

게시일: 2026년 4월 30일
기본 제공 AI를 사용하면 모델을 배포, 관리 또는 자체 호스팅할 필요 없이 웹사이트 또는 웹 애플리케이션에서 AI 기반 작업을 실행할 수 있습니다. 데모에서 프로덕션 레디 기능으로 이동하는 것이 어려울 수 있습니다. 이 문서에서는 일반적인 문제를 방지하는 데 도움이 되는 기술 및 UX 고려사항을 다룹니다.
적절한 시간에 모델 준비
적용 대상: 모든 API(예: Summarizer, Translator, Writer)
해야 할 일: 사용자가 AI 기능을 사용하려는 의도를 명확하게 확인한 즉시 세션을 초기화합니다. 예를 들어 사용자가 관련 AI 도구 표시로 이동하거나, AI 워크스페이스 위로 마우스를 가져가거나, 기능의 주변 UI와 상호작용하는 경우입니다. 세션을 사전 워밍하면 사용자가 작업을 설정하는 동안 모델이 백그라운드에서 조용히 메모리에 로드되어 피할 수 있는 콜드 스타트 지연 시간이 제거됩니다. 기능이 반복적으로 사용하도록 설계된 경우 현재 결과를 렌더링하기 시작하는 즉시 다음으로 가장 가능성이 높은 AI 태스크를 시작하여 한 단계 앞서 나가세요.
안됨: 필요한 경우가 아니라면 사용자가 '생성'을 클릭할 때까지 기다려 세션을 초기화하지 마세요. 모델이 먼저 메모리에 로드되고 실행 파이프라인을 준비해야 하므로 콜드 스타트 지연이 발생합니다.
생성 중에 초기 프롬프트 설정
적용 대상: Prompt API
권장: 세션 초기화 중에 시스템 요청 사항을 제공하여 첫 번째 프롬프트의 속도를 개선합니다.
하면 안 됨: 빈 세션으로 시작하고 첫 번째 prompt() 호출의 일부로 시스템 명령어를 전송합니다. 이렇게 하면 모델이 마지막 순간에 이러한 명령어를 처리해야 하므로 지연 시간이 늘어납니다.
// ✅ DO: Create the session as early as possible (tip on warming up the model early) and use initialPrompts for system instructions in the create call
const session = await LanguageModel.create({
initialPrompts: [
{ role: 'system', content: 'You are a helpful assistant specialized in code reviews.' }
]
});
// A few moments later, when the user triggers the AI feature
const review = await session.prompt(`Review the following code:\n\n${code}`);
// ❌ DON'T: Send instructions using prompt() after creation
// const slowerSession = await LanguageModel.create();
// await slowerSession.prompt(`You are a helpful assistant specialized in code reviews.\n\nReview the following code:\n\n${code}`); // Higher latency
반복적인 작업을 위해 세션 복제
적용 대상: Prompt API
프롬프트 API의 경우 각 세션은 대화의 컨텍스트를 추적하여 이전의 모든 상호작용을 고려합니다. 클론은 초기 프롬프트와 클론 시점까지의 모든 상호작용 기록을 비롯한 모든 항목을 상위 세션에서 상속하므로 필요한 항목만 상속하도록 사용을 구성하세요.
해야 할 일:
- 기본 세션 만들기: 관련 없는 작업을 효율적으로 처리하려면 시스템 안내만 포함하고 이전 대화 컨텍스트는 포함하지 않는 기본 세션을 만드세요.
- 기준 클론: 새 작업의 경우 해당 기본 세션에서
clone()를 사용하여 시스템 명령어를 다시 파싱하는 오버헤드를 절약합니다. 이를 통해 병렬 대화를 만들거나 작업을 기준선으로 재설정할 수 있습니다.
금지사항:
- 관련 없는 작업에 동일한 세션을 재사용하지 말고 불필요한 상호작용 기록이 이미 포함된 세션을 클론하지 마세요. 두 패턴 모두 관련 없는 이전 컨텍스트가 현재 작업에 방해가 될 수 있습니다.
