



تاريخ النشر: 16 مايو 2024
يمكن أن تساعد المراجعات الإيجابية والسلبية المشتري في اتّخاذ قرار الشراء.
تشير الأبحاث الخارجية إلى أنّ% 82 من المتسوّقين على الإنترنت يبحثون بنشاط عن المراجعات السلبية قبل إجراء عملية شراء. تُعدّ هذه المراجعات السلبية مفيدة للعملاء والأنشطة التجارية، إذ يمكن أن يساعد توفّر المراجعات السلبية في خفض معدلات الإرجاع ومساعدة المصنّعين على تحسين منتجاتهم.
في ما يلي بعض الطرق التي يمكنك من خلالها تحسين جودة المراجعات:
- التحقّق من كل مراجعة للتأكّد من أنّها غير سامة قبل إرسالها يمكننا تشجيع المستخدمين على إزالة اللغة المسيئة، بالإضافة إلى الملاحظات الأخرى غير المفيدة، حتى تساعد مراجعاتهم المستخدمين الآخرين بشكل أفضل في اتخاذ قرار شراء مدروس.
- سلبي: هذه الحقيبة سيئة جدًا وأنا أكرهها.
- تعليق سلبي مع ملاحظات مفيدة السحّابات صلبة جدًا والخامة تبدو رخيصة. لقد أرجعتُ هذه الحقيبة.
- إنشاء تقييم تلقائيًا استنادًا إلى اللغة المستخدَمة في المراجعة
- تحديد ما إذا كانت المراجعة سلبية أو إيجابية
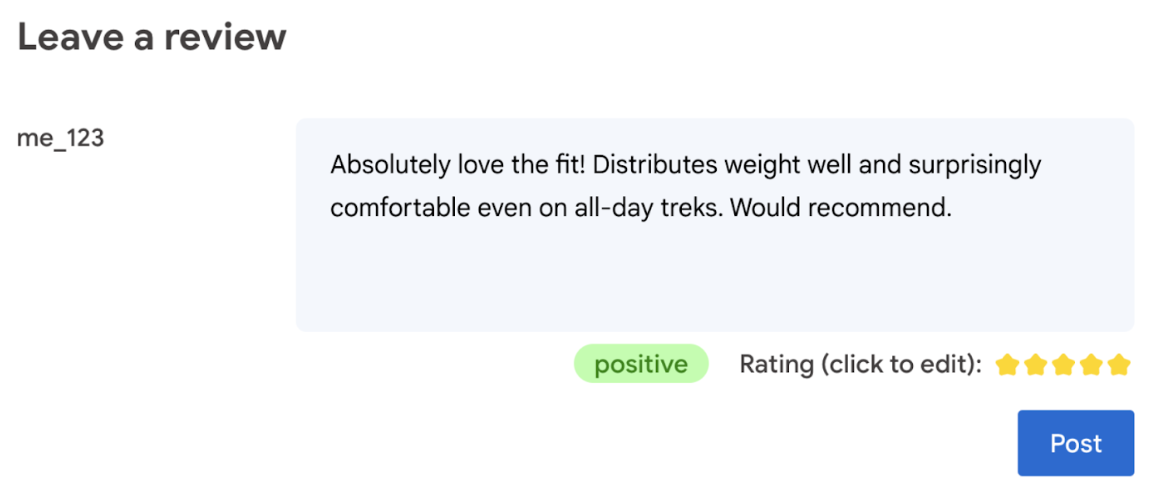
في النهاية، يجب أن يكون للمستخدم الكلمة الأخيرة بشأن تقييم المنتج.
تقدّم تجربة البرمجة العملية التالية حلولاً من جهة العميل، سواء على الجهاز أو في المتصفّح. لا تحتاج إلى معرفة بتطوير الذكاء الاصطناعي أو الخوادم أو مفاتيح واجهة برمجة التطبيقات.
المتطلبات الأساسية
في حين أنّ الذكاء الاصطناعي من جهة الخادم مع حلول (مثل Gemini API أو OpenAI API) يقدّم حلولاً فعّالة للعديد من التطبيقات، نركّز في هذا الدليل على الذكاء الاصطناعي على الويب من جهة العميل. يحدث الاستنتاج المستند إلى الذكاء الاصطناعي من جهة العميل في المتصفّح، وذلك لتحسين تجربة مستخدمي الويب من خلال إزالة الرحلات المتكرّرة إلى الخادم.
