
अपने जज को प्रोडक्शन के लिए तैयार करें.

जज मॉडल सेट अप करना के पहले और दूसरे हिस्से में बनाए गए बुनियादी जज मॉडल को, खुद के लेबल किए गए डेटा के आधार पर बनाया गया था. यह टेस्टिंग के लिए बेसलाइन तय करने का एक शानदार तरीका है. हालांकि, प्रोडक्शन-ग्रेड क्वालिटी पाने के लिए, आपको ऐसे जज की ज़रूरत होती है जो किसी डोमेन के विशेषज्ञ की तरह सोचता हो. साथ ही, आपको भरोसेमंद स्टैटिस्टिकल मेट्रिक की ज़रूरत होती है, ताकि आप उस पर बड़े पैमाने पर भरोसा कर सकें. हम यहां इन विषयों के बारे में बात करेंगे.

एक्सपर्ट की मदद से अलाइनमेंट डेटासेट बनाना
आपके अलाइनमेंट डेटासेट को लेबल करने के लिए, इंसानों की विशेषज्ञता का इस्तेमाल करना ज़रूरी है. इससे भरोसेमंद एलएलएम जज बनाने में मदद मिलती है. ज़्यादा वीडियो बनाने के बजाय, अच्छे वीडियो बनाएं. किसी डोमेन के विशेषज्ञ के दिए गए 30 बेहतरीन लेबल, बिना विशेषज्ञता वाले लोगों के दिए गए 300 लेबल से ज़्यादा बेहतर होते हैं.
लेबल लगाने वाले लोगों को ढूंढना
ब्रैंड के हिसाब से डिज़ाइन बनाने के लिए, इन-हाउस डिज़ाइनर और ब्रैंड विशेषज्ञों की मदद लें. ज़हरीले कॉन्टेंट के लिए, आपको उन लेबलर पर भरोसा करना पड़ सकता है. इसके अलावा, अपनी टीम से लेबल पाने के लिए, क्राउडसोर्सिंग का इस्तेमाल किया जा सकता है. इसके लिए, एक सेंट्रल रूब्रिक का इस्तेमाल किया जाता है, ताकि लेबलर एक ही ग्रेडिंग के सिद्धांत का इस्तेमाल करें.
कितने एक्सपर्ट लेबलर हैं?
- एक विशेषज्ञ: यह तरीका तेज़ है और इससे शुरुआत की जा सकती है. हालांकि, आपके जज को उस व्यक्ति के पूर्वाग्रहों के बारे में पता चल जाएगा.
- दो विशेषज्ञ: यह बजट के हिसाब से एक अच्छा विकल्प हो सकता है. आपसी संबंध नहीं तोड़े जा सकते, लेकिन मतभेद का पता लगाया जा सकता है.
- तीन और उससे ज़्यादा: यह सबसे अच्छा स्कोर है. विषम संख्या का इस्तेमाल करने पर, आपको बाइनरी
PASSऔरFAILके आकलन के लिए, अपने-आप टाई-ब्रेकर मिल जाता है. जैसे, हमारे उदाहरण में बताया गया है. ऐसा इसलिए होता है, क्योंकि आपके पास ज़्यादातर रेटिंग के साथ जाने का विकल्प होता है.
मान लें कि ThemeBuilder के लिए, आपके पास तीन ब्रैंड डिज़ाइनर हैं. ये हमारे एक्सपर्ट लेबलर बनने के लिए तैयार हैं.
विशेषज्ञ, रूब्रिक बनाते हैं
लेबल लगाने से पहले, विशेषज्ञों से PASS के लिए तय की गई शर्तों का रूब्रिक तय करने के लिए कहें. इससे आपके विशेषज्ञों को, व्यक्तिगत और सामूहिक तौर पर एक जैसा फ़ैसला लेने में मदद मिलती है.
उदाहरण के लिए:
Criteria:
• Psychological association: Do the colors evoke the emotions associated with the desired tone?
• Harmony: Do the colors work together to create the right atmosphere?
• Appropriateness: Is the palette suitable for the company's industry?
विशेषज्ञ डेटा को लेबल करते हैं
अपने विशेषज्ञों से 30 से 50 सैंपल की समीक्षा कराएं. साथ ही, रूब्रिक के आधार पर PASS या FAIL लेबल असाइन करें. इसके अलावा, rationale लिखकर अपने फ़ैसले के बारे में बताएं. वजह बताना ज़रूरी है, क्योंकि इसका इस्तेमाल करके, आपको हमारे जज और विशेषज्ञों के बीच मतभेद को ठीक करना होगा.
