

Publicado em: 30 de abril de 2026
Com a IA integrada, seu site ou aplicativo da Web pode realizar tarefas com tecnologia de IA sem precisar implantar, gerenciar ou hospedar modelos por conta própria. Talvez seja difícil passar de uma demonstração para um recurso pronto para produção. Este documento aborda considerações técnicas e de UX para ajudar você a evitar armadilhas comuns.
Prepare o modelo em um momento razoável
Vale para: todas as APIs, por exemplo, Summarizer, Translator e Writer.
Faça o seguinte:inicialize a sessão assim que você tiver estabelecido claramente a intenção do usuário de usar o recurso de IA. Por exemplo, quando um usuário navega até uma superfície de ferramentas de IA relevante, passa o cursor sobre um espaço de trabalho de IA ou interage com a interface ao redor do recurso. O pré-aquecimento permite que o modelo seja carregado na memória em segundo plano enquanto o usuário configura a tarefa, eliminando a latência de inicialização a frio evitável. Tente se antecipar e inicie a próxima tarefa de IA mais provável assim que começar a renderizar o resultado atual. Por exemplo, se o recurso for projetado para uso iterativo.
Não:a menos que seja necessário, não espere o usuário clicar em "Gerar" para inicializar a sessão. Isso causa um atraso na inicialização a frio, porque o modelo precisa ser carregado na memória e preparar o pipeline de execução.
Definir comandos iniciais durante a criação
Aplicável à API Prompt.
Faça o seguinte:forneça instruções do sistema durante a inicialização da sessão para melhorar a velocidade do primeiro comando.
Não:comece com uma sessão vazia e envie instruções do sistema como parte da
primeira chamada prompt(). Isso aumenta a latência porque força o modelo a processar essas instruções no último momento.
// ✅ DO: Create the session as early as possible (tip on warming up the model early) and use initialPrompts for system instructions in the create call
const session = await LanguageModel.create({
initialPrompts: [
{ role: 'system', content: 'You are a helpful assistant specialized in code reviews.' }
]
});
// A few moments later, when the user triggers the AI feature
const review = await session.prompt(`Review the following code:\n\n${code}`);
// ❌ DON'T: Send instructions using prompt() after creation
// const slowerSession = await LanguageModel.create();
// await slowerSession.prompt(`You are a helpful assistant specialized in code reviews.\n\nReview the following code:\n\n${code}`); // Higher latency
Clonar sessões para tarefas repetitivas
Aplicável à API Prompt.
Para a API Prompt, cada sessão rastreia o contexto da conversa, considerando todas as interações anteriores. Como um clone herda tudo da sessão principal, incluindo comandos iniciais e todo o histórico de interações até o ponto da clonagem, estruture seu uso para herdar apenas o que você precisa.
O que fazer:
- Crie uma sessão básica: para lidar com tarefas não relacionadas de maneira eficiente, crie uma sessão básica que contenha apenas as instruções do sistema e nenhum contexto de conversa anterior.
- Clone a linha de base: use
clone()nessa sessão base para novas tarefas e salve o trabalho de reanalisar as instruções do sistema. Isso permite criar conversas paralelas ou redefinir uma tarefa para o valor de referência.
Não faça isso:
- Não reutilize a mesma sessão para tarefas não relacionadas e evite clonar qualquer sessão que já contenha um histórico de interação desnecessário. Ambos os padrões podem fazer com que um contexto anterior não relacionado interfira na sua tarefa atual.
- Não chame
create()repetidamente com instruções de sistema idênticas. Use o padrão de clonagem para otimizar a performance.
// ✅ DO: Create a baseline session and clone it for each new task
const baseSession = await LanguageModel.create({
initialPrompts: [{
role: 'system',
content: 'You are a technical editor...',
}],
});
// Clone the base session once for the first task
const task1 = await baseSession.clone();
const response1 = await task1.prompt("Review this first draft...");
// ... Repeat the cloning pattern for subsequent independent tasks
// Each task starts fresh from the baseline system instructions
// ❌ DON'T:
// Bad performance pattern: repeated create() calls for identical tasks.
// This forces the model to re-parse instructions every time, increasing latency.
// const sessionA = await LanguageModel.create({ initialPrompts: [...] });
// await sessionA.prompt("Task 1...");
// const sessionB = await LanguageModel.create({ initialPrompts: [...] });
// await sessionB.prompt("Task 2...");
// Bad quality pattern: reusing the same session for unrelated tasks.
