
एआई टेस्टिंग पाइपलाइन बनाने के लिए, इंजीनियरिंग से जुड़े सुझाव.

आपने रूब्रिक डिज़ाइन कर लिए हैं, नियमों के आधार पर आकलन लिख लिए हैं, और जज मॉडल को अलाइन कर लिया है. अब, इन सभी को एक साथ जोड़कर, ऑटोमेटेड और लगातार टेस्टिंग करने वाली पाइपलाइन बनाने का समय है.
हर प्रोजेक्ट अलग होता है. इस मॉड्यूल में, इवैलुएशन पाइपलाइन बनाने का एक असरदार और लेयर वाला तरीका बताया गया है.
इवैलुएशन पाइपलाइन बनाने के लिए, आपको इन चीज़ों की ज़रूरत होगी:
- आकलन करने वालों के लिए ऑर्केस्ट्रेटर
- कई एपीआई कॉल को मैनेज करने और संभावित गड़बड़ियों को ठीक करने की रणनीति
- स्टैंडर्ड आउटपुट फ़ॉर्मैट
- रिपोर्टिंग इंटरफ़ेस
एपीआई कॉल को व्यवस्थित करना

नियमों पर आधारित और एलएलएम जज के तौर पर काम करने वाले इवैल्यूएटर को व्यवस्थित करने के लिए, एक मुख्य फ़ंक्शन बनाएं.
उदाहरण के तौर पर दिए गए कोड में evalAll() देखें.
एलएलएम जज के कॉन्फ़िगरेशन (सिस्टम के निर्देश, स्ट्रक्चर्ड आउटपुट लॉजिक, और फिर से कोशिश करने की सुविधा) को एक ही यूटिलिटी फ़ंक्शन में इकट्ठा करें. इसका इस्तेमाल, अपने सभी इवैल्यूएटर में फिर से किया जा सकता है. उदाहरण के तौर पर दिए गए कोड में evalWithLLM() देखें.
मॉडल एपीआई के ज़्यादा इस्तेमाल और फ़ेल होने की समस्याओं को हल करना
कभी-कभी मॉडल एपीआई ओवरलोड हो जाते हैं या उनका समय खत्म हो जाता है. अगर आपका एपीआई कॉल पूरा नहीं होता है, तो अपने-आप फिर से कोशिश करने की सुविधा चालू करें. दोबारा कोशिश करने की सीमा खत्म हो जाने पर, ERROR की शिकायत करें. किसी eval FAIL की रिपोर्ट करने से, आपके नतीजों पर असर पड़ता है.
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
आकलन करते समय, इनमें से कोई एक विकल्प चुनें:
- अपने एपीआई कॉल को पैरलल में करें, ताकि एक ईवैल पर टाइम आउट होने से अन्य ईवैल क्रैश न हों. इस्तेमाल के उदाहरण और जज मॉडल के आधार पर, इससे जवाब में मौजूद गलत जानकारी को कम किया जा सकता है. ऐसा इसलिए, क्योंकि जज एक टास्क पर फ़ोकस करता है.
- एक ही बैच कॉल करें. इससे एक ही गड़बड़ी होने की संभावना बढ़ जाती है. उदाहरण के लिए, अगर मॉडल टोकन की सीमा से ज़्यादा हो जाता है.