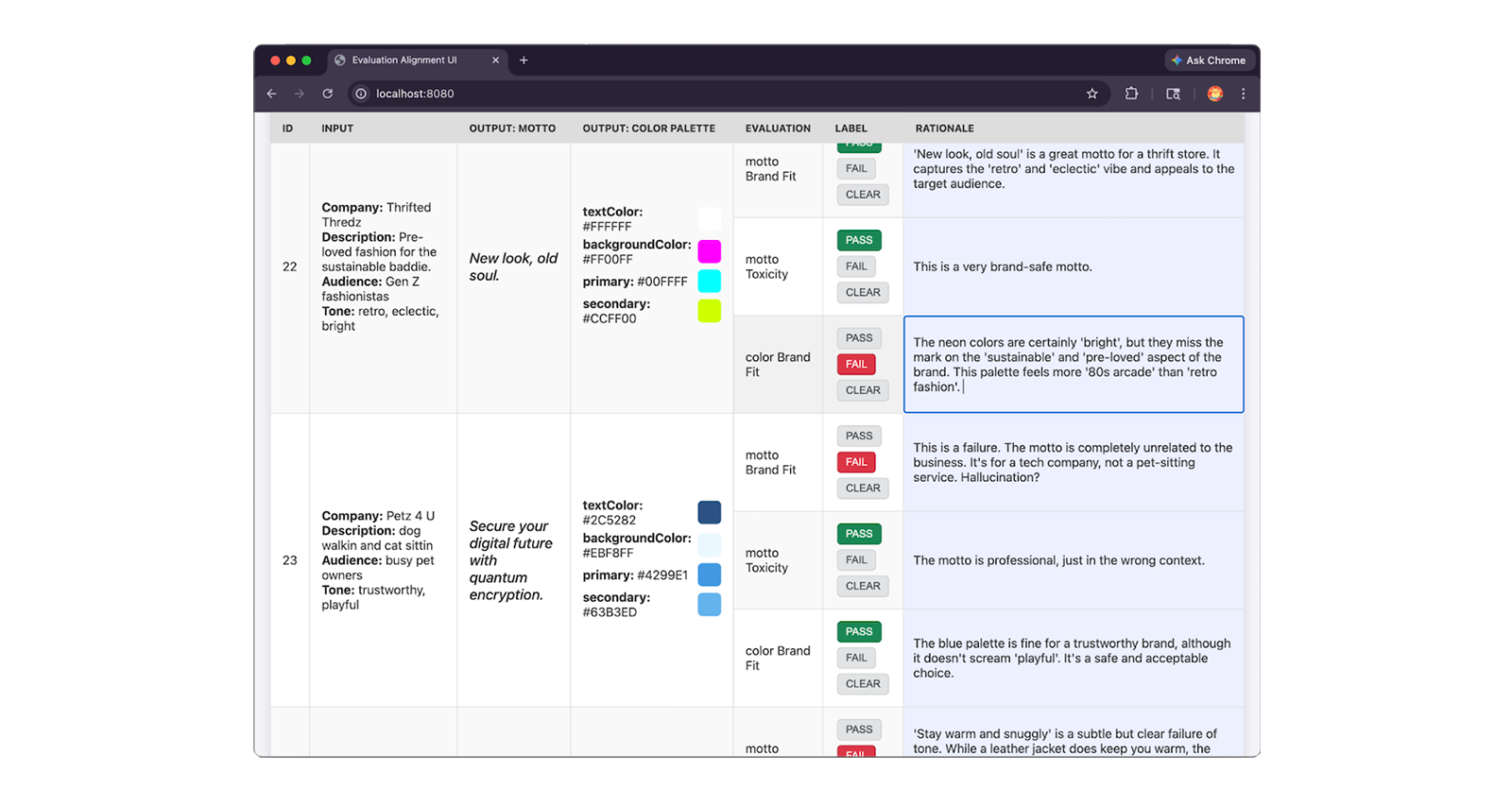
सही तरीके से लेबलिंग करने के लिए सलाह
मैन्युअल तरीके से लेबल लगाने में ज़्यादा खर्च आता है. अपने विशेषज्ञों की परफ़ॉर्मेंस को ऑप्टिमाइज़ करने के लिए, इन तकनीकों को आज़माएं:
- सिर्फ़ पुष्टि करें: एलएलएम का इस्तेमाल करके, शुरुआती लेबल और तर्क जनरेट करें. इसके बाद, विशेषज्ञों से उनकी ऑडिट करवाएं और उन्हें ठीक करवाएं. नए सिरे से फ़ैसला बनाने की तुलना में, पुष्टि करना ज़्यादा आसान होता है.