// const session = await LanguageModel.create();
// await session.prompt("Analyze this financial report...");
// Unrelated task in the same session:
// await session.prompt("Now write a children's story...");
Destruir sessões não usadas
Vale para: todas as APIs.
Faça o seguinte:chame explicitamente destroy() em
sessões que não são mais necessárias para liberar memória quando um recurso
não estiver mais em uso. Se você usa um padrão de clonagem, mantenha a sessão base e destrua os clones que não são mais necessários.
Não:mantenha várias sessões grandes ativas. Cada sessão consome memória, o que cria um uso desnecessário de recursos e pode se tornar um problema. As sessões
serão limpas naturalmente pelo coletor de lixo, mas chamar destroy()
libera a memória mais rapidamente.
// ✅ DO: Use the clone and destroy it immediately after
const clone = await baseSession.clone();
const response = await clone.prompt("Quick task...");
// Free memory right away: destry the clone, keep the baseSession
clone.destroy();
Renderizar respostas de streaming com segurança e eficiência
Aplicável a: todas as APIs com suporte a streaming (Prompt, Summarizer, Writer, Rewriter e Translator).
Faça o seguinte:trate toda a saída do LLM como conteúdo não confiável. Higienize toda a saída combinada, não apenas partes dela, porque um código malicioso pode ser dividido em várias atualizações. Antes da renderização, use a API Sanitizer quando houver suporte. Para evitar uma queda na performance, use um analisador Markdown de streaming, como streaming-markdown.
Não faça isso:defina innerHTML diretamente em cada atualização de bloco. Isso é lento, especialmente com formatação complexa, como destaque de sintaxe, e vulnerável a injeção.
import * as smd from "streaming-markdown";
// Set up virtual buffer and Sanitizer API
const sanitizer = new Sanitizer({
allowElements: ['figure', 'figcaption', 'p', 'br', 'strong', 'em', 'img', 'a'],
allowAttributes: {
'loading': ['img'], 'decoding': ['img'], 'src': ['img'], 'href': ['a']
}
});
// Create an off-screen fragment so the parser doesn't cause flicker
// or trigger XSS in the live DOM during the building process.
const buffer = new DocumentFragment();
const parser = smd.parser_new(buffer);
// Use sanitizer as a gatekeeper / cleaner function so we can combine it with the streaming Markdown parser
function syncSanitized(target, sourceFragment) {
// .sanitize() returns a fresh, clean DocumentFragment
const cleanFragment = sanitizer.sanitize(sourceFragment);
// replaceChildren is the modern high-performance way to swap DOM content
target.replaceChildren(cleanFragment);
}
// Streaming Logic
// `chunks` keeps track of the raw string (useful for logs/debug)
chunks += chunk;
// Let the parser build the DOM incrementally in the buffer.
// This is high-performance because the buffer is not live
smd.parser_write(parser, chunk);
// Use the Sanitizer API to port the content safely to the container.
syncSanitized(container, buffer);
Otimizar a entrada para velocidade
Vale para: todas as APIs.
Faça o seguinte:transmita ao modelo apenas o que for estritamente necessário. Remova tudo o que for irrelevante para a tarefa em questão. Para conjuntos de dados grandes, forneça uma visão geral breve e uma pequena seleção de itens relevantes.
Não:envie texto bruto não processado, metadados desnecessários, tags HTML ou listas grandes não filtradas para as APIs. A latência aumenta significativamente com o tamanho da entrada, o que pode fazer com que o recurso de IA pareça quebrado em muitos dispositivos.
// ✅ DO: Send only relevant text
const cleanText = document.querySelector('#article').innerText;
const summary = await Summarizer.summarize(cleanText);
// ❌ DON'T: Send the entire DOM structure
// const dirtyText = document.querySelector('#article').innerHTML;
Usar saída estruturada para resultados previsíveis
Aplicável à API Prompt.
Faça o seguinte:quando precisar que o modelo retorne dados em um formato específico, use a saída estruturada fornecendo um campo responseConstraint para fornecer um esquema JSON. Isso garante que a saída seja previsível e evita a necessidade de pós-processamento complexo ou análise manual.
Não:confie apenas em instruções de linguagem natural (como "saída apenas JSON"). Os modelos podem incluir marcadores de conversa que interrompem seu analisador.
// ✅ DO: Use a JSON Schema for predictable results
const schema = {
type: "object",
properties: {
isTopicCats: { type: "boolean" }
}
};
const result = await session.prompt(`Is this post about cats?\n\n${post}`, {
responseConstraint: schema,
});
console.log(JSON.parse(result).isTopicCats);
Desvincular a geração das restrições de duração
Aplicável à API Prompt, já que é a única que oferece suporte a esquemas de saída estruturada.