- 동일한 시스템 명령어로
create()를 반복적으로 호출하지 마세요. 대신 클로닝 패턴을 사용하여 성능을 최적화하세요.
// ✅ DO: Create a baseline session and clone it for each new task
const baseSession = await LanguageModel.create({
initialPrompts: [{
role: 'system',
content: 'You are a technical editor...',
}],
});
// Clone the base session once for the first task
const task1 = await baseSession.clone();
const response1 = await task1.prompt("Review this first draft...");
// ... Repeat the cloning pattern for subsequent independent tasks
// Each task starts fresh from the baseline system instructions
// ❌ DON'T:
// Bad performance pattern: repeated create() calls for identical tasks.
// This forces the model to re-parse instructions every time, increasing latency.
// const sessionA = await LanguageModel.create({ initialPrompts: [...] });
// await sessionA.prompt("Task 1...");
// const sessionB = await LanguageModel.create({ initialPrompts: [...] });
// await sessionB.prompt("Task 2...");
// Bad quality pattern: reusing the same session for unrelated tasks.
// const session = await LanguageModel.create();
// await session.prompt("Analyze this financial report...");
// Unrelated task in the same session:
// await session.prompt("Now write a children's story...");
사용하지 않는 세션 삭제
적용 대상: 모든 API
해야 함: 더 이상 필요하지 않은 세션에서 destroy()를 명시적으로 호출하여 기능이 더 이상 사용되지 않을 때 메모리를 확보합니다. 클론 패턴을 사용하는 경우 기본 세션을 유지하고 더 이상 필요하지 않은 클론을 삭제합니다.
안됨: 여러 개의 대규모 세션을 활성 상태로 유지합니다. 각 세션은 메모리를 소비하므로 불필요한 리소스 사용이 발생하고 문제가 될 수 있습니다. 세션은 가비지 컬렉터에 의해 자연스럽게 정리되지만 destroy()를 호출하면 메모리가 더 빨리 해제됩니다.
// ✅ DO: Use the clone and destroy it immediately after
const clone = await baseSession.clone();
const response = await clone.prompt("Quick task...");
// Free memory right away: destry the clone, keep the baseSession
clone.destroy();
스트리밍 응답을 안전하고 효율적으로 렌더링
적용 대상: 스트리밍을 지원하는 모든 API (프롬프트, Summarizer, Writer, Rewriter, Translator)
해야 할 일: 모든 LLM 출력을 신뢰할 수 없는 콘텐츠로 취급합니다. 악성 코드가 업데이트 전반에 걸쳐 분할될 수 있으므로 청크뿐만 아니라 전체 결합 출력을 정리하세요. 렌더링하기 전에 지원되는 경우 Sanitizer API를 사용하세요. 성능 저하를 방지하려면 streaming-markdown과 같은 스트리밍 마크다운 파서를 사용하세요.
잘못된 예: 모든 청크 업데이트에서 innerHTML을 직접 설정합니다. 이 방법은 특히 구문 강조 표시와 같은 복잡한 서식의 경우 느리고 삽입에 취약합니다.
import * as smd from "streaming-markdown";
// Set up virtual buffer and Sanitizer API
const sanitizer = new Sanitizer({
allowElements: ['figure', 'figcaption', 'p', 'br', 'strong', 'em', 'img', 'a'],
allowAttributes: {
'loading': ['img'], 'decoding': ['img'], 'src': ['img'], 'href': ['a']
}
});
// Create an off-screen fragment so the parser doesn't cause flicker
// or trigger XSS in the live DOM during the building process.
const buffer = new DocumentFragment();
const parser = smd.parser_new(buffer);
// Use sanitizer as a gatekeeper / cleaner function so we can combine it with the streaming Markdown parser
function syncSanitized(target, sourceFragment) {
// .sanitize() returns a fresh, clean DocumentFragment
const cleanFragment = sanitizer.sanitize(sourceFragment);
// replaceChildren is the modern high-performance way to swap DOM content
target.replaceChildren(cleanFragment);
}
// Streaming Logic
// `chunks` keeps track of the raw string (useful for logs/debug)
chunks += chunk;
// Let the parser build the DOM incrementally in the buffer.
