

Xuất bản: Ngày 30 tháng 4 năm 2026
Với AI tích hợp, trang web hoặc ứng dụng web của bạn có thể thực hiện các tác vụ dựa trên AI mà không cần triển khai, quản lý hoặc tự lưu trữ các mô hình. Bạn có thể gặp khó khăn khi chuyển từ bản minh hoạ sang một tính năng sẵn sàng cho sản xuất. Tài liệu này đề cập đến các yếu tố kỹ thuật và trải nghiệm người dùng để giúp bạn tránh những sai lầm thường gặp.
Chuẩn bị mô hình vào thời điểm hợp lý
Áp dụng cho: tất cả các API, ví dụ: Summarizer, Translator và Writer.
Nên: Khởi tạo phiên ngay khi bạn xác định rõ ý định của người dùng là sử dụng tính năng AI, ví dụ: khi người dùng chuyển đến một giao diện công cụ AI có liên quan, di chuột qua một không gian làm việc AI hoặc tương tác với giao diện người dùng xung quanh tính năng. Việc làm nóng trước phiên cho phép mô hình tải vào bộ nhớ một cách âm thầm ở chế độ nền trong khi người dùng đang thiết lập tác vụ của họ, loại bỏ độ trễ khởi động lạnh có thể tránh được. Hãy cố gắng đi trước một bước bằng cách bắt đầu tác vụ AI có khả năng xảy ra tiếp theo ngay khi bạn bắt đầu hiển thị kết quả hiện tại, ví dụ: nếu tính năng được thiết kế để sử dụng lặp đi lặp lại.
Không nên: Trừ phi cần thiết, đừng đợi người dùng nhấp vào "Tạo" để khởi động phiên. Điều này dẫn đến độ trễ khởi động nguội, vì mô hình phải tải lần đầu vào bộ nhớ và chuẩn bị quy trình thực thi.
Đặt câu lệnh ban đầu trong quá trình tạo
Áp dụng cho: Prompt API.
Nên: Cung cấp hướng dẫn cho hệ thống trong quá trình khởi tạo phiên để cải thiện tốc độ của câu lệnh đầu tiên.
Không nên: Bắt đầu bằng một phiên trống và gửi hướng dẫn của hệ thống trong lệnh gọi prompt() đầu tiên. Điều này làm tăng độ trễ vì buộc mô hình phải xử lý các hướng dẫn đó vào phút cuối.
// ✅ DO: Create the session as early as possible (tip on warming up the model early) and use initialPrompts for system instructions in the create call
const session = await LanguageModel.create({
initialPrompts: [
{ role: 'system', content: 'You are a helpful assistant specialized in code reviews.' }
]
});
// A few moments later, when the user triggers the AI feature
const review = await session.prompt(`Review the following code:\n\n${code}`);
// ❌ DON'T: Send instructions using prompt() after creation
// const slowerSession = await LanguageModel.create();
// await slowerSession.prompt(`You are a helpful assistant specialized in code reviews.\n\nReview the following code:\n\n${code}`); // Higher latency
Sao chép phiên cho các tác vụ lặp lại
Áp dụng cho: Prompt API.
Đối với Prompt API, mỗi phiên theo dõi ngữ cảnh của cuộc trò chuyện, có tính đến tất cả các lượt tương tác trước đó. Vì một bản sao sẽ kế thừa mọi thứ từ phiên gốc, bao gồm cả câu lệnh ban đầu và toàn bộ nhật ký tương tác cho đến thời điểm sao chép, hãy cấu trúc cách sử dụng của bạn để chỉ kế thừa những gì bạn cần.
Nên làm:
- Tạo một phiên cơ sở: Để xử lý hiệu quả các tác vụ không liên quan, hãy tạo một phiên cơ sở chỉ chứa các chỉ dẫn hệ thống của bạn và không có ngữ cảnh trò chuyện trước đó.
- Sao chép đường cơ sở: Sử dụng
clone()trên phiên cơ sở đó cho các tác vụ mới để tiết kiệm chi phí phân tích lại hướng dẫn hệ thống. Nhờ đó, bạn có thể tạo các cuộc trò chuyện song song hoặc đặt lại một nhiệm vụ về trạng thái ban đầu.
Không nên:
- Không sử dụng lại cùng một phiên cho các tác vụ không liên quan và tránh sao chép bất kỳ phiên nào đã chứa nhật ký tương tác không cần thiết. Cả hai mẫu này đều có thể khiến ngữ cảnh không liên quan trước đó ảnh hưởng đến nhiệm vụ hiện tại của bạn.
