します。たとえば、ユーザーが関連する AI ツール画面に移動したとき、AI ワークスペースにカーソルを合わせたとき、機能の周囲の UI を操作したときなどです。セッションを事前ウォーミングすることで、ユーザーがタスクを設定している間にモデルをバックグラウンドでメモリに読み込むことができ、回避可能なコールド スタートのレイテンシを解消できます。たとえば、機能が反復使用を想定して設計されている場合、現在の結果のレンダリングを開始したら、すぐに次の可能性の高い AI タスクを開始して、一歩先を行くようにします。
しないこと: 必要な場合を除き、ユーザーが [生成] をクリックするまでセッションを初期化しないでください。モデルをメモリに初回読み込みして実行パイプラインを準備する必要があるため、コールド スタートの遅延が発生します。
作成時に初期プロンプトを設定する
適用対象: Prompt API。
推奨: セッションの初期化中にシステム指示を提供して、最初のプロンプトの速度を向上させます。
しないこと: 空のセッションで開始し、最初の prompt() 呼び出しの一部としてシステム指示を送信します。これにより、モデルがこれらの指示を最後に処理する必要があるため、レイテンシが増加します。
// ✅ DO: Create the session as early as possible (tip on warming up the model early) and use initialPrompts for system instructions in the create call
const session = await LanguageModel.create({
initialPrompts: [
{ role: 'system', content: 'You are a helpful assistant specialized in code reviews.' }
]
});
// A few moments later, when the user triggers the AI feature
const review = await session.prompt(`Review the following code:\n\n${code}`);
// ❌ DON'T: Send instructions using prompt() after creation
// const slowerSession = await LanguageModel.create();
// await slowerSession.prompt(`You are a helpful assistant specialized in code reviews.\n\nReview the following code:\n\n${code}`); // Higher latency
繰り返し行うタスクのセッションを複製する
適用対象: Prompt API。
Prompt API の場合、各セッションは会話のコンテキストを追跡し、以前のすべてのやり取りを考慮します。クローンは、初期プロンプトやクローン作成時点までのすべてのインタラクション履歴など、親セッションのすべてを継承するため、必要なものだけを継承するように使用方法を構成します。
行うこと:
- ベース セッションを作成する: 無関係なタスクを効率的に処理するには、システム指示のみを含み、以前の会話コンテキストを含まないベース セッションを作成します。
- ベースラインを複製する: 新しいタスクにベース セッションで
clone()を使用して、システム指示の再解析のオーバーヘッドを削減します。これにより、並行して会話を作成したり、タスクをベースラインにリセットしたりできます。
避けるべきこと:
- 無関係なタスクに同じセッションを再利用しないでください。また、不要なやり取りの履歴がすでに含まれているセッションの複製は避けてください。どちらのパターンでも、無関係な以前のコンテキストが現在のタスクに干渉する可能性があります。
- 同じシステム指示で
create()を繰り返し呼び出さないでください。代わりにクローニング パターンを使用して、パフォーマンスを最適化します。
// ✅ DO: Create a baseline session and clone it for each new task
const baseSession = await LanguageModel.create({
initialPrompts: [{
role: 'system',
content: 'You are a technical editor...',
}],
});
// Clone the base session once for the first task
const task1 = await baseSession.clone();
const response1 = await task1.prompt("Review this first draft...");
// ... Repeat the cloning pattern for subsequent independent tasks
// Each task starts fresh from the baseline system instructions
// ❌ DON'T:
// Bad performance pattern: repeated create() calls for identical tasks.
// This forces the model to re-parse instructions every time, increasing latency.
// const sessionA = await LanguageModel.create({ initialPrompts: [...] });
// await sessionA.prompt("Task 1...");
// const sessionB = await LanguageModel.create({ initialPrompts: [...] });
// await sessionB.prompt("Task 2...");
// Bad quality pattern: reusing the same session for unrelated tasks.