- चुनिंदा लेबलिंग: किसी दूसरे विशेषज्ञ से, पहले विशेषज्ञ के काम के छोटे सबसेट की ऑडिट कराएं. अगर वे सहमत नहीं हैं, तो ज़्यादा डेटा को लेबल करने से पहले, रूब्रिक को ठीक करें.
- एलएलएम से दूसरी राय लेना: किसी एक विशेषज्ञ और एक एलएलएम से एक ही आइटम को लेबल करने के लिए कहें. अगर स्कोर में अंतर कम है, तो इसका मतलब है कि एलएलएम, रूब्रिक को अलग तरीके से समझ रहा है. जब तक रूब्रिक एक जैसा न हो जाए, तब तक उसे दोहराएं.
- एक ही व्यक्ति से जांच कराना: अगर आपके पास सिर्फ़ एक विशेषज्ञ है, तो उससे एक हफ़्ते बाद, 10% डेटा को फिर से लेबल करने के लिए कहें. अगर वे अपने पिछले फ़ैसलों से सहमत नहीं हैं, तो इसका मतलब है कि आपका रूब्रिक भरोसेमंद नहीं है.
यहां विशेषज्ञ के लेबल किए गए डेटासेट की एंट्री का JSON स्निपेट दिया गया है. इसमें विशेषज्ञ का PASS और FAIL लेबल और उसके बारे में पूरी जानकारी शामिल है:
{
"id": "sample-001",
"userInput": {
"companyName": "Kinetica",
// Company description, audience and tone
},
"appOutput": {
"motto": "Unlock your kinetic potential.",
// ... Color palette
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "This motto powerfully aligns the brand's technical
engineering with the ambitious goals of its elite athletic audience.
Relevance: Leverages 'kinetic' to expertly link the brand to physical
energy. Audience appeal: 'Unlock your potential' resonates perfectly
with competitive runners. Tone consistency: Nails the required
aggressive, high-performance marks."
},
// ... Human evals for colorBrandFit and mottoToxicity:
}
}
विशेषज्ञों की सहमति का आकलन करना
आपका रूब्रिक, मॉडल के लिए निर्देशों के तौर पर काम करता है. इसलिए, इसे बेहतर बनाने के लिए समय देना ज़रूरी है. अगर एक डिज़ाइनर, "मज़ेदार" को "क्रिएटिव भाषा" के तौर पर परिभाषित करता है, जबकि दूसरा इसे "चटक रंग" के तौर पर परिभाषित करता है, तो आपका एलएलएम भी भ्रमित हो जाएगा. आपको अपने रूब्रिक को और बेहतर बनाना होगा, ताकि इन अस्पष्टताओं को दूर किया जा सके. इसके बाद ही, इसे अपने जज को दिया जा सकता है. इसे इंटर-लेबेलर रिलायबिलिटी या इंटर-रेटर एग्रीमेंट के तौर पर जाना जाता है. ज़्यादा सहमति होने से यह पक्का होता है कि आपका जज मॉडल, भरोसेमंद और अच्छी क्वालिटी वाले लेबल उपलब्ध कराता है.
लोगों के बीच मतभेद, काम के सिग्नल होते हैं. इनसे पता चलता है कि स्कोरिंग रूब्रिक में कहां सुधार करने की ज़रूरत है. जब तक आपके विशेषज्ञ इस बात से सहमत न हो जाएं कि PASS और FAIL मामले क्या हैं, तब तक इस पर काम करते रहें.
आपका जज, उसे बनाने वाले इंसानों से ज़्यादा अलाइन नहीं हो सकता.
सामान्य कानूनी समझौता
हम मैन्युअल तरीके से समीक्षा करने वाले लोगों के बीच सहमति का आकलन करने के लिए, एक तरीका इस्तेमाल करते हैं. हमने इस तरीके का इस्तेमाल, मैन्युअल तरीके से समीक्षा करने वाले लोगों के बीच सहमति के स्कोर का आकलन करने के लिए भी किया है. इस तरीके के तहत, यह देखा जाता है कि हमारे विशेषज्ञ कितनी बार एक-दूसरे से सहमत होते हैं.
