

Fecha de publicación: 2 de diciembre de 2022; última actualización: 23 de octubre de 2025
' d='M96 183a64 64 0 0 1-23-23L17 64a128 128 0 0 0 111 192l55-96a64 64 0 0 1-87 23Z'/%3E%3Cpath fill='url(%23b)' d='M192 128a64 64 0 0 1-9 32l-55 96A128 128 0 0 0 239 64H128a64 64 0 0 1 64 64Z'/%3E%3Ccircle cx='128' cy='128' r='52' fill='%231a73e8'/%3E%3Cpath fill='url(%23c)' d='M96 73a64 64 0 0 1 32-9h111a128 128 0 0 0-222 0l56 96a64 64 0 0 1 23-87Z'/%3E%3C/svg%3E)
' xlink:href='%23A'%3E%3Cstop offset='.76' stop-opacity='0'/%3E%3Cstop offset='.95' stop-opacity='.5'/%3E%3Cstop offset='1'/%3E%3C/radialGradient%3E%3CradialGradient id='F' cx='2523' cy='4680' r='20243' gradientTransform='matrix(-.03715 .99931 -2.12836 -.07913 13579 3530)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2335c1f1'/%3E%3Cstop offset='.11' stop-color='%2334c1ed'/%3E%3Cstop offset='.23' stop-color='%232fc2df'/%3E%3Cstop offset='.31' stop-color='%232bc3d2'/%3E%3Cstop offset='.67' stop-color='%2336c752'/%3E%3C/radialGradient%3E%3CradialGradient id='G' cx='24247' cy='7758' r='9734' gradientTransform='matrix(.28109 .95968 -.78353 .22949 24510 -16292)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2366eb6e'/%3E%3Cstop offset='1' stop-color='%2366eb6e' stop-opacity='0'/%3E%3C/radialGradient%3E%3Cpath id='H' d='M24105 20053a9345 9345 0 01-1053 472 10202 10202 0 01-3590 646c-4732 0-8855-3255-8855-7432 0-1175 680-2193 1643-2729-4280 180-5380 4640-5380 7253 0 7387 6810 8137 8276 8137 791 0 1984-230 2704-456l130-44a12834 12834 0 006660-5282c220-350-168-757-535-565z'/%3E%3Cpath id='I' d='M11571 25141a7913 7913 0 01-2273-2137 8145 8145 0 01-1514-4740 8093 8093 0 013093-6395 8082 8082 0 011373-859c312-148 846-414 1554-404a3236 3236 0 012569 1297 3184 3184 0 01636 1866c0-21 2446-7960-8005-7960-4390 0-8004 4166-8004 7820 0 2319 538 4170 1212 5604a12833 12833 0 007684 6757 12795 12795 0 003908 610c1414 0 2774-233 4045-656a7575 7575 0 01-6278-803z'/%3E%3Cpath id='J' d='M16231 15886c-80 105-330 250-330 566 0 260 170 512 472 723 1438 1003 4149 868 4156 868a5954 5954 0 003027-839 6147 6147 0 001133-850 6180 6180 0 001910-4437c26-2242-796-3732-1133-4392-2120-4141-6694-6525-11668-6525-7011 0-12703 5635-12798 12620 47-3654 3679-6605 7996-6605 350 0 2346 34 4200 1007 1634 858 2490 1894 3086 2921 618 1067 728 2415 728 2952s-271 1333-780 1990z'/%3E%3Cuse fill='url(%23B)' xlink:href='%23H'/%3E%3Cuse fill='url(%23D)' opacity='.35' xlink:href='%23H'/%3E%3Cuse fill='url(%23C)' xlink:href='%23I'/%3E%3Cuse fill='url(%23E)' opacity='.4' xlink:href='%23I'/%3E%3Cuse fill='url(%23F)' xlink:href='%23J'/%3E%3Cuse fill='url(%23G)' xlink:href='%23J'/%3E%3C/svg%3E)
' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%239059ff' stop-opacity='0'/%3E%3Cstop offset='.3' stop-color='%238c4ff3' stop-opacity='.1'/%3E%3Cstop offset='.8' stop-color='%237716a8' stop-opacity='.5'/%3E%3Cstop offset='1' stop-color='%236e008b' stop-opacity='.6'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-g' cx='239.1' cy='34.6' r='171.6' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23ffe226'/%3E%3Cstop offset='.1' stop-color='%23ffdb27'/%3E%3Cstop offset='.3' stop-color='%23ffc82a'/%3E%3Cstop offset='.5' stop-color='%23ffa930'/%3E%3Cstop offset='.7' stop-color='%23ff7e37'/%3E%3Cstop offset='.8' stop-color='%23ff7139'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-h' cx='374' cy='-74.3' r='732.2' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-i' cx='304.6' cy='7.1' r='536.4' gradientTransform='rotate(84 303 4)' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.3' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.6' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-j' cx='235' cy='98.1' r='457.1' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-k' cx='355.7' cy='124.9' r='500.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.2' stop-color='%23ffe141'/%3E%3Cstop offset='.5' stop-color='%23ffaf1e'/%3E%3Cstop offset='.6' stop-color='%23ff980e'/%3E%3C/radialGradient%3E%3ClinearGradient id='ff-a' x1='446.9' y1='76.8' x2='47.9' y2='461.8' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.4' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.5' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/linearGradient%3E%3ClinearGradient id='ff-l' x1='442.1' y1='74.8' x2='102.6' y2='414.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%23fff44f' stop-opacity='.8'/%3E%3Cstop offset='.3' stop-color='%23fff44f' stop-opacity='.6'/%3E%3Cstop offset='.5' stop-color='%23fff44f' stop-opacity='.2'/%3E%3Cstop offset='.6' stop-color='%23fff44f' stop-opacity='0'/%3E%3C/linearGradient%3E%3C/defs%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134a120 120 0 0 0-66 25 71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a229 229 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zM202 355l3 1-3-1zm55-145zm198-31z' fill='url(%23ff-a)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-b)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-c)'/%3E%3Cpath d='m362 195 1 1a130 130 0 0 0-22-29C266 92 322 5 331 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62z' fill='url(%23ff-d)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-e)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-f)'/%3E%3Cpath d='m171 151 5 3a111 111 0 0 1-1-58c-25 11-44 29-58 44 1 0 36 0 54 11z' fill='url(%23ff-g)'/%3E%3Cpath d='M18 261a242 242 0 0 0 231 197 207 207 0 0 0 206-279c8 56-20 110-64 146-86 71-169 43-186 31l-3-1c-50-24-71-70-67-110-42 0-57-35-57-35s38-28 89-4c46 22 90 4 90 4 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5l-5-3c-18-11-52-11-54-11-9-12-9-51-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73c0 1-9 38-5 57z' fill='url(%23ff-h)'/%3E%3Cpath d='M341 167a130 130 0 0 1 22 29 46 46 0 0 1 4 3c55 50 26 121 24 126 44-36 72-90 64-146-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-9 5-65 92 10 167z' fill='url(%23ff-i)'/%3E%3Cpath d='M367 199a46 46 0 0 0-4-3l-1-1c-13-9-36-18-58-15 86 44 63 193-57 187a107 107 0 0 1-31-6 131 131 0 0 1-11-5c17 12 99 39 186-31 2-5 31-76-24-126z' fill='url(%23ff-j)'/%3E%3Cpath d='M148 277s12-41 80-41c7 0 28-20 29-26s-44 18-90-4c-51-24-89 4-89 4s15 35 57 35c-4 40 16 85 67 110l3 1c-29-15-54-44-57-79z' fill='url(%23ff-k)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62-13-9-36-18-58-14 86 43 63 192-57 186a107 107 0 0 1-31-6 131 131 0 0 1-11-5l-3-1 3 1c-29-15-54-44-57-79 0 0 12-41 80-41 7 0 28-20 29-26 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a279 279 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zm-24 13z' fill='url(%23ff-l)'/%3E%3C/svg%3E)
' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-color='%2324a5f3' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%231e8ceb' /%3E%3C/radialGradient%3E%3CradialGradient id='s-j' cx='109.3' cy='13.8' r='93.1' gradientTransform='matrix(-.02 1.1 -1.04 -.02 137 -115)' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235488d6' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235d96eb' /%3E%3C/radialGradient%3E%3C/defs%3E%3Crect width='220' height='220' x='22' y='-107' fill='url(%23s-a)' ry='49' transform='matrix(.57 0 0 .57 187 256)' /%3E%3Cg transform='translate(194 190)'%3E%3Ccircle cx='67.8' cy='67.7' fill='url(%23s-c)' paint-order='stroke fill markers' r='54' /%3E%3Ccircle cx='-69.9' cy='69.3' fill='url(%23s-i)' transform='translate(138 -2)' r='54' /%3E%3C/g%3E%3Cellipse cx='120' cy='14.2' fill='url(%23s-j)' rx='93.1' ry='93.7' transform='matrix(.58 0 0 .58 192 250)' /%3E%3Cg transform='matrix(.58 0 0 .57 197 182)'%3E%3Cpath fill='%23cac7c8' d='M46 192h1l72-48-7-9-66 57Z' /%3E%3Cpath fill='%23fbfffc' d='M46 191v1l66-57-7-9-59 65Z' /%3E%3Cpath fill='url(%23s-d)' d='m119 144-7-9 66-57-59 66Z' /%3E%3Cpath fill='%23fb645c' d='m105 126 7 9 66-57-1-1-72 49Z' /%3E%3C/g%3E%3Cpath stroke='%23fff' stroke-linecap='round' stroke-miterlimit='1' stroke-width='1.3' d='m287 278 3-2m-12-17 8-2m-8-3h4m-4-13 8 2m-8 3h4m-1-13 7 3m-4-11 7 4m-2-11 6 6m0-12 6 7m1-11 4 6m4-10 3 7m5-9 2 7m15-7-1 7m10-5-3 7m11-4-4 7m11-2-5 6m16 7-7 4m10 4-7 3m10 6-8 1m8 16-8-2m5 10-7-3m4 11-7-4m2 11-6-5m0 11-5-6m-2 11-4-7m-4 11-3-8m-6 10-1-8m-16 8 2-8m-10 5 3-7m-11 4 4-7m-11 2 5-6m-8 3 3-3m4 8 2-3m5 8 2-4m6 7 1-4m8 5v-4m8 4v-4m9 3-1-4m9 1-2-4m9 0-2-4m9-2-3-3m8-4-3-2m8-5-4-2m7-6-4-1m5-8h-4m4-8h-4m3-9-4 1m1-9-4 2m-1-9-3 2m-2-9-3 3m-4-8-2 3m-5-8-2 4m-6-6-1 3m-8-5v4m-8-4v4m-9-2 1 3m-9 0 2 3m-9 1 2 3m-9 2 3 3m-8 4 3 2m-8 5 4 2m-7 6 4 1m-4 25 4-1m-2 5 7-3m-6 7 4-2m-2 6 7-4m-13-21h8m41-41v-8m0 99v-8m49-42h-8' transform='translate(-65 8)' /%3E%3C/svg%3E)
El equipo de Chrome restableció la renderización previa completa de las páginas futuras a las que es probable que navegue un usuario.
Breve historia del procesamiento previo
En el pasado, Chrome admitía la sugerencia de recurso <link rel="prerender" href="/next-page">, pero no era ampliamente compatible más allá de Chrome y no era una API muy expresiva.
Esta renderización previa heredada que usa la sugerencia de vínculo rel=prerender dejó de estar disponible en favor de la carga previa sin estado, que, en cambio, recuperaba los recursos necesarios para la página futura, pero no renderizaba previamente la página por completo ni ejecutaba JavaScript. La carga previa sin estado ayuda a mejorar el rendimiento de la página, ya que optimiza la carga de recursos, pero no ofrece una carga de página instantánea como lo haría una renderización previa completa.
El equipo de Chrome volvió a introducir la función de pregeneración completa en Chrome. Para evitar complicaciones con el uso existente y permitir la expansión futura de la renderización previa, este nuevo mecanismo no usará la sintaxis <link rel="prerender"...>, que permanece en su lugar para la recuperación previa sin estado, con la intención de retirarla en algún momento en el futuro.
¿Cómo se renderiza previamente una página?
Una página se puede renderizar previamente de cuatro maneras, todas con el objetivo de acelerar la navegación:
- Cuando escribes una URL en la barra de direcciones de Chrome (también conocida como "el cuadro multifunción"), Chrome puede realizar una renderización previa automática de la página si tiene un alto nivel de confianza en que la visitarás, según tu historial de navegación anterior.
- Cuando usas la barra de favoritos, Chrome puede realizar una renderización previa automática de la página cuando mantienes el puntero sobre uno de los botones de favoritos.
- Cuando escribes un término de búsqueda en la barra de direcciones de Chrome, es posible que Chrome renderice previamente de forma automática la página de resultados de la búsqueda si el motor de búsqueda se lo indica.
- Los sitios pueden usar la API de Speculation Rules para indicarle a Chrome de forma programática qué páginas debe renderizar previamente. Esto reemplaza lo que hacía
<link rel="prerender"...>y permite que los sitios rendericen de forma previa una página de manera proactiva según las reglas de especulación de la página. Pueden existir de forma estática en las páginas o insertarse de forma dinámica con JavaScript según lo considere adecuado el propietario de la página.
En cada uno de estos casos, la renderización previa se comporta como si la página se hubiera abierto en una pestaña invisible en segundo plano y, luego, se "activa" reemplazando la pestaña en primer plano por esa página renderizada previamente. Si una página se activa antes de que se haya completado la renderización previa, su estado actual es "en primer plano" y continúa cargándose, lo que significa que aún puedes obtener un buen comienzo.
Como la página renderizada previamente se abre en un estado oculto, varias APIs que causan comportamientos intrusivos (por ejemplo, mensajes) no se activan en este estado y, en cambio, se retrasan hasta que se activa la página. En la pequeña cantidad de casos en los que esto aún no es posible, se cancela la renderización previa. El equipo de Chrome está trabajando para exponer los motivos de cancelación de la renderización previa como una API y también para mejorar las capacidades de Herramientas para desarrolladores para facilitar la identificación de estos casos extremos.
Impacto del procesamiento previo
La renderización previa permite una carga de página casi instantánea, como se muestra en el siguiente video:
El sitio de ejemplo ya es rápido, pero incluso así puedes ver cómo la renderización previa mejora la experiencia del usuario. Por lo tanto, también puede tener un impacto directo en las Métricas web esenciales de un sitio, con un LCP cercano a cero, un CLS reducido (ya que cualquier CLS de carga ocurre antes de la vista inicial) y un INP mejorado (ya que la carga debe completarse antes de que el usuario interactúe).
Incluso cuando una página se activa antes de que se cargue por completo, tener una ventaja en la carga de la página debería mejorar la experiencia de carga. Cuando se activa un vínculo mientras aún se realiza la renderización previa, la página de renderización previa se moverá al marco principal y continuará cargándose.
Sin embargo, la renderización previa usa memoria y ancho de banda de red adicionales. Ten cuidado de no realizar una renderización previa excesiva, ya que esto genera un costo en los recursos del usuario. Solo se realiza la renderización previa cuando hay una alta probabilidad de que se navegue a la página.
Consulta la sección Cómo medir el rendimiento para obtener más información sobre cómo medir el impacto real en el rendimiento en tus estadísticas.