- Đừng gọi
create()nhiều lần bằng các chỉ dẫn hệ thống giống hệt nhau. Thay vào đó, hãy sử dụng mẫu sao chép để tối ưu hoá hiệu suất.
// ✅ DO: Create a baseline session and clone it for each new task
const baseSession = await LanguageModel.create({
initialPrompts: [{
role: 'system',
content: 'You are a technical editor...',
}],
});
// Clone the base session once for the first task
const task1 = await baseSession.clone();
const response1 = await task1.prompt("Review this first draft...");
// ... Repeat the cloning pattern for subsequent independent tasks
// Each task starts fresh from the baseline system instructions
// ❌ DON'T:
// Bad performance pattern: repeated create() calls for identical tasks.
// This forces the model to re-parse instructions every time, increasing latency.
// const sessionA = await LanguageModel.create({ initialPrompts: [...] });
// await sessionA.prompt("Task 1...");
// const sessionB = await LanguageModel.create({ initialPrompts: [...] });
// await sessionB.prompt("Task 2...");
// Bad quality pattern: reusing the same session for unrelated tasks.
// const session = await LanguageModel.create();
// await session.prompt("Analyze this financial report...");
// Unrelated task in the same session:
// await session.prompt("Now write a children's story...");
Huỷ các phiên không dùng đến
Áp dụng cho: Tất cả các API.
Nên: Gọi destroy() một cách rõ ràng trên những phiên mà bạn không cần nữa, để giải phóng bộ nhớ khi một tính năng không còn được sử dụng. Nếu bạn sử dụng mẫu sao chép, hãy giữ phiên cơ sở và huỷ các bản sao mà bạn không còn cần nữa.
Không nên: Duy trì nhiều phiên lớn đang hoạt động. Mỗi phiên đều tiêu tốn bộ nhớ, điều này tạo ra mức sử dụng tài nguyên không cần thiết và có thể trở thành một vấn đề. Các phiên sẽ được trình thu gom rác dọn dẹp một cách tự nhiên, nhưng việc gọi destroy() sẽ giải phóng bộ nhớ nhanh hơn.
// ✅ DO: Use the clone and destroy it immediately after
const clone = await baseSession.clone();
const response = await clone.prompt("Quick task...");
// Free memory right away: destry the clone, keep the baseSession
clone.destroy();
Kết xuất các phản hồi truyền trực tuyến một cách an toàn và hiệu quả
Áp dụng cho: Tất cả API có hỗ trợ truyền phát trực tiếp (Prompt, Summarizer, Writer, Rewriter và Translator).
Nên: Coi tất cả đầu ra của LLM là nội dung không đáng tin cậy. Làm sạch toàn bộ đầu ra kết hợp, không chỉ các khối, vì mã độc có thể được chia thành nhiều bản cập nhật. Trước khi hiển thị, hãy sử dụng Sanitizer API (nếu được hỗ trợ). Để tránh giảm hiệu suất, hãy sử dụng trình phân tích cú pháp Markdown truyền trực tuyến như streaming-markdown.
Không nên: Đặt trực tiếp innerHTML cho mỗi lần cập nhật khối. Điều này diễn ra chậm, đặc biệt là với định dạng phức tạp như làm nổi bật cú pháp và dễ bị tấn công bằng cách chèn mã độc.
import * as smd from "streaming-markdown";
// Set up virtual buffer and Sanitizer API
const sanitizer = new Sanitizer({
allowElements: ['figure', 'figcaption', 'p', 'br', 'strong', 'em', 'img', 'a'],
allowAttributes: {
'loading': ['img'], 'decoding': ['img'], 'src': ['img'], 'href': ['a']
}
});
// Create an off-screen fragment so the parser doesn't cause flicker
// or trigger XSS in the live DOM during the building process.
const buffer = new DocumentFragment();
const parser = smd.parser_new(buffer);
// Use sanitizer as a gatekeeper / cleaner function so we can combine it with the streaming Markdown parser
function syncSanitized(target, sourceFragment) {
// .sanitize() returns a fresh, clean DocumentFragment
const cleanFragment = sanitizer.sanitize(sourceFragment);
// replaceChildren is the modern high-performance way to swap DOM content
target.replaceChildren(cleanFragment);
}
// Streaming Logic
// `chunks` keeps track of the raw string (useful for logs/debug)
chunks += chunk;
// Let the parser build the DOM incrementally in the buffer.