// This is high-performance because the buffer is not live
smd.parser_write(parser, chunk);
// Use the Sanitizer API to port the content safely to the container.
syncSanitized(container, buffer);
속도를 위해 입력 최적화
적용 대상: 모든 API
해야 할 일: 꼭 필요한 정보만 모델에 전달하세요. 현재 작업과 관련이 없는 모든 것을 삭제합니다. 대규모 데이터 세트의 경우 간단한 개요와 관련 항목의 작은 선택을 제공합니다.
금지사항: 처리되지 않은 원시 텍스트, 불필요한 메타데이터, HTML 태그 또는 필터링되지 않은 대규모 목록을 API에 전송하지 마세요. 지연 시간은 입력 크기에 따라 크게 증가하므로 많은 기기에서 AI 기능이 작동하지 않는 것처럼 보일 수 있습니다.
// ✅ DO: Send only relevant text
const cleanText = document.querySelector('#article').innerText;
const summary = await Summarizer.summarize(cleanText);
// ❌ DON'T: Send the entire DOM structure
// const dirtyText = document.querySelector('#article').innerHTML;
예측 가능한 결과를 위해 구조화된 출력 사용
적용 대상: Prompt API
권장: 모델이 특정 형식으로 데이터를 반환해야 하는 경우 responseConstraint 필드를 제공하여 JSON 스키마를 제공하여 구조화된 출력을 사용합니다. 이렇게 하면 출력을 예측할 수 있고 복잡한 사후 처리나 수동 파싱이 필요하지 않습니다.
금지: 자연어 요청 사항('JSON만 출력' 등)에만 의존하지 마세요. 모델에 파서를 중단하는 대화형 필러가 포함될 수 있습니다.
// ✅ DO: Use a JSON Schema for predictable results
const schema = {
type: "object",
properties: {
isTopicCats: { type: "boolean" }
}
};
const result = await session.prompt(`Is this post about cats?\n\n${post}`, {
responseConstraint: schema,
});
console.log(JSON.parse(result).isTopicCats);
길이 제약 조건에서 생성 분리
적용 대상: 구조화된 출력 스키마를 지원하는 유일한 API인 Prompt API
권장: 모델이 자연스럽게 대답을 생성하도록 한 다음 클라이언트 측 로직을 사용하여 UI에 맞게 텍스트를 자릅니다.
금지: 구조화된 출력 스키마를 사용하여 maxLength: 125와 같은 엄격한 글자 수 제한을 적용합니다. 모델의 대답이 설정한 한도를 초과하면 모델이 의미를 압축하기 위해 외국어나 그림 이모티콘과 같은 고밀도 토큰으로 전환되어 무의미한 출력이 생성될 수 있습니다.
/* DO: Handle overflow using CSS */
.result {
overflow: hidden;
white-space: nowrap;
text-overflow: ellipsis; /* Displays '…' */
}
// ❌ DON'T: Force length in the prompt
const result = await session.prompt("Write a bio in exactly 50 characters.");
사용자에게 알리기
적용 대상: 모든 API
권장: 작업의 복잡성과 예상 기간에 따라 애니메이션, 시각적 신호, 진행률 표시기를 사용하여 사용자에게 정보를 제공합니다. 최적의 접근 방식은 사용 사례와 예상되는 API 출력 길이에 따라 다릅니다. 몇 가지 아이디어:
- 긴 콘텐츠 스트리밍: 요약 또는 채팅의 경우 스트리밍은 기본적으로 토큰별 타자기 효과를 만듭니다. 이렇게 하면 자연스럽게 느껴지고 즉각적인 피드백을 제공할 수 있습니다.