في هذا الدرس التطبيقي حول الترميز، نستخدم مجموعة من التقنيات لنعرض لك الأدوات المتاحة لديك في مجال الذكاء الاصطناعي من جهة العميل.
نستخدم المكتبات والنماذج التالية:
- TensforFlow.js لتحليل السمية TensorFlow.js هي مكتبة مفتوحة المصدر لتعلُّم الآلة، وتتيح الاستنتاج والتدريب على الويب.
- transformers.js لتحليل المشاعر Transformers.js هي مكتبة ذكاء اصطناعي على الويب من Hugging Face.
- Gemma 2B للتقييمات بالنجوم Gemma هي مجموعة من النماذج المفتوحة والخفيفة تم إنشاؤها بالاستناد إلى الأبحاث والتكنولوجيا التي استُخدمَت لإنشاء نماذج Gemini. لتشغيل Gemma في المتصفّح، نستخدمها مع واجهة برمجة التطبيقات التجريبية للاستدلال في النماذج اللغوية الكبيرة من MediaPipe.
اعتبارات تجربة المستخدم والسلامة
في ما يلي بعض الاعتبارات لضمان توفير أفضل تجربة للمستخدمين والحفاظ على أمانهم:
- السماح للمستخدم بتعديل التقييم في النهاية، يجب أن يكون للمستخدم الكلمة الأخيرة بشأن تقييم المنتج.
- يجب أن توضّح للمستخدم أنّ التقييمات والمراجعات تتم بشكل آلي.
- السماح للمستخدمين بنشر مراجعة مصنّفة على أنّها مسيئة، ولكن إجراء عملية تحقّق ثانية على الخادم ويمنع ذلك حدوث تجربة محبطة يتم فيها تصنيف مراجعة غير مسيئة على أنّها مسيئة (موجب خاطئ). ويشمل ذلك أيضًا الحالات التي يتمكّن فيها مستخدم ضار من تجاوز عملية التحقّق من جهة العميل.
- إنّ إجراء فحص للتأكّد من السمية من جهة العميل أمر مفيد، ولكن يمكن تجاوزه. احرص على إجراء عملية التحقّق من جهة الخادم أيضًا.
تحليل مستوى السمية باستخدام TensorFlow.js
يمكنك البدء بسرعة في تحليل مدى سمية مراجعة المستخدم باستخدام TensorFlow.js.
- ثبِّت واستورِد مكتبة TensorFlow.js ونموذج السمية.
- ضبط الحدّ الأدنى لمستوى الثقة في التوقّعات القيمة التلقائية هي 0.85، وفي مثالنا، ضبطناها على 0.9.
- تحميل النموذج بشكل غير متزامن
- تصنيف المراجعة بشكل غير متزامن تحدّد التعليمات البرمجية التوقعات التي تتجاوز الحدّ الأدنى البالغ 0.9 لأي فئة.
يمكن لهذا النموذج تصنيف المحتوى المسيء حسب الهجوم على الهوية والإهانة والفحش وغير ذلك.
على سبيل المثال:
import * as toxicity from '@tensorflow-models/toxicity';
// Minimum prediction confidence allowed
const TOXICITY_COMMENT_THRESHOLD = 0.9;
const toxicityModel = await toxicity.load(TOXICITY_COMMENT_THRESHOLD);
const toxicityPredictions = await toxicityModel.classify([review]);
// `predictions` is an array with the raw toxicity probabilities
const isToxic = toxicityPredictions.some(
(prediction) => prediction.results[0].match
);
تحديد المشاعر باستخدام Transformers.js
ثبِّت مكتبة Transformers.js واستوردها.
إعداد مهمة تحليل المشاعر باستخدام خط أنابيب مخصّص عند استخدام مسار للمرة الأولى، يتم تنزيل النموذج وتخزينه مؤقتًا. بعد ذلك، من المفترض أن يصبح تحليل المشاعر أسرع بكثير.
تصنيف المراجعة بشكل غير متزامن استخدِم حدًا مخصّصًا لضبط مستوى الثقة الذي تعتبره قابلاً للاستخدام في تطبيقك.