Cómo ver las predicciones de la barra de direcciones de Chrome
En el primer caso de uso, puedes ver las predicciones de Chrome para las URLs en la página chrome://predictors:
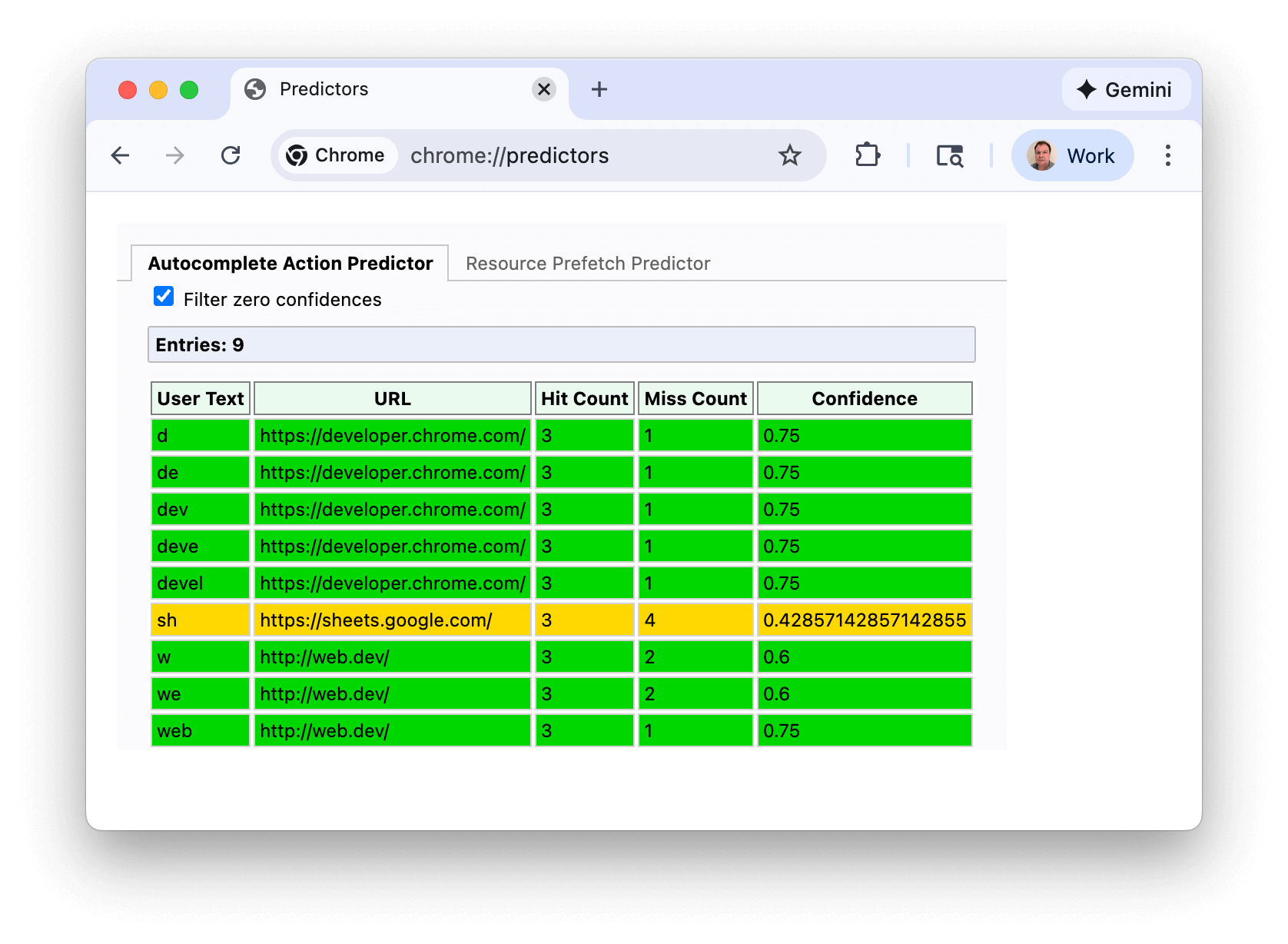
Las líneas verdes indican que hay suficiente confianza para activar la renderización previa. En este ejemplo, escribir "s" brinda un nivel de confianza razonable (ámbar), pero, una vez que escribes "sh", Chrome tiene suficiente confianza en que casi siempre navegas a https://sheets.google.com.
Esta captura de pantalla se tomó en una instalación de Chrome relativamente nueva y se filtraron las predicciones con confianza cero, pero si ves tus propios predictores, es probable que veas muchas más entradas y, tal vez, más caracteres necesarios para alcanzar un nivel de confianza lo suficientemente alto.
Estos predictores también son los que impulsan las opciones sugeridas de la barra de direcciones que quizás hayas notado:
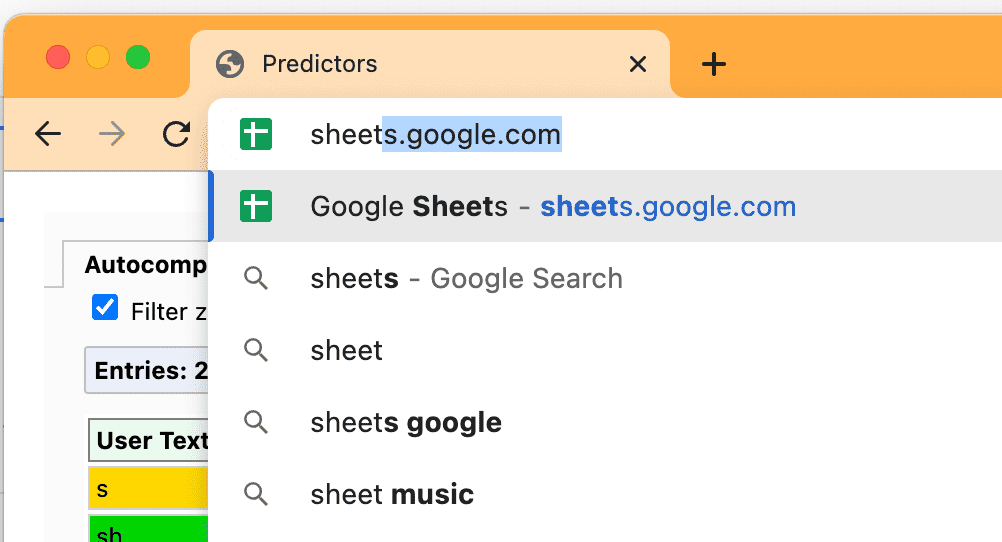
Chrome actualizará continuamente sus predictores en función de lo que escribas y selecciones.
- Para un nivel de confianza superior al 30% (que se muestra en ámbar), Chrome realiza una conexión previa de forma proactiva al dominio, pero no renderiza previamente la página.
- Para un nivel de confianza superior al 50% (que se muestra en verde), Chrome realizará una renderización previa de la URL.
La API de Speculation Rules
En el caso de la opción de renderización previa de la API de Speculation Rules, los desarrolladores web pueden insertar instrucciones JSON en sus páginas para informar al navegador sobre qué URLs renderizar previamente.