- 짧은 작업 (또는 긴 비동기 작업)의 경우 스트리밍하지 않음: 대체 텍스트와 같은 짧은 출력의 경우 스트리밍하지 않으면 더 세련된 UI를 만들 수 있습니다. 또한 현재 AI 작업이 렌더링되는 동안 다음 AI 태스크를 추측하여 준비할 시간을 제공합니다. 이 접근 방식은 더 긴 비동기 또는 백그라운드 작업에도 적용됩니다. 사용자가 여정을 계속하기 위해 출력에서 차단되지 않는다면 출력을 즉시 생성할 필요는 없습니다. UI에서 프로세스가 진행 중임을 알립니다.
- 업데이트를 위한 시각적 전환: 텍스트를 번역하거나 다시 쓸 때 단어 변형과 같은 애니메이션을 사용합니다.
안됨: 시각적 단서 없이 UI를 업데이트합니다.
시간과 작업에 대한 사용자의 정신적 모델에 맞게 조정
적용 대상: 모든 API
권장: 대답이 거의 즉시 표시되는 경우 1~2초의 인위적인 지연을 고려합니다. 역설적으로 사용자는 작업의 난이도에 대한 인식과 일치하는 생성 프로세스를 인식할 때 결과를 더 신뢰할 수 있다고 생각할 수 있습니다. 애니메이션을 사용하여 AI 프로세스가 발생했음을 알립니다.
금지: 즉각적인 UI 교체로 사용자를 놀라게 해서는 안 됩니다.
사용자가 AI 편집 내용을 빠르게 탐색하고 실행취소할 수 있도록 허용
적용 대상: 모든 API
권장사항: 사용자가 다양한 결과를 자신 있게 탐색할 수 있는 스테퍼 또는 탐색 기록을 UI에 제공하고 AI 수정사항을 빠르게 실행취소할 수 있도록 합니다. 이렇게 하면 다양한 버전을 계속 쉽게 사용할 수 있습니다.
하지 말 것: 사용자가 이전 버전으로 돌아가거나, 버전을 되돌리거나, 버전을 비교할 수 있는 방법 없이 사용자의 이전 임시 저장 또는 사용자가 좋아했을 수 있는 AI 결과를 덮어쓰지 마세요.
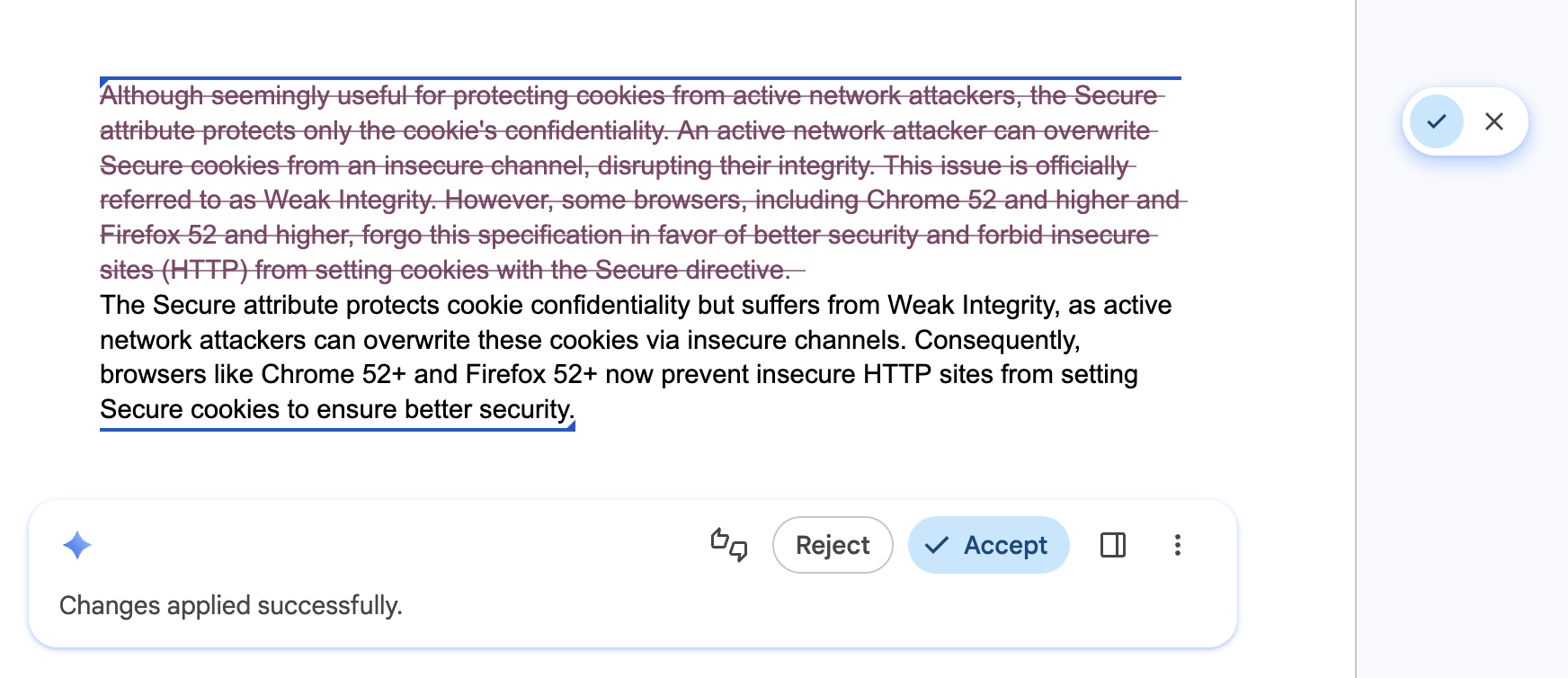
사용자 제어 및 재정의 지원
적용 대상: 모든 API
해야 할 일: 생성된 모든 콘텐츠의 최종 편집자가 되도록 사용자에게 요청합니다. 사용자가 최종 출력을 완전히 소유할 수 있도록 직관적인 재정의를 제공합니다. API가 잘못된 결과를 생성할 수 있습니다.
잘못된 예: AI 생성 결과를 유일한 옵션으로 강제합니다.
반복되는 작업의 결과 캐시
적용 대상: 모든 API
권장: 반복되는 입력 또는 쿼리에 대해 로컬 결과 캐시를 구현합니다 (예: sessionStorage 또는 IndexedDB 사용). 캐시 적중률을 높이기 위해 공백을 자르고 소문자로 변환하여 입력을 정규화합니다. 이미지와 같은 대량 입력의 경우 캐시 키로 사용할 해시를 생성합니다. 캐시의 TTL(수명)을 보수적으로 설정하거나 백그라운드에서 업데이트하는 동안 캐시된 결과를 제공합니다. 결과가 만족스럽지 않으면 사용자가 새로운 추론을 트리거하도록 허용합니다.