// This is high-performance because the buffer is not live
smd.parser_write(parser, chunk);
// Use the Sanitizer API to port the content safely to the container.
syncSanitized(container, buffer);
Tối ưu hoá dữ liệu đầu vào để tăng tốc độ
Áp dụng cho: Tất cả các API.
Nên: Chỉ truyền cho mô hình những gì thực sự cần thiết. Loại bỏ mọi thứ không liên quan đến nhiệm vụ hiện tại. Đối với các tập dữ liệu lớn, hãy cung cấp thông tin tổng quan ngắn gọn và một số ít mục có liên quan.
Không: Gửi văn bản thô chưa xử lý, siêu dữ liệu không cần thiết, thẻ HTML hoặc danh sách lớn chưa được lọc đến các API. Độ trễ tăng đáng kể theo kích thước đầu vào, điều này có thể khiến tính năng AI có vẻ như bị hỏng trên nhiều thiết bị.
// ✅ DO: Send only relevant text
const cleanText = document.querySelector('#article').innerText;
const summary = await Summarizer.summarize(cleanText);
// ❌ DON'T: Send the entire DOM structure
// const dirtyText = document.querySelector('#article').innerHTML;
Sử dụng đầu ra có cấu trúc để có kết quả có thể dự đoán
Áp dụng cho: Prompt API.
Nên: Khi bạn cần mô hình trả về dữ liệu ở một định dạng cụ thể, hãy sử dụng đầu ra có cấu trúc bằng cách cung cấp một trường responseConstraint để cung cấp một lược đồ JSON. Điều này đảm bảo đầu ra có thể dự đoán được và giúp bạn không cần xử lý hậu kỳ phức tạp hoặc phân tích cú pháp theo cách thủ công.
Không nên: Chỉ dựa vào hướng dẫn bằng ngôn ngữ tự nhiên (chẳng hạn như "chỉ xuất JSON"). Các mô hình có thể bao gồm từ đệm trong cuộc trò chuyện làm hỏng trình phân tích cú pháp của bạn.
// ✅ DO: Use a JSON Schema for predictable results
const schema = {
type: "object",
properties: {
isTopicCats: { type: "boolean" }
}
};
const result = await session.prompt(`Is this post about cats?\n\n${post}`, {
responseConstraint: schema,
});
console.log(JSON.parse(result).isTopicCats);
Tách riêng việc tạo video khỏi các quy định hạn chế về thời lượng
Áp dụng cho: Prompt API, vì đây là API duy nhất hỗ trợ các giản đồ đầu ra có cấu trúc.
Nên: Cho phép mô hình tạo phản hồi một cách tự nhiên, sau đó sử dụng logic phía máy khách để cắt bớt văn bản cho phù hợp với giao diện người dùng của bạn.
Không: Thực thi giới hạn nghiêm ngặt về ký tự như maxLength: 125 bằng cách sử dụng sơ đồ đầu ra có cấu trúc. Khi câu trả lời của một mô hình dài hơn giới hạn mà bạn đặt, mô hình đó có thể chuyển sang các mã thông báo có mật độ cao như ngôn ngữ nước ngoài hoặc biểu tượng cảm xúc để nén ý nghĩa, dẫn đến đầu ra vô nghĩa.
/* DO: Handle overflow using CSS */
.result {
overflow: hidden;
white-space: nowrap;
text-overflow: ellipsis; /* Displays '…' */
}
// ❌ DON'T: Force length in the prompt
const result = await session.prompt("Write a bio in exactly 50 characters.");
Thông báo cho người dùng
Áp dụng cho: Tất cả các API.
Nên: Tuỳ thuộc vào độ phức tạp và thời gian dự kiến của tác vụ, hãy sử dụng ảnh động, tín hiệu trực quan và chỉ báo tiến trình để thông báo cho người dùng. Phương pháp tối ưu phụ thuộc vào trường hợp sử dụng và độ dài dự kiến của đầu ra API. Một số ý tưởng:
- Phát trực tuyến nội dung dài: Đối với nội dung tóm tắt hoặc cuộc trò chuyện, tính năng phát trực tuyến sẽ tạo hiệu ứng máy đánh chữ cho mỗi mã thông báo theo mặc định. Điều này có thể tạo cảm giác tự nhiên và cung cấp ý kiến phản hồi ngay lập tức.