Lista de URL
Las reglas de especulación pueden basarse en listas de URLs:
<script type="speculationrules">
{
"prerender": [
{
"urls": ["next.html", "next2.html"]
}
]
}
</script>
Reglas de documentos
Las reglas de especulación también pueden ser "reglas de documento" con la sintaxis where. Esta especificación predice los vínculos que se encuentran en el documento según los selectores href (basados en la API de URL Pattern) o los selectores CSS:
<script type="speculationrules">
{
"prerender": [{
"where": {
"and": [
{ "href_matches": "/*" },
{ "not": {"href_matches": "/wp-admin"}},
{ "not": {"href_matches": "/*\\?*(^|&)add-to-cart=*"}},
{ "not": {"selector_matches": ".do-not-prerender"}},
{ "not": {"selector_matches": "[rel~=nofollow]"}}
]
}
}]
}
</script>
Entusiasmo
Un parámetro de configuración de eagerness se usa para indicar cuándo se deben activar las especulaciones, lo que es particularmente útil para las reglas de documentos:
conservative: Este parámetro realiza una especulación sobre el puntero o el evento de toque.moderate: En computadoras, este parámetro realiza especulaciones si mantienes el puntero sobre un vínculo durante 200 milisegundos (o en el eventopointerdown, si ocurre antes, y en dispositivos móviles, donde no se puede colocar el cursor sobre un elemento).hoverEn dispositivos móviles, cambiamos la base de esto a heurísticas complejas del viewport a partir de agosto de 2025.eager: Originalmente, se comportaba de forma idéntica aimmediate, pero cambiará para ser más un estado intermedio entreimmediateymoderate. En Chrome 141, este evento se activa cuando el mouse se detiene durante 10 milisegundos en la computadora. La versión para dispositivos móviles sigue siendo la misma queimmediate, pero se está migrando a heurísticas de viewport simples.immediate: Se utiliza para hacer una especulación lo más pronto posible, es decir, ni bien se observan las reglas de especulación.
El valor predeterminado de eagerness para las reglas de list es immediate. Las opciones eager, moderate y conservative se pueden usar para limitar las reglas de list a una lista específica de URLs con las que interactúa un usuario. Sin embargo, en muchos casos, las reglas document con una condición where adecuada pueden ser más apropiadas.
El valor predeterminado de eagerness para las reglas de document es conservative. Dado que un documento puede constar de muchas URLs, el uso de immediate para las reglas de document debe hacerse con precaución (consulta también la siguiente sección sobre los límites de Chrome).
El parámetro de configuración de eagerness que debes usar depende de tu sitio. En el caso de un sitio estático y ligero, especular con más rapidez puede tener un costo bajo y ser beneficioso para los usuarios. Los sitios con arquitecturas más complejas y cargas útiles de página más pesadas pueden preferir reducir el desperdicio especulando con menos frecuencia hasta que obtengas más indicadores positivos de intención de los usuarios para limitar el desperdicio.
La opción moderate es un punto intermedio, y muchos sitios podrían beneficiarse de la siguiente regla de especulación que generaría una vista previa de un vínculo cuando se mantenga el puntero sobre él durante 200 milisegundos o en el evento pointerdown como una implementación básica, pero potente, de las reglas de especulación:
<script type="speculationrules">
{
"prerender": [{
"where": {
"href_matches": "/*"
},
"eagerness": "moderate"
}]
}
</script>
Recuperación previa
Las reglas de especulación también se pueden usar solo para cargar previamente las páginas, sin una renderización previa completa. A menudo, este puede ser un buen primer paso en el camino hacia la renderización previa:
<script type="speculationrules">
{
"prefetch": [
{
"urls": ["next.html", "next2.html"]
}
]
}
</script>
Prender hasta la secuencia de comandos
El equipo de Chrome también está trabajando para agregar prerender_until_script a la API de Speculation Rules (consulta el error de implementación). Este sería un paso entre la carga previa y la renderización previa, y se usaría de manera similar:
<script type="speculationrules">
{
"prerender_until_script": [
{
"urls": ["next.html", "next2.html"]
}
]
}
</script>
De manera similar a NoState prefetch, esto realizaría una recuperación previa tanto del documento HTML como de los recursos secundarios disponibles en ese HTML. Sin embargo, iría más allá y también comenzaría a generar una vista previa de la página, deteniéndose cuando se encuentre el primer script.
Esto significaría que, en el caso de las páginas sin JavaScript o con JavaScript solo en el pie de página, la página podría renderizarse previamente casi por completo. Las páginas con secuencias de comandos en <head> no podrían realizar la renderización previa, pero seguirían beneficiándose de la recuperación de subrecursos.
Esto evitaría los riesgos de efectos secundarios no deseados de la ejecución de JavaScript, pero permitiría una ganancia de rendimiento mucho mayor que solo prefetch.
Límites de Chrome
Chrome tiene límites para evitar el uso excesivo de la API de Speculation Rules:
| entusiasmo | Recuperación previa | Renderización previa |
|---|---|---|
immediate / eager (para dispositivos móviles) |
50 | 10 |
eager (computadoras de escritorio) / moderate / conservative |
2 (FIFO) | 2 (FIFO) |
La configuración de moderate y conservative, que depende de la interacción del usuario, funciona según el método primero en entrar, primero en salir (FIFO): Después de alcanzar el límite, una nueva especulación hará que se cancele la más antigua y se reemplace por la más reciente para conservar memoria. Una especulación cancelada se puede volver a activar, por ejemplo, si vuelves a colocar el cursor sobre ese vínculo, lo que hará que se vuelva a especular sobre esa URL y se descarte la especulación más antigua. En este caso, la especulación anterior habrá almacenado en caché todos los recursos almacenables en la caché HTTP para esa URL, por lo que especular en un momento posterior debería tener un costo reducido. Por eso, el límite se establece en el umbral moderado de 2. Las reglas de listas estáticas no se activan por una acción del usuario, por lo que tienen un límite más alto, ya que el navegador no puede saber cuáles se necesitan ni cuándo.
Los límites de immediate y eager también son dinámicos, por lo que quitar un elemento de secuencia de comandos de URL de list creará capacidad al cancelar esas especulaciones quitadas.
Chrome también impedirá que se usen especulaciones en ciertas condiciones, incluidas las siguientes:
- Save-Data.
- Ahorro de energía cuando está habilitado y la batería está baja
- Restricciones de memoria
- Cuando el parámetro de configuración "Precargar páginas" está desactivado (lo que también desactivan explícitamente las extensiones de Chrome, como uBlock Origin)
- Páginas abiertas en pestañas en segundo plano
Chrome tampoco renderiza iframes de origen cruzado en páginas con renderización previa hasta que se activan.
Todas estas condiciones tienen como objetivo reducir el impacto de la especulación excesiva cuando sería perjudicial para los usuarios.
Cómo incluir reglas de especulación en una página
Las reglas de especulación se pueden incluir de forma estática en el código HTML de la página o se pueden insertar de forma dinámica en la página con JavaScript:
- Reglas de especulación incluidas de forma estática: Por ejemplo, un sitio de noticias o un blog pueden realizar una renderización previa del artículo más reciente si, a menudo, esa es la siguiente navegación para una gran proporción de usuarios. Como alternativa, se pueden usar reglas de documentos con
moderateoconservativepara especular a medida que los usuarios interactúan con los vínculos. - Reglas de especulación insertadas de forma dinámica: Pueden basarse en la lógica de la aplicación, personalizarse para el usuario o basarse en otras heurísticas.
Se recomienda a quienes prefieran la inserción dinámica basada en acciones como colocar el cursor sobre un vínculo o hacer clic en él (como muchas bibliotecas han hecho en el pasado con <link rel=prefetch>) que consulten las reglas del documento, ya que estas permiten que el navegador controle muchos de sus casos de uso.
Las reglas de especulación se pueden agregar en el <head> o el <body> del marco principal. Las reglas de especulación en los submarcos no se aplican, y las reglas de especulación en las páginas renderizadas previamente solo se aplican una vez que se activa la página.
El encabezado HTTP Speculation-Rules
Las reglas de especulación también se pueden entregar con un encabezado HTTP Speculation-Rules, en lugar de incluirlas directamente en el código HTML del documento. Esto permite que las CDN realicen implementaciones más fácilmente sin necesidad de alterar el contenido de los documentos.
El encabezado HTTP Speculation-Rules se devuelve con el documento y apunta a la ubicación de un archivo JSON que contiene las reglas de especulación:
Speculation-Rules: "/speculationrules.json"
Este recurso debe usar el tipo de MIME correcto y, si es un recurso de origen cruzado, debe pasar una verificación de CORS.