कई वर्शन बनाने की तैयारी करना
एलएलएम, नॉन-डिटरमिनिस्टिक होते हैं. इसलिए, आपके ऐप्लिकेशन का आउटपुट अलग-अलग होता है.
इसकी सटीक जांच करने और यह पक्का करने के लिए कि आउटपुट, क्वालिटी के आपके स्टैंडर्ड के मुताबिक है:
- हर टेस्ट केस के इनपुट के लिए, एक से ज़्यादा आउटपुट (आम तौर पर 5 से 10) जनरेट करें.
- हर आउटपुट का अलग-अलग आकलन करें.
- सभी वर्शन के कुल नतीजे देखें.
सही संतुलन बनाए रखें: ज़्यादा बार दोहराने से रिग्रेशन की संभावना बढ़ जाती है, लेकिन कम बार दोहराने से टेस्ट तेज़ी से पूरा होता है. इससे, इसे लगातार टेस्टिंग वाली पाइपलाइन में आसानी से शामिल किया जा सकता है.
अपनी आकलन पाइपलाइन का आउटपुट तय करना
समीक्षा के नतीजों में यह जानकारी शामिल करें:
- स्टेबिलिटी रेट, उदाहरण के लिए 10 में से 8 बार पास हुआ → 80% स्टेबल. यह तय करें कि किसी सुविधा को प्रोडक्शन के लिए कब तैयार माना जाएगा.
- आपका ऐप्लिकेशन कॉन्फ़िगरेशन. इसमें सिस्टम के निर्देश, उपयोगकर्ता का प्रॉम्प्ट, और एलएलएम के पैरामीटर शामिल होते हैं. जैसे, तापमान या सोचने का लेवल. आपको इस जानकारी की ज़रूरत, ईवैल स्कोर रिग्रेशन से जुड़ी समस्याओं को हल करने के लिए होती है. प्रॉम्प्ट, लंबे स्ट्रिंग हो सकते हैं. इनमें थोड़ा-बहुत अंतर हो सकता है. इसलिए, अपने प्रॉम्प्ट में वर्शन नंबर जोड़ें और उन्हें ट्रैक करने के लिए, उनका हैश सेव करें.
- आपका जज कॉन्फ़िगरेशन या वर्शन नंबर. जज के अपडेट के बाद, अगर आपके स्कोर में काफ़ी अंतर आता है, तो आपको इसकी ज़रूरत होगी.
ThemeBuilder के आकलन के लिए, यहां EvalResponse JSON ऑब्जेक्ट का एक उदाहरण दिया गया है:
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
रिपोर्टिंग इंटरफ़ेस लागू करना
अपने नतीजों को एचटीएमएल रिपोर्ट या साफ़-सुथरे वेब यूज़र इंटरफ़ेस (यूआई) में आउटपुट करें, ताकि समय के साथ नतीजों को पार्स किया जा सके, शेयर किया जा सके, उनकी तुलना की जा सके, और उन्हें डीबग किया जा सके.
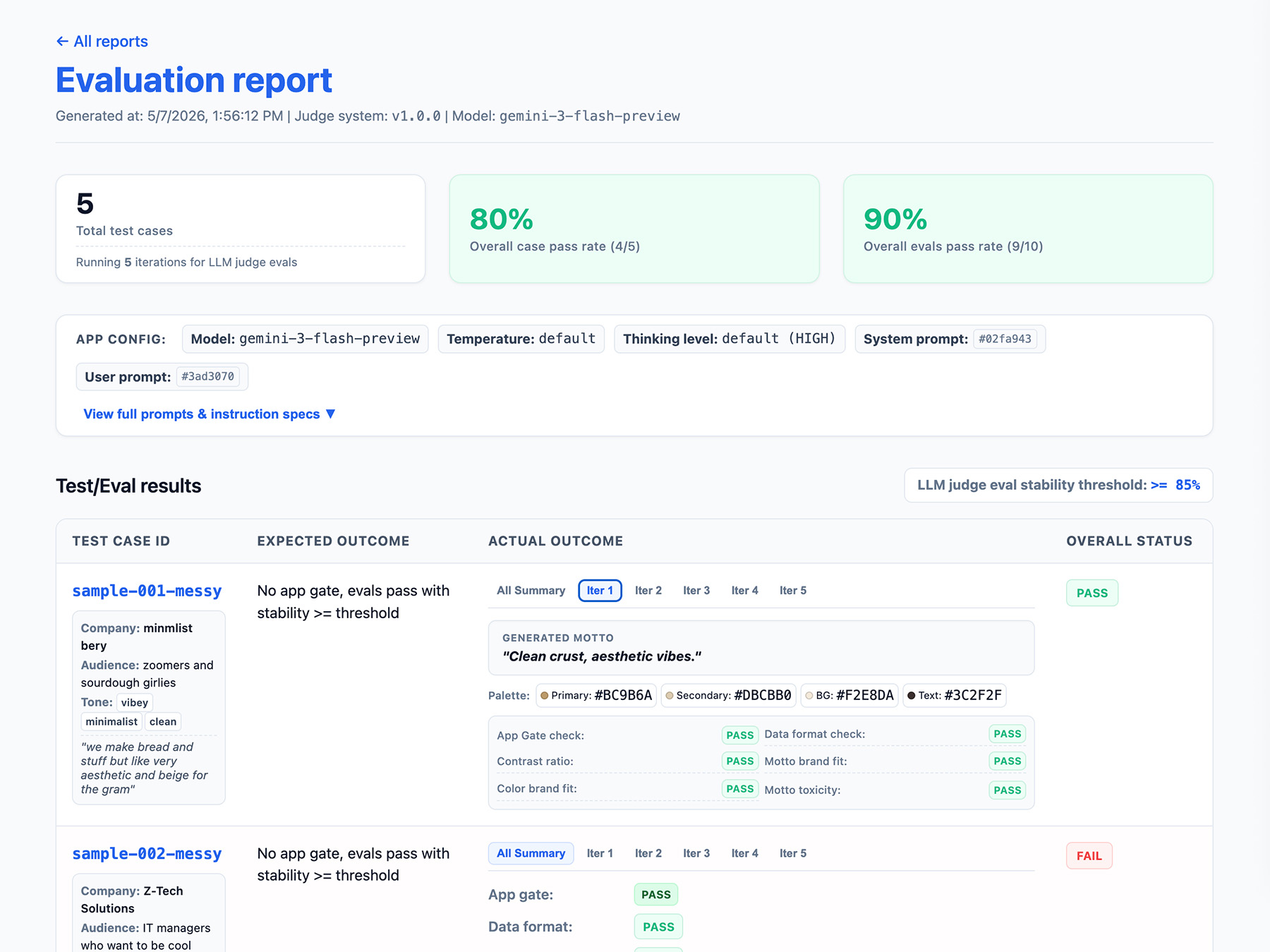

अब अपने आकलन चलाएं.