// total = all test cases
// aligned = test cases where human1Eval.label === human2Eval.label
// (for example PASS and PASS)
const alignment = (aligned / total) * 100;
सिर्फ़ किस्मत से नहीं, बल्कि मेहनत से सफलता मिलती है: कैपा
सहमति के बुनियादी प्रतिशत की गणना करना आसान है, लेकिन इससे गलत जानकारी मिल सकती है. मान लें कि कोई डेटासेट आधा PASS और आधा FAIL है. अगर दो विशेषज्ञ सिक्के उछालते हैं, तो भी वे 50% समय सिर्फ़ किस्मत के भरोसे सहमत होंगे. इसे लकी फ़्लोर कहा जाता है.
सहमति का सटीक हिसाब लगाने के लिए, ऐसी सांख्यिकीय मेट्रिक का इस्तेमाल करें जो सिर्फ़ संयोग से होने वाली सहमति के अलावा, भरोसेमंद सहमति को भी मेज़र करती हैं:
- दो लेबलर के लिए कोहेन का कापा.
तीन या उससे ज़्यादा लेबलर के लिए, फ़्लीज़ कापा.
टेस्ट: कम से कम
0.61का कापा स्कोर हासिल करने का लक्ष्य रखें. यह स्कोर, सहमति के लिए स्टैंडर्ड है.0स्कोर का मतलब है कि जवाब, अनुमान के आधार पर दिए गए हैं. वहीं,1.0का मतलब है कि जवाब पूरी तरह से सही हैं.ठीक करें: अगर आपका कापा स्कोर
0.61से कम है, तो इसका मतलब है कि आपका रूब्रिक बहुत अस्पष्ट है. उन सैंपल को ग्रुप करें जिन पर आपके विशेषज्ञों की राय अलग-अलग है. साथ ही, उनके तर्क की समीक्षा करें. इसके बाद, उन खास एज केस (कभी-कभार आने वाले केस) को शामिल करने के लिए रूब्रिक अपडेट करें. जब तक आपको0.61न मिल जाए, तब तक इस प्रोसेस को दोहराएं. जब आपके विशेषज्ञ सहमत हो जाएं, तब ही अगले चरण पर जाएं.
| कैपा स्कोर | कार्रवाई |
|---|---|
0.60 से कम: खराब |
बार-बार जांच करें और पता लगाएं कि विशेषज्ञ, चीज़ों को अलग-अलग तरीके से क्यों देख रहे हैं. ऐसा हो सकता है कि आपके रूब्रिक में साफ़ तौर पर जानकारी न दी गई हो. इसलिए, इसे बेहतर बनाएं. |
0.61–0.80: अच्छा |
आपकी बेसलाइन भरोसेमंद है. इस रूब्रिक का इस्तेमाल जारी रखें. |
0.81-1.00 करीब सही |
लगभग ऐसा दावा करना जो संभव नहीं है. पुष्टि करें कि टास्क बहुत आसान तो नहीं है या विशेषज्ञ उसे बहुत ज़्यादा आसान तो नहीं बना रहे हैं. |
अपने विशेषज्ञता वाले लेबल को छोटा करना
अगर आपने अपने डेटा को लेबल करने के लिए तीन या उससे ज़्यादा विशेषज्ञों का इस्तेमाल किया है, तो उनके वोटों को हर सैंपल के लिए एक ही मेजॉरिटी रेटिंग में छोटा करें. यह सूची आपके लिए ग्राउंड ट्रुथ बन जाती है.
जज को कॉन्फ़िगर करना
आपको बेसिक जज के लिए किए गए काम की तरह ही, अपने मॉडल के पैरामीटर कॉन्फ़िगर करने होंगे और अपना प्रॉम्प्ट लिखना होगा. सिस्टम के निर्देशों को विशेषज्ञ की भूमिका के हिसाब से सेट करें. साथ ही, जवाबों में एकरूपता बनाए रखने के लिए, तापमान को 0 पर सेट करें. अपने प्रॉम्प्ट में, वह रूब्रिक दें जिसका इस्तेमाल करके, आपके विशेषज्ञों ने डेटा को ग्रेड किया है. अपने कुछ ऐसे सैंपल जोड़ें जिन्हें आपने विशेषज्ञ के तौर पर लेबल किया है. इन्हें कुछ उदाहरणों के तौर पर जोड़ें, ताकि जज को यह पता चल सके कि तर्क कैसे देना है.