Content-Type: application/speculationrules+json
Access-Control-Allow-Origin: *
Si deseas usar URLs relativas, es posible que quieras incluir la clave "relative_to": "document" en tus reglas de especulación. De lo contrario, las URLs relativas serán relativas a la URL del archivo JSON de reglas de especulación. Esto puede ser especialmente útil si necesitas seleccionar algunos vínculos del mismo origen, o todos.
Campo de etiqueta de reglas de especulación
También es posible agregar "etiquetas" en la sintaxis JSON de las reglas de especulación a nivel general para todas las reglas de especulación en un conjunto de reglas:
{
"tag": "my-rules",
"prefetch": [
"urls": ["next.html"]
],
"prerender": [
"urls": ["next2.html"]
],
}
O bien a nivel de la regla individual:
{
"prefetch": [
"urls": ["next.html"],
"tag": "my-prefetch-rules"
],
"prerender": [
"urls": ["next2.html"],
"tag": "my-prerender-rules"
],
}
Luego, esta etiqueta se refleja en el encabezado HTTP Sec-Speculation-Tags, que se puede usar para filtrar las reglas de especulación en el servidor. El encabezado HTTP Sec-Speculation-Tags puede incluir varias etiquetas si la especulación está cubierta por varias reglas, como se muestra en el siguiente ejemplo:
Sec-Speculation-Tags: null
Sec-Speculation-Tags: null, "cdn-prefetch"
Sec-Speculation-Tags: "my-prefetch-rules"
Sec-Speculation-Tags: "my-prefetch-rules", "my-rules", "cdn-prefetch"
Algunas CDN insertan automáticamente reglas de especulación, pero bloquean las especulaciones para las páginas que no se almacenan en caché en el borde para evitar que esta función aumente el uso del servidor de origen. Las etiquetas les permiten identificar las especulaciones iniciadas por su conjunto de reglas predeterminado, pero aún permiten que las reglas agregadas por el sitio pasen al origen.
Las etiquetas de los conjuntos de reglas también se muestran en las Herramientas para desarrolladores de Chrome.
Campo target_hint de reglas de especulación
Las reglas de especulación también pueden incluir un campo target_hint, que contiene un nombre o palabra clave de contexto de navegación válidos que indican dónde espera la página que se active el contenido renderizado previamente:
<script type=speculationrules>
{
"prerender": [{
"target_hint": "_blank",
"urls": ["next.html"]
}]
}
</script>
Esta sugerencia permite que se controlen las especulaciones de la renderización previa para los vínculos target="_blank":
<a target="_blank" href="next.html">Open this link in a new tab</a>
Por el momento, solo se admiten "target_hint": "_blank" y "target_hint": "_self" (el valor predeterminado si no se especifica) en Chrome y solo para la renderización previa. La recuperación previa no se admite.
target_hint solo se necesita para las reglas de especulación de urls, ya que para las reglas de documentos, el target se conoce a partir del vínculo.
Reglas de especulación y SPA
Las reglas de especulación solo se admiten para las navegaciones de página completa que administra el navegador, y no para las aplicaciones de una sola página (SPA) ni las páginas de app shell. Estas arquitecturas no usan recuperaciones de documentos, sino que realizan recuperaciones parciales o de API de datos o páginas, que luego se procesan y se presentan en la página actual. La app puede realizar una recuperación previa de los datos necesarios para estas llamadas "navegaciones suaves" fuera de las reglas de especulación, pero no puede realizar una renderización previa.
Las reglas de especulación se pueden usar para renderizar previamente la aplicación desde una página anterior. Esto puede ayudar a compensar algunos de los costos de carga inicial adicionales que tienen algunas SPA. Sin embargo, los cambios de ruta dentro de la app no se pueden renderizar previamente.
Cómo depurar reglas de especulación
Consulta la publicación dedicada a la depuración de reglas de especulación para conocer las nuevas funciones de Chrome DevTools que te ayudarán a ver y depurar esta nueva API.
Varias reglas de especulación
También se pueden agregar varias reglas de especulación a la misma página, y se anexan a las reglas existentes. Por lo tanto, las siguientes formas diferentes generan la renderización previa de one.html y two.html:
Lista de URLs:
<script type="speculationrules">
{
"prerender": [
{
"urls": ["one.html", "two.html"]
}
]
}
</script>
Varias secuencias de comandos de speculationrules:
<script type="speculationrules">
{
"prerender": [
{
"urls": ["one.html"]
}
]
}
</script>
<script type="speculationrules">
{
"prerender": [
{
"urls": ["two.html"]
}
]
}
</script>
Varias listas dentro de un conjunto de speculationrules
<script type="speculationrules">
{
"prerender": [
{
"urls": ["one.html"]
},
{
"urls": ["two.html"]
}
]
}
</script>
Compatibilidad con No-Vary-Search
Cuando se realiza la recuperación previa o la renderización previa de una página, ciertos parámetros de URL (conocidos técnicamente como parámetros de búsqueda) pueden no ser importantes para la página que realmente entrega el servidor y solo se usan en JavaScript del cliente.
Por ejemplo, Google Analytics utiliza los parámetros UTM para medir las campañas, pero, por lo general, no generan la publicación de páginas diferentes desde el servidor. Esto significa que page1.html?utm_content=123 y page1.html?utm_content=456 entregarán la misma página desde el servidor, por lo que la misma página se puede reutilizar desde la caché.
Del mismo modo, las aplicaciones pueden usar otros parámetros de URL que solo se controlan del lado del cliente.
La propuesta No-Vary-Search permite que un servidor especifique parámetros que no generan una diferencia en el recurso entregado y, por lo tanto, permite que un navegador reutilice versiones almacenadas en caché previamente de un documento que solo difieren en estos parámetros. Esto es compatible con Chrome (y los navegadores basados en Chromium) para las especulaciones de navegación, tanto para la recuperación previa como para la renderización previa.
Las reglas de especulación admiten el uso de expects_no_vary_search para indicar dónde se espera que se muestre un encabezado HTTP No-Vary-Search. Esto puede ayudar a evitar descargas innecesarias antes de que se vean las respuestas.
<script type="speculationrules">
{
"prefetch": [{
"urls": ["/products"],
"expects_no_vary_search": "params=(\"id\")"
}]
}
</script>
<a href="/products?id=123">Product 123</a>
<a href="/products?id=124">Product 124</a>
En este ejemplo, el código HTML inicial de la página /products es el mismo para los IDs de producto 123 y 124. Sin embargo, el contenido de la página finalmente difiere según la renderización del cliente que usa JavaScript para recuperar los datos del producto con el parámetro de búsqueda id. Por lo tanto, realizamos una recuperación previa de esa URL de forma anticipada, y debería mostrar un encabezado HTTP No-Vary-Search que indique que la página se puede usar para cualquier parámetro de búsqueda id.
Sin embargo, si el usuario hace clic en alguno de los vínculos antes de que se complete la recuperación previa, es posible que el navegador no haya recibido la página /products. En este caso, el navegador no sabe si contendrá el encabezado HTTP No-Vary-Search. Luego, el navegador debe elegir si recupera el vínculo de nuevo o espera a que se complete la recuperación previa para ver si contiene un encabezado HTTP No-Vary-Search. El parámetro de configuración expects_no_vary_search permite que el navegador sepa que se espera que la respuesta de la página contenga un encabezado HTTP No-Vary-Search y que espere a que se complete la recuperación previa.
También puedes agregar varios parámetros a expects_no_vary_search separándolos con un espacio (ya que No-Vary-Search es un encabezado estructurado de HTTP):
"expects_no_vary_search": "params=(\"param1\" \"param2\" \"param3\")"
Restricciones de las reglas de especulación y mejoras futuras
Las reglas de especulación se restringen a las páginas que se abren en la misma pestaña, pero estamos trabajando para reducir esa restricción.