- Không truyền trực tuyến cho các tác vụ ngắn (hoặc các tác vụ không đồng bộ dài): Đối với các đầu ra ngắn, chẳng hạn như văn bản thay thế, việc không truyền trực tuyến có thể tạo ra giao diện người dùng tinh tế hơn. Thao tác này cũng cung cấp thời gian để chuẩn bị trước một cách suy đoán cho tác vụ AI tiếp theo trong khi tác vụ hiện tại đang kết xuất. Phương pháp này cũng áp dụng cho các tác vụ không đồng bộ hoặc tác vụ chạy nền dài hơn. Nếu người dùng không bị chặn trên đầu ra để tiếp tục hành trình của mình, thì không cần thiết phải tạo đầu ra ngay lập tức. Cho biết rằng quá trình này đang diễn ra trong giao diện người dùng.
- Hiệu ứng chuyển đổi trực quan cho nội dung cập nhật: Khi dịch hoặc viết lại văn bản, hãy sử dụng ảnh động, ví dụ: biến đổi từ.
Không nên: Cập nhật giao diện người dùng mà không có tín hiệu trực quan.
Phù hợp với mô hình tinh thần của người dùng về thời gian và công việc
Áp dụng cho: Tất cả các API.
Nên: Cân nhắc việc tạo độ trễ giả tạo từ 1 đến 2 giây nếu phản hồi gần như tức thì. Nghe có vẻ mâu thuẫn, nhưng người dùng có thể thấy kết quả đáng tin cậy hơn khi họ nhận thấy quy trình tạo kết quả phù hợp với mức độ khó mà họ cảm nhận được của nhiệm vụ. Sử dụng ảnh động để báo hiệu rằng một quy trình AI đã diễn ra.
Không: Gây bất ngờ cho người dùng bằng cách thay thế giao diện người dùng ngay lập tức.
Cho phép người dùng nhanh chóng di chuyển và huỷ các thao tác chỉnh sửa bằng AI
Áp dụng cho: Tất cả các API.
Nên: Trang bị cho giao diện người dùng của bạn một bộ điều khiển từng bước hoặc nhật ký điều hướng cho phép người dùng tự tin khám phá các kết quả khác nhau và cho phép họ nhanh chóng huỷ các nội dung chỉnh sửa bằng AI. Điều này giúp đảm bảo rằng các phiên bản khác nhau vẫn luôn có sẵn.
Không nên: Ghi đè bản nháp trước đó của người dùng hoặc kết quả do AI tạo mà họ có thể thích mà không có cách nào để quay lại, hoàn nguyên hoặc so sánh các phiên bản.
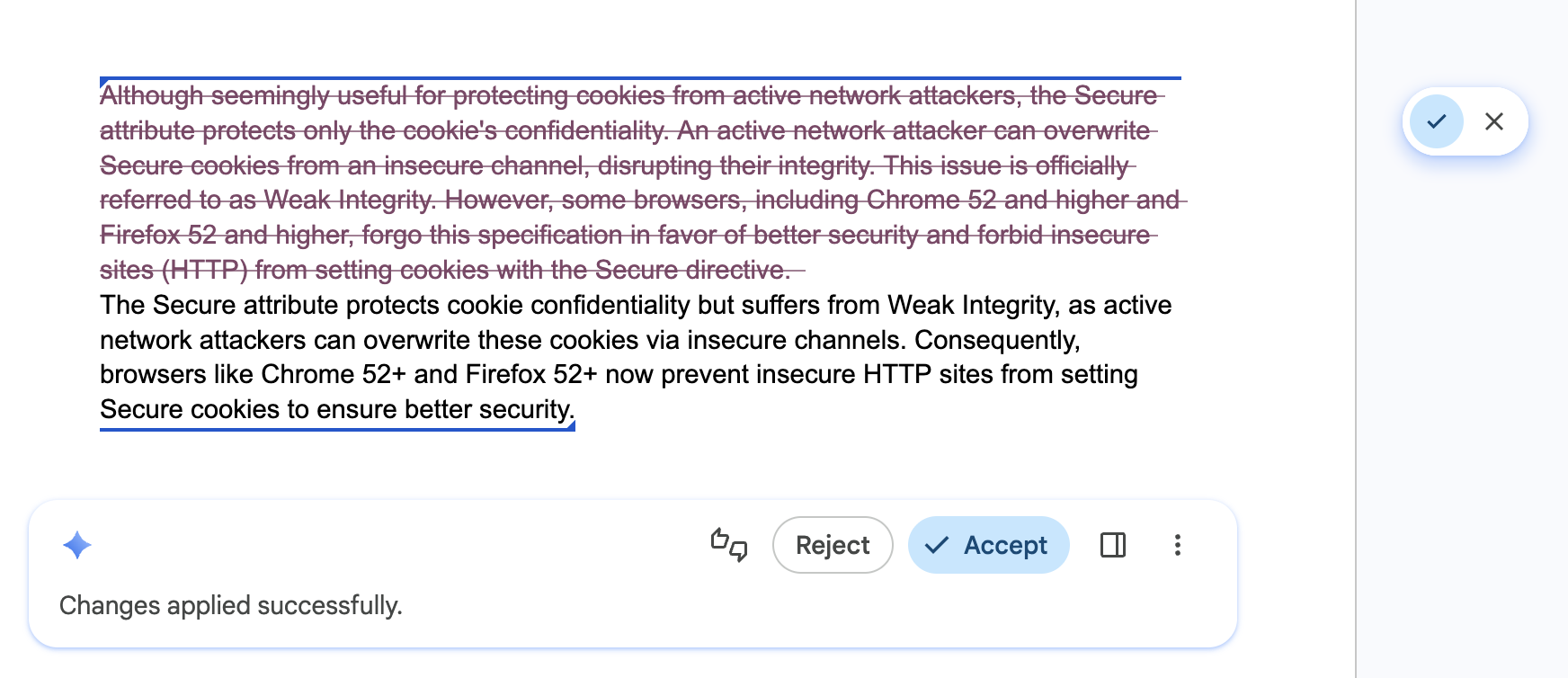
Giúp người dùng kiểm soát và ghi đè
Áp dụng cho: Tất cả các API.
Nên: Chỉ định người dùng làm người chỉnh sửa cuối cùng của tất cả nội dung được tạo. Cung cấp các chế độ ghi đè trực quan để người dùng duy trì toàn quyền sở hữu đối với kết quả cuối cùng. Các API này có thể đưa ra kết quả không chính xác.