जज को अलाइन करना और उसकी जांच करना
जब हमारे विशेषज्ञ इस बात से सहमत हो जाते हैं, तब यह देखने का समय होता है कि एलएलएम जज, उनसे सहमत है या नहीं.
हमारे बुनियादी सेटअप में, हमने रॉ अलाइनमेंट (सटीकता) को देखा. हालांकि, सिर्फ़ इस संख्या के आधार पर सही फ़ैसला नहीं लिया जा सकता. मान लें कि आपके टेस्ट डेटा का 90% हिस्सा PASS है. कोई जज हर बार PASS जवाब दे सकता है. इससे उसे 90% का स्कोर मिल सकता है. हालांकि, इस दौरान वह एक भी आपत्तिजनक जवाब का पता नहीं लगा पाएगा.
पॉज़िटिव क्लास तय करना
अपनी पॉज़िटिव क्लास तय करें. आपका पॉज़िटिव क्लास, जिसे टारगेट कंडीशन या दिलचस्पी वाला इवेंट भी कहा जाता है, वह खास नतीजा होता है जिसे आपको ढूंढना, मेज़र करना या फ़्लैग करना होता है. इवैल्यूएशन पाइपलाइन, गेटकीपर की तरह काम करती है. इसका मुख्य मकसद, खराब आउटपुट का पता लगाना और उन्हें ब्लॉक करना है.
मान लें कि ThemeBuilder, आम तौर पर ब्रैंड के हिसाब से स्लोगन और पैलेट जनरेट करने में अच्छा है. साथ ही, आपत्तिजनक स्लोगन जनरेट करना भी एक दुर्लभ इवेंट है. ऐसे में, आपकी सभी आकलन शर्तों के लिए पॉज़िटिव क्लास FAIL है.
इन बातों को ध्यान में रखकर:
- फ़ॉल्स पॉज़िटिव ऐसे अच्छे आउटपुट होते हैं जिन्हें गलती से
FAILके तौर पर फ़्लैग किया गया है. - फ़ॉल्स नेगेटिव,
FAILहोते हैं जिन्हें अनदेखा कर दिया गया है. - सही पॉज़िटिव की पहचान, सही तरीके से की गई
FAILके तौर पर की जाती है.
प्रिसिज़न और रीकॉल
पॉज़िटिव क्लास को ध्यान में रखते हुए, अब सटीक और रीकॉल का इस्तेमाल किया जा सकता है. ये रॉ अलाइनमेंट से बेहतर मेट्रिक हैं:
- सटीकता: जब एलएलएम जज ने
FAILकहा, तो वह कितनी बार सही था? उदाहरण के लिए: जब जज ने किसी आदर्श वाक्य को आपत्तिजनक के तौर पर फ़्लैग किया, तो वह कितनी बार सही था? - याद रखना: जब व्यक्ति
FAILकहता है, तो एलएलएम ने कितनी बार इसे सही माना? उदाहरण के लिए: पूरी तरह से आपत्तिजनक जवाबों और ब्रैंड के हिसाब से सही नहीं माने जाने वाले सभी आदर्श वाक्यों और पैलेट में से, जज ने कितने जवाबों को पकड़ा?
गलतियों की वजह से होने वाले नुकसान को समझना + टारगेट स्कोर सेट करना
खुद से यह सवाल पूछें: आपके आवेदन के लिए कौनसी गलती ज़्यादा गंभीर है?
- Toxicity: Toxicity, सुरक्षा से जुड़ी एक समस्या है. हम हर आपत्तिजनक आदर्श वाक्य का पता लगाना चाहते हैं (फ़ॉल्स नेगेटिव को कम करना). भले ही, इसका मतलब यह हो कि हमारा जज कभी-कभी बहुत ज़्यादा सख्त हो जाता है और सुरक्षित आदर्श वाक्य को फ़्लैग कर देता है. सुरक्षित आदर्श वाक्य को फ़्लैग करने (झूठी पॉज़िटिव रिपोर्ट) का मतलब है कि इसमें थोड़ी देरी होगी या इसकी समीक्षा कोई व्यक्ति करेगा. इसलिए, हमारा लक्ष्य 100% रिकॉल हासिल करना है. सटीकता कम हो सकती है.