// const session = await LanguageModel.create();
// await session.prompt("Analyze this financial report...");
// Unrelated task in the same session:
// await session.prompt("Now write a children's story...");
使用されていないセッションを破棄する
適用対象: すべての API。
推奨: 機能が不要になったときにメモリを解放するため、不要になったセッションで destroy() を明示的に呼び出します。クローニング パターンを使用する場合は、ベース セッションを保持し、不要になったクローンを破棄します。
しないこと: 複数の大規模なセッションをアクティブな状態に保ちます。各セッションはメモリを消費するため、リソースの無駄な使用につながり、問題になる可能性があります。セッションはガベージ コレクタによって自動的にクリーンアップされますが、destroy() を呼び出すと、より迅速にメモリが解放されます。
// ✅ DO: Use the clone and destroy it immediately after
const clone = await baseSession.clone();
const response = await clone.prompt("Quick task...");
// Free memory right away: destry the clone, keep the baseSession
clone.destroy();
ストリーミング レスポンスを安全かつ効率的にレンダリングする
対象: ストリーミングをサポートするすべての API(Prompt、Summarizer、Writer、Rewriter、Translator)。
行うこと: LLM のすべての出力を信頼できないコンテンツとして扱う。悪意のあるコードが更新にまたがって分割される可能性があるため、チャンクだけでなく、結合された出力全体をサニタイズします。レンダリングする前に、サポートされている場合は Sanitizer API を使用します。パフォーマンスの低下を避けるには、streaming-markdown などのストリーミング Markdown パーサーを使用します。
しないこと: チャンクの更新ごとに innerHTML を直接設定しないでください。これは遅く、特に構文のハイライト表示のような複雑な書式設定では遅くなります。また、インジェクションに対して脆弱です。
import * as smd from "streaming-markdown";
// Set up virtual buffer and Sanitizer API
const sanitizer = new Sanitizer({
allowElements: ['figure', 'figcaption', 'p', 'br', 'strong', 'em', 'img', 'a'],
allowAttributes: {
'loading': ['img'], 'decoding': ['img'], 'src': ['img'], 'href': ['a']
}
});
// Create an off-screen fragment so the parser doesn't cause flicker
// or trigger XSS in the live DOM during the building process.
const buffer = new DocumentFragment();
const parser = smd.parser_new(buffer);
// Use sanitizer as a gatekeeper / cleaner function so we can combine it with the streaming Markdown parser
function syncSanitized(target, sourceFragment) {
// .sanitize() returns a fresh, clean DocumentFragment
const cleanFragment = sanitizer.sanitize(sourceFragment);
// replaceChildren is the modern high-performance way to swap DOM content
target.replaceChildren(cleanFragment);
}
// Streaming Logic
// `chunks` keeps track of the raw string (useful for logs/debug)
chunks += chunk;
// Let the parser build the DOM incrementally in the buffer.
// This is high-performance because the buffer is not live
smd.parser_write(parser, chunk);
// Use the Sanitizer API to port the content safely to the container.