De forma predeterminada, las especulaciones se restringen a las páginas del mismo origen. Especulación de páginas de origen cruzado del mismo sitio (por ejemplo, https://a.example.com podría realizar una renderización previa de una página en https://b.example.com). Para usar esto, la página especulada (https://b.example.com en este ejemplo) debe habilitar la opción incluyendo un encabezado HTTP Supports-Loading-Mode: credentialed-prerender, o Chrome cancelará la especulación.
Las versiones futuras también podrían permitir la renderización previa de páginas de origen cruzado que no sean del mismo sitio, siempre y cuando no existan cookies para la página renderizada previamente y esta habilite la renderización previa con un encabezado HTTP Supports-Loading-Mode: uncredentialed-prerender similar.
Las reglas de especulación ya admiten la carga previa de origen cruzado, pero solo cuando no existen cookies para el dominio de origen cruzado. Si existen cookies porque el usuario visitó ese sitio antes, no se usará la especulación y se mostrará un error en Herramientas para desarrolladores.
Dadas esas limitaciones actuales, un patrón que puede mejorar la experiencia de los usuarios tanto para los vínculos internos como para los externos, cuando sea posible, es renderizar previamente las URLs del mismo origen y tratar de realizar una recuperación previa de las URLs de origen cruzado:
<script type="speculationrules">
{
"prerender": [
{
"where": { "href_matches": "/*" },
"eagerness": "moderate"
}
],
"prefetch": [
{
"where": { "not": { "href_matches": "/*" } },
"eagerness": "moderate"
}
]
}
</script>
La restricción para evitar especulaciones de origen cruzado para vínculos de origen cruzado de forma predeterminada es necesaria para la seguridad. Es una mejora con respecto a <link rel="prefetch"> para los destinos de origen cruzado, que tampoco enviarán cookies, pero intentarán la recuperación previa, lo que generará una recuperación previa desperdiciada que deberá volver a enviarse o, peor aún, la carga de la página incorrecta.
Detecta la compatibilidad con la API de Speculation Rules
Puedes detectar la compatibilidad con la API de Speculation Rules con verificaciones HTML estándar:
if (HTMLScriptElement.supports && HTMLScriptElement.supports('speculationrules')) {
console.log('Your browser supports the Speculation Rules API.');
}
Agrega reglas de especulación de forma dinámica a través de JavaScript
Este es un ejemplo de cómo agregar una regla de especulación prerender con JavaScript:
if (HTMLScriptElement.supports &&
HTMLScriptElement.supports('speculationrules')) {
const specScript = document.createElement('script');
specScript.type = 'speculationrules';
specRules = {
prerender: [
{
urls: ['/next.html'],
},
],
};
specScript.textContent = JSON.stringify(specRules);
console.log('added speculation rules to: next.html');
document.body.append(specScript);
}
Puedes ver una demostración de la renderización previa de la API de Speculation Rules con la inserción de JavaScript en esta página de demostración de la renderización previa.
Insertar un elemento <script type = "speculationrules"> directamente en el DOM con innerHTML no registrará las reglas de especulación por motivos de seguridad, y esto se debe agregar como se mostró anteriormente. Sin embargo, las reglas existentes en la página detectarán el contenido insertado de forma dinámica con innerHTML que contenga vínculos nuevos.
Del mismo modo, editar directamente el panel Elements en las Herramientas para desarrolladores de Chrome para agregar el elemento <script type = "speculationrules"> no registra las reglas de especulación y, en cambio, el script para agregar dinámicamente esto al DOM debe ejecutarse desde la consola para insertar las reglas.
Agrega reglas de especulación a través de un administrador de etiquetas
Para agregar reglas de especulación con un administrador de etiquetas como Google Tag Manager (GTM), estas deben insertarse a través de JavaScript, en lugar de agregar el elemento <script type = "speculationrules"> directamente a través de GTM por los mismos motivos que se mencionaron anteriormente:
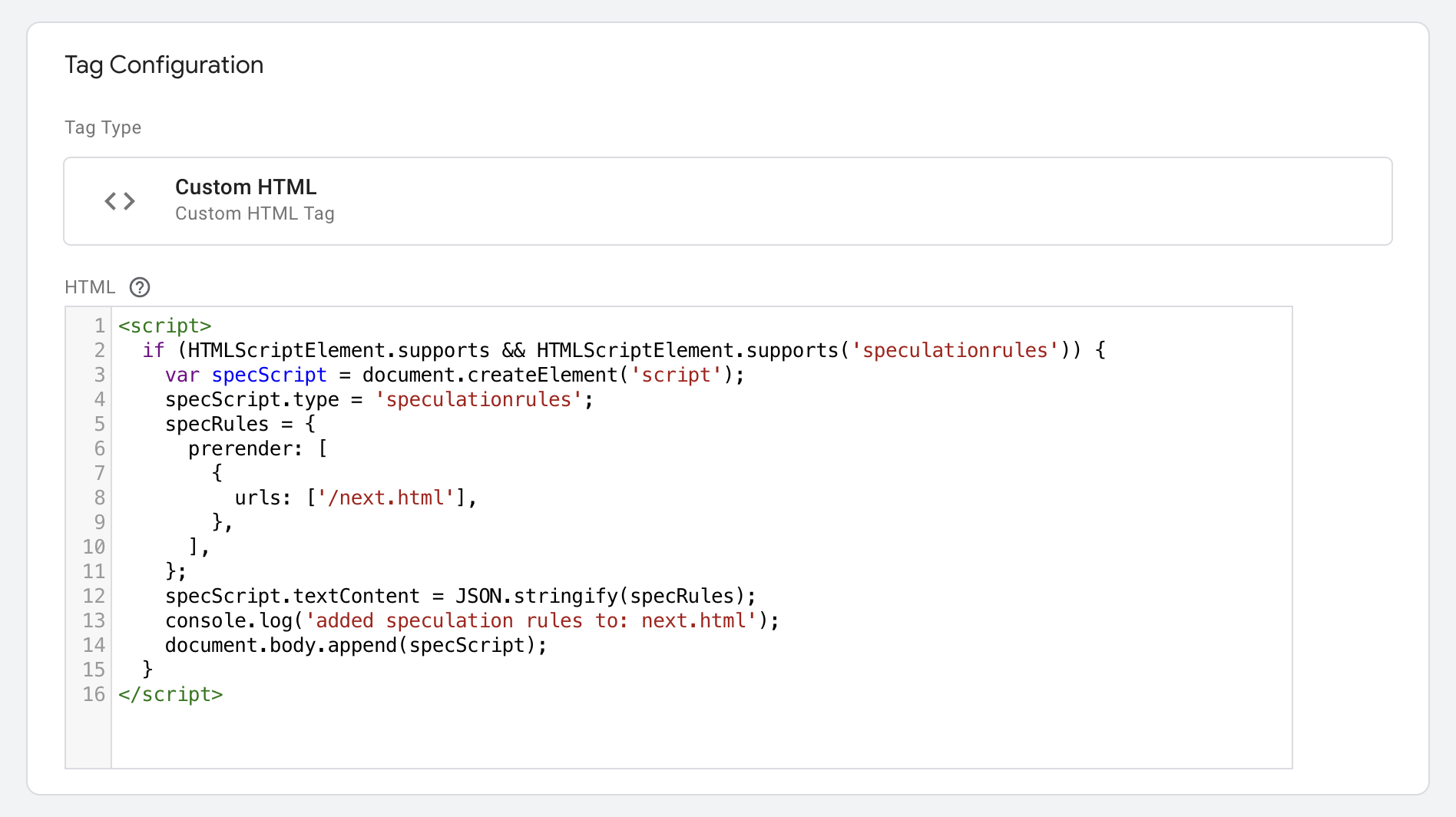
Ten en cuenta que en este ejemplo se usa var, ya que GTM no admite const.