금지: 사용자가 검색 결과 사이를 앞뒤로 탐색하는 등 변동성이 바람직하지 않은 경우 반복되는 검색어 또는 동일한 데이터 입력에 대해 동일한 추론을 다시 실행하지 마세요. 이렇게 하면 응답성과 로컬 컴퓨팅의 효율적인 사용이 최적화됩니다.
// ✅ DO: Check a local cache before running inference
async function getAiResponse(userInput, forceRefresh = false) {
// Normalize the query to increase cache hits
const query = userInput.trim().toLowerCase();
const cacheKey = `ai_results_${query}`;
const TTL_MS = 3600000; // 1 hour conservative TTL
if (!forceRefresh) {
const itemStr = localStorage.getItem(cacheKey);
if (itemStr) {
const item = JSON.parse(itemStr);
const now = Date.now();
// Check if the item has expired
if (now < item.expiry) {
// Lightweight safety check before rendering
if (isValid(item.value)) return item.value;
} else {
// Delete the stale entry if the TTL has passed
localStorage.removeItem(cacheKey);
}
}
}
// Fallback: Run inference if no valid cache exists
const session = await LanguageModel.create();
const response = await session.prompt(userInput);
// Store the result for future use (with an expiration)
const cacheData = {
value: response,
expiry: Date.now() + TTL_MS
};
localStorage.setItem(cacheKey, JSON.stringify(cacheData));
return response;
}