syncSanitized(container, buffer);
速度を考慮して入力を最適化する
適用対象: すべての API。
推奨: 厳密に必要なものだけをモデルに渡します。当面のタスクに関係のないものはすべて削除します。大規模なデータセットの場合は、簡単な概要と関連アイテムの小さな選択を提供します。
避けるべきこと: 未加工のテキスト、不要なメタデータ、HTML タグ、フィルタリングされていない大きなリストを API に送信しないでください。レイテンシは入力サイズとともに大幅に増加するため、多くのデバイスで AI 機能が壊れているように見えることがあります。
// ✅ DO: Send only relevant text
const cleanText = document.querySelector('#article').innerText;
const summary = await Summarizer.summarize(cleanText);
// ❌ DON'T: Send the entire DOM structure
// const dirtyText = document.querySelector('#article').innerHTML;
予測可能な結果を得るために構造化出力を使用する
適用対象: Prompt API。
推奨: モデルに特定の形式でデータを返す必要がある場合は、responseConstraint フィールドで JSON スキーマを指定して、構造化出力を使用します。これにより、出力が予測可能になり、複雑な後処理や手動解析が不要になります。
禁止事項: 自然言語の指示(「JSON のみを出力」など)だけに頼る。モデルには、パーサーを壊す会話のフィラーが含まれている可能性があります。
// ✅ DO: Use a JSON Schema for predictable results
const schema = {
type: "object",
properties: {
isTopicCats: { type: "boolean" }
}
};
const result = await session.prompt(`Is this post about cats?\n\n${post}`, {
responseConstraint: schema,
});
console.log(JSON.parse(result).isTopicCats);
生成を長さの制約から切り離す
適用対象: Prompt API。これは、構造化された出力スキーマをサポートする唯一の API であるためです。
推奨: モデルに自然なレスポンスを生成させ、クライアントサイドのロジックを使用してテキストを切り捨て、UI に合わせます。
しないこと: 構造化された出力スキーマを使用して、maxLength: 125 などの厳しい文字数制限を適用します。モデルのレスポンスが設定した上限を超えると、モデルは意味を圧縮するために外国語や絵文字などの高密度トークンに切り替えることがあり、その結果、意味不明な出力になることがあります。
/* DO: Handle overflow using CSS */
.result {
overflow: hidden;
white-space: nowrap;
text-overflow: ellipsis; /* Displays '…' */
}
// ❌ DON'T: Force length in the prompt
const result = await session.prompt("Write a bio in exactly 50 characters.");
ユーザーに情報を知らせる
適用対象: すべての API。
行うべきこと: タスクの複雑さと想定される所要時間に応じて、アニメーション、視覚的な合図、進行状況インジケーターを使用して、ユーザーに情報を伝えます。最適なアプローチは、ユースケースと API 出力の予想される長さによって異なります。アイデアの例:
- 長いコンテンツのストリーミング: 要約やチャットの場合、ストリーミングではデフォルトでトークンごとのタイプライター効果が作成されます。これにより、自然な操作感と即時のフィードバックが得られます。
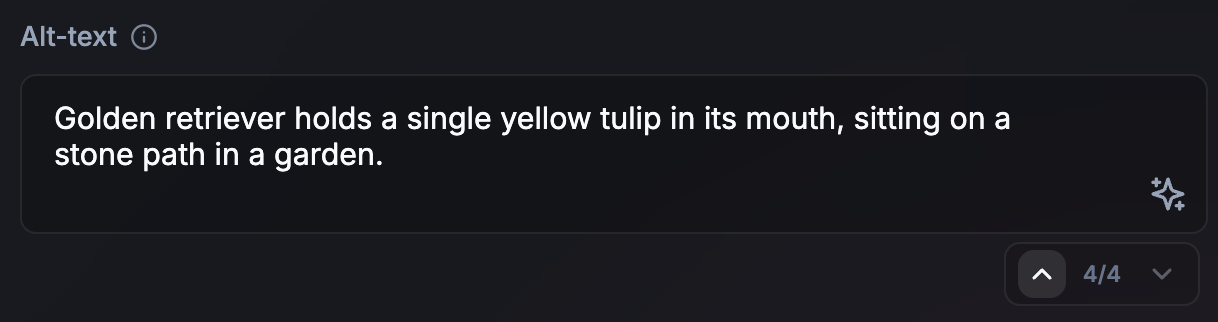
- 短いタスク(または長い非同期タスク)の非ストリーミング: 短い出力(代替テキストなど)の場合、非ストリーミングを使用すると、より洗練された UI を作成できます。また、現在のタスクのレンダリング中に、次の AI タスクを推測的に準備する時間も提供します。このアプローチは、非同期タスクやバックグラウンド タスクが長時間実行される場合にも有効です。ユーザーがジャーニーを続行するために出力でブロックされていない場合、出力が生成されるたびに緊急で出力する必要はありません。UI でプロセスが進行中であることを示します。
- 更新の視覚的なトランジション: テキストの翻訳や書き換えを行う際は、単語の変形などのアニメーションを使用します。