على سبيل المثال:
import { pipeline } from '@xenova/transformers';
const SENTIMENT_THRESHOLD = 0.9;
// Create a pipeline (don't block rendering on this function)
const transformersjsClassifierSentiment = await pipeline(
'sentiment-analysis'
);
// When the user finishes typing
const sentimentResult = await transformersjsClassifierSentiment(review);
const { label, score } = sentimentResult[0];
if (score > SENTIMENT_THRESHOLD) {
// The sentiment is `label`
} else {
// Classification is not conclusive
}
اقتراح تقييم بالنجوم باستخدام Gemma وMediaPipe
باستخدام LLM Inference API، يمكنك تشغيل نماذج لغوية كبيرة (LLM) بالكامل في المتصفّح.
تُعدّ هذه الإمكانية الجديدة مفيدة بشكل خاص نظرًا إلى متطلبات الذاكرة والحوسبة التي تحتاج إليها النماذج اللغوية الكبيرة، والتي تزيد عن مئة ضعف مقارنةً بالنماذج التي تعمل من جهة العميل. تتيح التحسينات على مستوى حزمة الويب إجراء ذلك، بما في ذلك العمليات الجديدة والتكميم والتخزين المؤقت ومشاركة الأوزان. المصدر: "النماذج اللغوية الكبيرة على الجهاز فقط باستخدام MediaPipe وTensorFlow Lite"
- تثبيت واستيراد واجهة برمجة التطبيقات MediaPipe LLM inference API
- تنزيل نموذج في هذا المثال، نستخدم Gemma 2B التي تم تنزيلها من Kaggle. Gemma 2B هو أصغر نماذج Google المفتوحة.
- وجِّه الرمز إلى ملفات النموذج الصحيحة باستخدام
FilesetResolver. هذا الإجراء مهم لأنّ نماذج الذكاء الاصطناعي التوليدي قد تتضمّن بنية دليل محدّدة لأصولها. - حمِّل النموذج واضبطه باستخدام واجهة LLM في MediaPipe. جهِّز النموذج للاستخدام: حدِّد موقع النموذج وطول الردود المفضّل ومستوى الإبداع المفضّل باستخدام درجة العشوائية.
- قدِّم طلبًا للنموذج (الاطّلاع على مثال).
- انتظِر ردّ النموذج.
- تحليل التقييم: استخرِج التقييم بالنجوم من ردّ النموذج.
import { FilesetResolver, LlmInference } from '@mediapipe/tasks-genai';
const mediaPipeGenAi = await FilesetResolver.forGenAiTasks();
const llmInference = await LlmInference.createFromOptions(mediaPipeGenAi, {
baseOptions: {
modelAssetPath: '/gemma-2b-it-gpu-int4.bin',
},
maxTokens: 1000,
topK: 40,
temperature: 0.5,
randomSeed: 101,
});
const prompt = …
const output = await llmInference.generateResponse(prompt);
const int = /\d/;
const ratingAsString = output.match(int)[0];
rating = parseInt(ratingAsString);
مثال على طلب
const prompt = `Analyze a product review, and then based on your analysis give me the
corresponding rating (integer). The rating should be an integer between 1 and 5.
1 is the worst rating, and 5 is the best rating. A strongly dissatisfied review
that only mentions issues should have a rating of 1 (worst). A strongly
satisfied review that only mentions positives and upsides should have a rating
of 5 (best). Be opinionated. Use the full range of possible ratings (1 to 5). \n\n
\n\n
Here are some examples of reviews and their corresponding analyses and ratings:
\n\n
Review: 'Stylish and functional. Not sure how it'll handle rugged outdoor use,
but it's perfect for urban exploring.'
Analysis: The reviewer appreciates the product's style and basic
functionality. They express some uncertainty about its ruggedness but overall
find it suitable for their intended use, resulting in a positive, but not
top-tier rating.
Rating (integer): 4
\n\n
Review: 'It's a solid backpack at a decent price. Does the job, but nothing
particularly amazing about it.'
Analysis: This reflects an average opinion. The backpack is functional and
fulfills its essential purpose. However, the reviewer finds it unremarkable
and lacking any standout features deserving of higher praise.
Rating (integer): 3
\n\n
Review: 'The waist belt broke on my first trip! Customer service was
unresponsive too. Would not recommend.'
Analysis: A serious product defect and poor customer service experience
naturally warrants the lowest possible rating. The reviewer is extremely
unsatisfied with both the product and the company.