Cancela las reglas de especulación
Si se quitan las reglas de especulación, se cancelará la renderización previa. Sin embargo, cuando esto sucede, es probable que ya se hayan utilizado recursos para iniciar la renderización previa, por lo que se recomienda no realizar la renderización previa si es probable que se deba cancelar. Por otro lado, los recursos almacenados en caché se pueden reutilizar, por lo que las cancelaciones no se desperdician por completo y pueden beneficiar las especulaciones y navegaciones futuras.
Las especulaciones también se pueden cancelar con el encabezado HTTP Clear-Site-Data con las directivas prefetchCache y prerenderCache.
Esto puede ser útil cuando el estado cambia en el servidor. Por ejemplo, cuando se llama a una API de "agregar al carrito" o a una API de acceso o cierre de sesión.
Lo ideal sería que estas actualizaciones de estado se propagaran a las páginas renderizadas previamente con APIs como la API de Broadcast Channel, pero, cuando esto no sea posible o hasta que se implemente esa lógica, cancelar la especulación puede ser más fácil.
Reglas de especulación y Política de Seguridad del Contenido
Como las reglas de especulación usan un elemento <script>, aunque solo contengan JSON, deben incluirse en la script-src Content-Security-Policy si el sitio usa esto, ya sea con un hash o un nonce.
Se puede agregar un nuevo inline-speculation-rules a script-src, lo que permite que se admitan elementos <script type="speculationrules"> insertados desde hash o secuencias de comandos con nonce. Esto no admite las reglas incluidas en el HTML inicial, por lo que JavaScript debe insertar las reglas para los sitios que usan una CSP estricta.
Cómo detectar y deshabilitar la renderización previa
Por lo general, la renderización previa es una experiencia positiva para los usuarios, ya que permite una renderización rápida de la página, a menudo instantánea. Esto beneficia tanto al usuario como al propietario del sitio, ya que las páginas renderizadas previamente permiten una mejor experiencia del usuario que, de otro modo, podría ser difícil de lograr.
Sin embargo, puede haber casos en los que no quieras que se realice la renderización previa de las páginas, por ejemplo, cuando las páginas cambian de estado, ya sea en función de la solicitud inicial o de la ejecución de JavaScript en la página.
Cómo habilitar y deshabilitar la función de renderización previa en Chrome
La función de renderización previa solo está habilitada para los usuarios de Chrome que tienen el parámetro de configuración "Precargar páginas" en chrome://settings/performance/. Además, la renderización previa también se inhabilita en dispositivos con poca memoria o si el sistema operativo está en modo de ahorro de datos o de ahorro de energía. Consulta la sección Límites de Chrome.
Detecta y deshabilita la renderización previa del servidor
Las páginas renderizadas previamente se enviarán con el encabezado HTTP Sec-Purpose:
Sec-Purpose: prefetch;prerender
Las páginas cargadas previamente con la API de Speculation Rules tendrán este encabezado establecido solo en prefetch:
Sec-Purpose: prefetch
Los servidores pueden responder en función de este encabezado para registrar solicitudes de especulación, devolver contenido diferente o evitar que se realice una renderización previa. Si se devuelve un código de respuesta final que no es de éxito (es decir, no está en el rango de 200 a 299 después de los redireccionamientos), la página no se generará previamente y se descartará cualquier página de recuperación previa. Ten en cuenta también que las respuestas 204 y 205 tampoco son válidas para la renderización previa, pero sí para la recuperación previa.
Si no quieres que se realice la renderización previa de una página en particular, devolver un código de respuesta que no sea 2XX (como 503) es la mejor manera de asegurarte de que no suceda. Sin embargo, para brindar la mejor experiencia, se recomienda permitir la renderización previa y, luego, retrasar las acciones que solo deben ocurrir cuando se visualiza la página, mediante JavaScript.
Cómo detectar la renderización previa en JavaScript
La API de document.prerendering devolverá true mientras se realiza la renderización previa de la página. Las páginas pueden usarlo para evitar o retrasar ciertas actividades durante la renderización previa hasta que se active la página.
Una vez que se activa un documento renderizado previamente, el activationStart de PerformanceNavigationTiming también se establecerá en un tiempo distinto de cero que represente el tiempo transcurrido entre el momento en que se inició la renderización previa y el momento en que se activó el documento.
Puedes tener una función para verificar las páginas renderizadas previamente y renderizadas previamente como la siguiente:
function pagePrerendered() {
return (
document.prerendering ||
self.performance?.getEntriesByType?.('navigation')[0]?.activationStart > 0
);
}
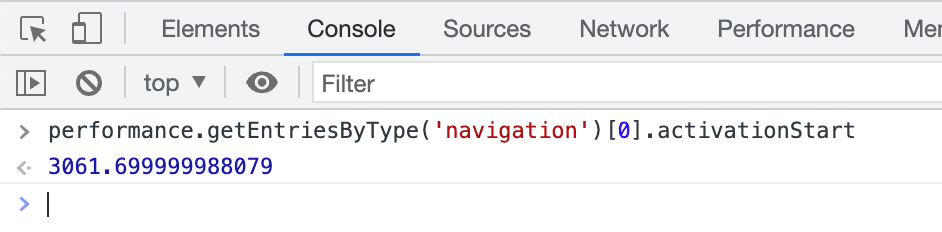
La forma más sencilla de ver si una página se renderizó previamente (ya sea de forma completa o parcial) es abrir las Herramientas para desarrolladores después de que se active la página y escribir performance.getEntriesByType('navigation')[0].activationStart en la consola. Si se devuelve un valor distinto de cero, sabrás que la página se renderizó previamente:
Cuando el usuario activa la página al verla, el evento prerenderingchange se enviará en el objeto document, que luego se puede usar para habilitar actividades que antes se iniciarían de forma predeterminada cuando se cargara la página, pero que deseas retrasar hasta que el usuario vea la página.
Con estas APIs, el JavaScript de frontend puede detectar las páginas renderizadas previamente y actuar en consecuencia de forma adecuada.
Impacto en las estadísticas
Las estadísticas se utilizan para medir el uso del sitio web, por ejemplo, con Google Analytics para medir las vistas de página y los eventos. También puedes medir las métricas de rendimiento de las páginas con la supervisión de usuarios reales (RUM).
Las páginas solo deben renderizarse previamente cuando haya una alta probabilidad de que el usuario las cargue. Por eso, las opciones de renderización previa de la barra de direcciones de Chrome solo se muestran cuando hay una probabilidad tan alta (más del 80% de las veces).
Sin embargo, en particular cuando se usa la API de Speculation Rules, las páginas renderizadas previamente pueden tener un impacto en las estadísticas, y es posible que los propietarios de sitios deban agregar código adicional para habilitar las estadísticas solo para las páginas renderizadas previamente en la activación, ya que no todos los proveedores de estadísticas pueden hacer esto de forma predeterminada.
Esto se puede lograr usando un Promise que espere el evento prerenderingchange si se está realizando una renderización previa de un documento o que se resuelva de inmediato si ya se realizó:
// Set up a promise for when the page is activated,
// which is needed for prerendered pages.
const whenActivated = new Promise((resolve) => {
if (document.prerendering) {
document.addEventListener('prerenderingchange', resolve, {once: true});
} else {
resolve();
}
});
async function initAnalytics() {
await whenActivated;
// Initialise your analytics
}
initAnalytics();
Un enfoque alternativo es retrasar las actividades de Analytics hasta que la página se haga visible por primera vez, lo que abarcaría el caso de la renderización previa y también cuando se abren pestañas en segundo plano (por ejemplo, con el clic derecho y la opción para abrir en una pestaña nueva):
// Set up a promise for when the page is first made visible
const whenFirstVisible = new Promise((resolve) => {
if (document.hidden) {
document.addEventListener('visibilitychange', resolve, {once: true});
} else {
resolve();
}
});
async function initAnalytics() {
await whenFirstVisible;
// Initialise your analytics
}
initAnalytics();
Si bien esto puede tener sentido para el análisis y casos de uso similares, en otros casos, es posible que desees que se cargue más contenido, por lo que tal vez quieras usar document.prerendering y prerenderingchange para segmentar específicamente las páginas de renderización previa.