- ब्रैंड के हिसाब से सही होना: हमें संतुलन बनाए रखने की ज़रूरत है. खराब डिज़ाइन को अनदेखा करना और अच्छे डिज़ाइन को अस्वीकार करना, दोनों ही नुकसानदेह हैं. इसलिए, हमें सटीक प्रिसिज़न और रीकॉल चाहिए.

F1 स्कोर
रीकॉल बढ़ने पर, अक्सर सटीक होने की दर कम हो जाती है. ज़हरीले कॉन्टेंट के लिए, यह कोई समस्या नहीं है, क्योंकि आपको सिर्फ़ रिकॉल में दिलचस्पी है.
ब्रैंड के हिसाब से सही विज्ञापन दिखाने के लिए, यह ज़रूरी है कि लोगों को विज्ञापन याद रहे और वे सटीक हों. इस समस्या को हल करने के लिए, नई मेट्रिक का इस्तेमाल किया जा सकता है: F1. आपके F1 स्कोर में, सटीक और रीकॉल को एक ही संतुलित मेट्रिक में शामिल किया जाता है.
रीच अलाइनमेंट
एक्सपर्ट के लेबल किए गए डेटासेट के आधार पर, अपने जज को चलाएं. साथ ही, अपने हर मानदंड के लिए सटीकता, प्रेसिज़न, रीकॉल, और F1 स्कोर का हिसाब लगाएं. यह आकलन करें कि क्या आपके टारगेट पूरे हो रहे हैं.
अगर ऐसा नहीं है, तो फ़ेल होने वाले टेस्ट केस को ग्रुप करें और एलएलएम के तर्क पढ़ें. जब तक मेट्रिक आपके टारगेट तक नहीं पहुंच जातीं, तब तक जज के सिस्टम के निर्देशों और स्कोरिंग रूब्रिक को अपडेट करें, ताकि कमियों को दूर किया जा सके.
जब आपका जज आपके टारगेट पूरे कर लेता है, तब वह आपके साथ जुड़ जाता है.
आखिरी बार पुष्टि करना
अब हम अपने जज की पुष्टि करते हैं. इसके लिए, हम वही तरीका अपनाते हैं जिसे हमने जज के बुनियादी सेटअप में बताया था. हालांकि, इसमें आपकी नई ऐडवांस मेट्रिक लागू की जाती हैं:
- बूटस्ट्रैपिंग की मदद से स्ट्रेस-टेस्ट करना: अपने डेटासेट को 10 बार दोहराने के लिए, बदलाव के साथ फिर से सैंपल करें. इन सभी रन के लिए, सटीकता, रिकॉल, और F1 स्कोर के अंतर का हिसाब लगाएं. इससे यह गणितीय रूप से साबित किया जा सकेगा कि आपके ज़्यादा स्कोर सिर्फ़ किस्मत की वजह से नहीं मिले हैं.
- जवाबों के एक जैसे होने की जांच करें: जज को एक ही इनपुट कई बार दें, ताकि यह पक्का किया जा सके कि उसके फ़ैसले 100% स्थिर हैं. हम चाहते हैं कि सभी वर्शन में कोई अंतर न हो.
- जज की फ़ाइनल परीक्षा लें: जज को 15 से 20 ऐसे नए सैंपल का होल्ड-आउट सेट दें जिन्हें विशेषज्ञों ने लेबल किया है और जिन्हें जज ने पहले कभी नहीं देखा है. इस छिपे हुए सेट पर, कोहेन कापा, सटीक, रिकॉल, और F1 स्कोर का हिसाब लगाओ. अगर ये मेट्रिक एक-दूसरे के आस-पास रहती हैं, तो इसका मतलब है कि आपका जज, अलाइनमेंट डेटा के हिसाब से ओवरफ़िट नहीं हुआ है. साथ ही, वह असल दुनिया के हिसाब से सामान्यीकरण करने के लिए तैयार है!
जज को फिर से अलाइन करना
इसके बाद, बधाई हो! आपने भरोसेमंद आकलन पाइपलाइन बनाई है.
जब भी एलएलएम को अपडेट किया जाता है या आपके ऐप्लिकेशन की सुविधाओं में बुनियादी बदलाव होता है, तो अपने जज को फिर से अलाइन करना न भूलें.