Rating (integer): 1
\n\n
Review: 'Love how many pockets and compartments it has. Keeps everything
organized on long trips. Durable too!'
Analysis: The enthusiastic review highlights specific features the user loves
(organization and durability), indicating great satisfaction with the product.
This justifies the highest rating.
Rating (integer): 5
\n\n
Review: 'The straps are a bit flimsy, and they started digging into my
shoulders under heavy loads.'
Analysis: While not a totally negative review, a significant comfort issue
leads the reviewer to rate the product poorly. The straps are a key component
of a backpack, and their failure to perform well under load is a major flaw.
Rating (integer): 1
\n\n
Now, here is the review you need to assess:
\n
Review: "${review}" \n`;
الخلاصات
لا تحتاج إلى خبرة في الذكاء الاصطناعي أو تعلُّم الآلة. يتطلّب تصميم الطلب تكرارات، ولكن بقية الرمز البرمجي هي عملية تطوير ويب عادية.
تتسم النماذج من جهة العميل بالدقة إلى حدّ كبير. إذا شغّلت المقتطفات من هذا المستند، ستلاحظ أنّ تحليل السمية وتحليل المشاعر يعطيان نتائج دقيقة. تطابقت تقييمات Gemma في معظمها مع تقييمات نموذج Gemini لعدد قليل من المراجعات المرجعية التي تم اختبارها. للتأكّد من دقة هذه المعلومات، يجب إجراء المزيد من الاختبارات.
مع ذلك، يتطلّب تصميم الطلب الخاص بـ Gemma 2B بعض الجهد. بما أنّ Gemma 2B هو نموذج لغوي كبير صغير، يحتاج إلى طلب مفصّل لتقديم نتائج مرضية، أي أكثر تفصيلاً من المطلوب عند استخدام Gemini API.
يمكن أن تكون الاستنتاجات سريعة جدًا. إذا شغّلت المقتطفات من هذا المستند، ستلاحظ أنّ الاستنتاج يمكن أن يكون سريعًا، وربما أسرع من عمليات تبادل البيانات مع الخادم، على عدد من الأجهزة. ومع ذلك، يمكن أن تختلف سرعة الاستدلال بشكل كبير. يجب إجراء قياس أداء شامل على الأجهزة المستهدَفة. نتوقّع أن تصبح عملية الاستدلال في المتصفّح أسرع مع WebGPU وWebAssembly وتحديثات المكتبة. على سبيل المثال، تضيف Transformers.js إمكانية استخدام Web GPU في الإصدار 3، ما يمكن أن يؤدي إلى تسريع الاستدلال على الجهاز فقط عدة مرات.
يمكن أن تكون أحجام التنزيل كبيرة جدًا. تكون عملية الاستدلال في المتصفّح سريعة، ولكن قد يكون تحميل نماذج الذكاء الاصطناعي أمرًا صعبًا. لتنفيذ الذكاء الاصطناعي في المتصفح، تحتاج عادةً إلى مكتبة ونموذج، ما يزيد من حجم تنزيل تطبيق الويب.
في حين أنّ نموذج السمية في Tensorflow (وهو نموذج كلاسيكي لمعالجة اللغة الطبيعية) لا يتجاوز حجمه بضعة كيلوبايتات، يصل حجم نماذج الذكاء الاصطناعي التوليدي، مثل نموذج تحليل المشاعر التلقائي في Transformers.js، إلى 60 ميغابايت. يمكن أن يصل حجم النماذج اللغوية الكبيرة، مثل Gemma، إلى 1.3 غيغابايت. وهذا يتجاوز متوسط حجم صفحة الويب البالغ 2.2 ميغابايت، وهو أكبر بكثير من الحجم الموصى به لتحقيق أفضل أداء. يمكن استخدام الذكاء الاصطناعي التوليدي من جهة العميل في سيناريوهات محدّدة.
يتطوّر مجال الذكاء الاصطناعي التوليدي على الويب بسرعة. من المتوقّع أن تظهر نماذج أصغر حجمًا ومحسّنة للويب في المستقبل.
الخطوات التالية
يختبر Chrome طريقة أخرى لتشغيل الذكاء الاصطناعي التوليدي في المتصفّح. يمكنك الاشتراك في "برنامج الاستخدام المبكّر" لتجربتها.