Faça o seguinte:deixe o modelo gerar a resposta naturalmente e use a lógica do lado do cliente para truncar o texto e ajustar à sua interface.
Não:aplique limites de caracteres estritos, como maxLength: 125, usando esquemas de saída estruturada. Quando a resposta de um modelo é mais longa do que o limite definido, ele pode mudar para tokens de alta densidade, como idiomas estrangeiros ou emojis, para compactar o significado, resultando em uma saída sem sentido.
/* DO: Handle overflow using CSS */
.result {
overflow: hidden;
white-space: nowrap;
text-overflow: ellipsis; /* Displays '…' */
}
// ❌ DON'T: Force length in the prompt
const result = await session.prompt("Write a bio in exactly 50 characters.");
Manter o usuário informado
Vale para: todas as APIs.
Faça o seguinte:dependendo da complexidade e da duração esperada da tarefa, use animações, indicadores visuais e indicadores de progresso para manter o usuário informado. A abordagem ideal depende do seu caso de uso e do tamanho esperado da saída da API. Algumas ideias:
- Transmissão de conteúdo longo: para resumos ou chat, a transmissão cria um efeito de máquina de escrever por token por padrão. Isso pode parecer natural e fornecer feedback imediato.
- Não streaming para tarefas curtas (ou tarefas assíncronas longas): para saídas curtas, por exemplo, texto alternativo, o não streaming pode criar uma interface mais refinada. Ele também dá tempo para preparar especulativamente a próxima tarefa de IA enquanto a atual é renderizada. Essa abordagem também funciona para tarefas assíncronas ou em segundo plano mais longas. Se o usuário não estiver bloqueado na saída para continuar a jornada, não há necessidade urgente de produzir a saída conforme ela acontece. Sinalize que o processo está em andamento na interface.
- Transições visuais para atualizações: ao traduzir ou reescrever texto, use animações, por exemplo, transformação de palavras.
Restrição:não atualize a interface sem pistas visuais.
Alinhe-se com o modelo mental de tempo e trabalho do usuário
Vale para: todas as APIs.
Faça o seguinte:considere um atraso artificial de um ou dois segundos se uma resposta for quase instantânea. Paradoxalmente, os usuários podem achar os resultados mais confiáveis quando percebem um processo de geração que se alinha à dificuldade percebida da tarefa. Use animações para sinalizar que um processo de IA ocorreu.
Não:surpreenda os usuários com substituições instantâneas da interface.
Permitir que os usuários naveguem e desfaçam edições de IA rapidamente
Vale para: todas as APIs.