禁止事項: 視覚的な合図なしで UI を更新しないでください。
時間と仕事に関するユーザーのメンタルモデルに沿う
適用対象: すべての API。
推奨: レスポンスがほぼ瞬時に返される場合は、1 ~ 2 秒の人工的な遅延を検討してください。逆説的ですが、ユーザーは、タスクの難易度と一致する生成プロセスを認識すると、結果の信頼性が高まると感じる可能性があります。アニメーションを使用して、AI プロセスが発生したことを示します。
しないこと: UI を即座に置き換えてユーザーを驚かせる。
AI による編集をすばやくナビゲートして元に戻す
適用対象: すべての API。
推奨: ユーザーがさまざまな結果を自信を持って確認できるように、UI にステッパーまたはナビゲーション履歴を組み込み、AI による編集をすばやく元に戻せるようにします。これにより、さまざまなバージョンをすぐに利用できるようになります。
してはいけないこと: ユーザーが気に入った可能性のある以前の下書きや AI の結果を、バージョンを戻したり、元に戻したり、比較したりする方法がない状態で上書きする。
ボタン。](https://developer.chrome.com/static/docs/ai/built-in-ai-dos-donts/images/image2.png?authuser=09&hl=ja)
ユーザーによる制御とオーバーライドを可能にする
適用対象: すべての API。
行うこと: 生成されたすべてのコンテンツの最終的な編集者をユーザーにする。ユーザーが最終的な出力の完全な所有権を維持できるように、直感的なオーバーライドを提供します。API が不正確な結果を生成する可能性があります。
禁止事項: AI 生成の結果を唯一の選択肢として強制する。
繰り返されるタスクの結果をキャッシュに保存する
適用対象: すべての API。
推奨: 繰り返し入力またはクエリに対して、ローカル結果キャッシュ(sessionStorage または IndexedDB を使用するなど)を実装します。空白を削除して小文字に変換することで入力を正規化し、キャッシュ ヒットを増やします。画像などの重い入力の場合は、キャッシュキーとして使用するハッシュを生成します。キャッシュの有効期間(TTL)を控えめに設定します(または、キャッシュに保存された結果をバックグラウンドで更新しながら提供します)。結果が満足のいくものでない場合は、ユーザーが新しい推論をトリガーできるようにします。
避けるべきこと: ユーザーが検索結果を前後に移動する場合など、変動が望ましくない繰り返し検索クエリや同一のデータ入力に対して、同じ推論を再実行しないでください。これにより、応答性とローカル コンピューティングの効率的な使用が最適化されます。
// ✅ DO: Check a local cache before running inference
async function getAiResponse(userInput, forceRefresh = false) {
// Normalize the query to increase cache hits
const query = userInput.trim().toLowerCase();
const cacheKey = `ai_results_${query}`;
const TTL_MS = 3600000; // 1 hour conservative TTL
if (!forceRefresh) {
const itemStr = localStorage.getItem(cacheKey);
if (itemStr) {
const item = JSON.parse(itemStr);
const now = Date.now();
// Check if the item has expired
if (now < item.expiry) {
// Lightweight safety check before rendering
if (isValid(item.value)) return item.value;
} else {
// Delete the stale entry if the TTL has passed
localStorage.removeItem(cacheKey);
}
}
}
// Fallback: Run inference if no valid cache exists
const session = await LanguageModel.create();
const response = await session.prompt(userInput);
// Store the result for future use (with an expiration)
const cacheData = {
value: response,
expiry: Date.now() + TTL_MS
};
localStorage.setItem(cacheKey, JSON.stringify(cacheData));
return response;
}