Không nên: Chỉ đưa ra kết quả do AI tạo.
Lưu kết quả vào bộ nhớ đệm cho các tác vụ lặp lại
Áp dụng cho: Tất cả các API.
Nên: Triển khai bộ nhớ đệm kết quả cục bộ (ví dụ: sử dụng sessionStorage hoặc IndexedDB) cho các truy vấn hoặc thông tin đầu vào lặp lại. Chuẩn hoá dữ liệu đầu vào bằng cách cắt khoảng trắng và chuyển thành chữ thường để tăng số lượt truy cập vào bộ nhớ đệm. Đối với các đầu vào có kích thước lớn (ví dụ: hình ảnh), hãy tạo một hàm băm để dùng làm khoá bộ nhớ đệm. Đặt thời gian tồn tại (TTL) thận trọng cho bộ nhớ đệm của bạn (hoặc phân phát kết quả được lưu vào bộ nhớ đệm trong khi cập nhật chúng ở chế độ nền). Cho phép người dùng kích hoạt một suy luận mới nếu kết quả không thoả mãn.
Không: Chạy lại cùng một suy luận cho một cụm từ tìm kiếm lặp lại hoặc dữ liệu đầu vào giống hệt nhau khi không mong muốn có sự thay đổi, chẳng hạn như khi người dùng di chuyển qua lại giữa các kết quả tìm kiếm. Điều này giúp tối ưu hoá khả năng phản hồi và sử dụng hiệu quả tài nguyên điện toán cục bộ.
// ✅ DO: Check a local cache before running inference
async function getAiResponse(userInput, forceRefresh = false) {
// Normalize the query to increase cache hits
const query = userInput.trim().toLowerCase();
const cacheKey = `ai_results_${query}`;
const TTL_MS = 3600000; // 1 hour conservative TTL
if (!forceRefresh) {
const itemStr = localStorage.getItem(cacheKey);
if (itemStr) {
const item = JSON.parse(itemStr);
const now = Date.now();
// Check if the item has expired
if (now < item.expiry) {
// Lightweight safety check before rendering
if (isValid(item.value)) return item.value;
} else {
// Delete the stale entry if the TTL has passed
localStorage.removeItem(cacheKey);
}
}
}
// Fallback: Run inference if no valid cache exists
const session = await LanguageModel.create();
const response = await session.prompt(userInput);
// Store the result for future use (with an expiration)
const cacheData = {
value: response,
expiry: Date.now() + TTL_MS
};
localStorage.setItem(cacheKey, JSON.stringify(cacheData));
return response;
}