Faça o seguinte:equipe sua interface com um stepper ou um histórico de navegação que permita aos usuários explorar diferentes resultados com confiança e desfazer rapidamente as edições de IA. Isso garante que diferentes versões ainda estejam disponíveis.
Não:substitua o rascunho anterior do usuário ou um resultado de IA que ele possa ter gostado sem uma maneira de voltar, reverter ou comparar versões.
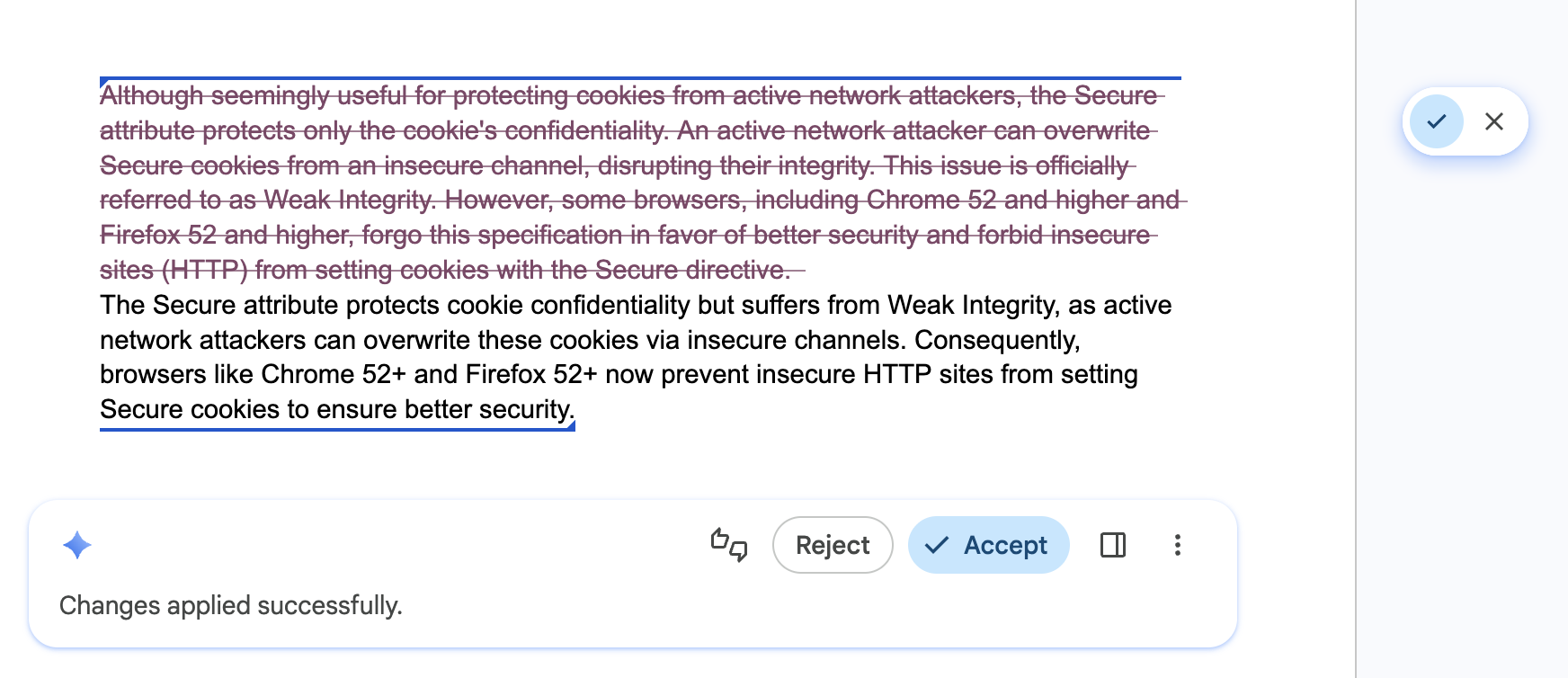
Capacitar o controle e as substituições do usuário
Vale para: todas as APIs.
Faça o seguinte:deixe o usuário como editor final de todo o conteúdo gerado. Forneça substituições intuitivas para que o usuário mantenha a propriedade total da saída final. As APIs podem produzir resultados incorretos.
Restrição:não force um resultado gerado por IA como a única opção.
Armazenar em cache os resultados de tarefas repetidas
Vale para: todas as APIs.
Faça o seguinte:implemente um cache de resultados local (por exemplo, usando sessionStorage ou
IndexedDB) para entradas ou consultas repetidas. Normalize a entrada removendo espaços em branco e convertendo para minúsculas para aumentar as ocorrências em cache. Para entradas pesadas, como imagens, gere um hash para usar como chave de cache. Defina um time to live (TTL) conservador para o cache ou disponibilize resultados armazenados em cache enquanto os atualiza em segundo plano. Permita que o usuário acione uma nova inferência se o resultado for
insatisfatório.
Não:execute a mesma inferência para uma consulta de pesquisa repetida ou uma entrada de dados idêntica em que a variabilidade não é desejável, por exemplo, quando um usuário navega para frente e para trás entre os resultados da pesquisa. Isso otimiza a capacidade de resposta e o uso eficiente da computação local.
// ✅ DO: Check a local cache before running inference
async function getAiResponse(userInput, forceRefresh = false) {
// Normalize the query to increase cache hits
const query = userInput.trim().toLowerCase();
const cacheKey = `ai_results_${query}`;
const TTL_MS = 3600000; // 1 hour conservative TTL
if (!forceRefresh) {
const itemStr = localStorage.getItem(cacheKey);
if (itemStr) {
const item = JSON.parse(itemStr);
const now = Date.now();
// Check if the item has expired
if (now < item.expiry) {
// Lightweight safety check before rendering
if (isValid(item.value)) return item.value;
} else {
// Delete the stale entry if the TTL has passed
localStorage.removeItem(cacheKey);
}
}
}
// Fallback: Run inference if no valid cache exists
const session = await LanguageModel.create();
const response = await session.prompt(userInput);
// Store the result for future use (with an expiration)
const cacheData = {
value: response,
expiry: Date.now() + TTL_MS
};
localStorage.setItem(cacheKey, JSON.stringify(cacheData));
return response;
}