Cómo retener otro contenido durante la renderización previa
Las mismas APIs que se analizaron anteriormente se pueden usar para retener otro contenido durante la fase de renderización previa. Pueden ser partes específicas de JavaScript o elementos de secuencia de comandos completos que prefieras no ejecutar durante la etapa de procesamiento previo.
Por ejemplo, dada esta secuencia de comandos:
<script src="https://example.com/app/script.js" async></script>
Puedes cambiarlo por un elemento de secuencia de comandos insertado de forma dinámica que solo se inserte según la función whenActivated anterior:
async function addScript(scriptUrl) {
await whenActivated;
const script = document.createElement('script');
script.src = 'scriptUrl';
document.body.appendChild(script);
}
addScript('https://example.com/app/script.js');
Esto puede ser útil para retener secuencias de comandos distintas que incluyen estadísticas o renderizar contenido según el estado o cualquier otra variable que pueda cambiar durante el transcurso de una visita. Por ejemplo, las recomendaciones, el estado de acceso o los íconos del carrito de compras podrían retenerse para garantizar que se presente la información más actualizada.
Si bien es posible que esto suceda con más frecuencia con el uso de la renderización previa, estas condiciones también se aplican a las páginas cargadas en las pestañas en segundo plano mencionadas anteriormente (por lo que la función whenFirstVisible se podría usar en lugar de whenActivated).
En muchos casos, lo ideal es que el estado también se verifique en los cambios generales de visibilitychange, por ejemplo, cuando se vuelve a una página que se ejecutó en segundo plano, se deben actualizar todos los contadores del carrito de compras con la cantidad más reciente de artículos en el carrito. Por lo tanto, este no es un problema específico del renderizado previo, sino que el renderizado previo solo hace que un problema existente sea más evidente.
Una forma en que Chrome mitiga la necesidad de encapsular manualmente algunos de los scripts o funciones es que ciertas APIs se retienen, como se mencionó anteriormente, y tampoco se renderizan los iframes de terceros, por lo que solo el contenido que se encuentra sobre estos debe retenerse manualmente.
Medir el rendimiento
Para medir las métricas de rendimiento, Analytics debe considerar si es mejor medirlas en función del tiempo de activación en lugar del tiempo de carga de la página que informarán las APIs del navegador.
En el caso de las métricas web esenciales, que Chrome mide a través del Informe sobre la experiencia del usuario en Chrome, el objetivo es medir la experiencia del usuario. Por lo tanto, se miden según el tiempo de activación. Por ejemplo, esto suele generar un LCP de 0 segundos, lo que demuestra que es una excelente manera de mejorar tus Métricas web esenciales.
A partir de la versión 3.1.0, se actualizó la biblioteca web-vitals para controlar las navegaciones previas a la renderización de la misma manera en que Chrome mide las Core Web Vitals. Esta versión también marca las navegaciones previas a la renderización para esas métricas en el atributo Metric.navigationType si la página se renderizó previamente de forma total o parcial.
Cómo medir las renderizaciones previas
Se puede ver si una página se renderizó previamente con una entrada activationStart distinta de cero de PerformanceNavigationTiming. Luego, esto se puede registrar con una dimensión personalizada o similar cuando se registran las vistas de página, por ejemplo, con la función pagePrerendered que se describió anteriormente:
// Set Custom Dimension for Prerender status
gtag('set', { 'dimension1': pagePrerendered() });
// Initialise GA - including sending page view by default
gtag('config', 'G-12345678-1');
Esto permitirá que tus estadísticas muestren cuántas navegaciones se generan previamente en comparación con otros tipos de navegación y también te permitirá correlacionar cualquier métrica de rendimiento o métrica comercial con estos diferentes tipos de navegación. Las páginas más rápidas generan más satisfacción entre los usuarios, lo que suele tener un impacto real en las métricas comerciales, como lo demuestran nuestros casos de éxito.
A medida que mides el impacto comercial de las páginas renderizadas previamente para las navegaciones instantáneas, puedes decidir si vale la pena invertir más esfuerzo en usar esta tecnología para permitir que se rendericen previamente más navegaciones o investigar por qué no se renderizan previamente las páginas.
Cómo medir las tasas de aciertos
Además de medir el impacto de las páginas que se visitan después de una renderización previa, también es importante medir las páginas que se renderizan previamente y que no se visitan posteriormente. Esto podría implicar que estás realizando una renderización previa excesiva y que estás consumiendo recursos valiosos del usuario con poco beneficio.
Esto se puede medir activando un evento de Analytics cuando se insertan reglas de especulación (después de verificar que el navegador admita la renderización previa con HTMLScriptElement.supports('speculationrules')) para indicar que se solicitó la renderización previa. (Ten en cuenta que el hecho de que se haya solicitado una renderización previa no indica que se haya iniciado o completado, ya que, como se mencionó anteriormente, una renderización previa es una sugerencia para el navegador, y este puede optar por no renderizar previamente las páginas según la configuración del usuario, el uso actual de la memoria o cualquier otra heurística).
Luego, puedes comparar la cantidad de estos eventos con las vistas de página reales de la página renderizada previamente. O bien, activa otro evento en la activación si eso facilita la comparación.
Luego, se puede aproximar el "porcentaje de aciertos" observando la diferencia entre estas dos cifras. En el caso de las páginas en las que usas la API de Speculation Rules para realizar la renderización previa, puedes ajustar las reglas de forma adecuada para asegurarte de mantener una tasa de aciertos alta y mantener el equilibrio entre usar los recursos de los usuarios para ayudarlos y usarlos innecesariamente.
Ten en cuenta que es posible que se esté realizando una renderización previa debido a la renderización previa de la barra de direcciones y no solo a tus reglas de especulación. Puedes verificar document.referrer (que estará en blanco para la navegación en la barra de direcciones, incluidas las navegaciones en la barra de direcciones renderizadas previamente) si deseas diferenciarlas.
Recuerda que también debes consultar las páginas que no tienen renderización previa, ya que esto podría indicar que no son aptas para la renderización previa, incluso desde la barra de direcciones. Esto puede significar que no te estás beneficiando de esta mejora del rendimiento. El equipo de Chrome busca agregar herramientas adicionales para probar la elegibilidad del prerrenderizado, tal vez similares a la herramienta de prueba de la bfcache, y también podría agregar una API para exponer por qué falló un prerrenderizado.
Impacto en las extensiones
Consulta la publicación dedicada a las Extensiones de Chrome: Ampliación de la API para admitir la Navegación instantánea, en la que se detallan algunas consideraciones adicionales que los autores de extensiones pueden tener que tener en cuenta para las páginas renderizadas previamente.
Comentarios
El equipo de Chrome está desarrollando activamente la función de procesamiento previo, y hay muchos planes para ampliar el alcance de lo que se puso a disposición en la versión de Chrome 108. Agradecemos cualquier comentario sobre el repo de GitHub o el uso de nuestra herramienta de seguimiento de problemas, y esperamos escuchar y compartir casos de éxito de esta nueva y emocionante API.
Vínculos relacionados
- Codelab de Speculation Rules
- Cómo depurar reglas de especulación
- Presentamos la recuperación previa sin estado
- Especificación de la API de Speculation Rules
- El repositorio de GitHub de Navigational speculation
- Extensiones de Chrome: Ampliación de la API para admitir la Navegación instantánea
Agradecimientos
Imagen en miniatura de Marc-Olivier Jodoin en Unsplash