


Setting up a consistent testing environment with GPUs can be harder than expected. Here are the steps to test client-side, browser-based AI models in true browser environments, while also being scalable, automatable, and within a known standardized hardware setup.
In this instance, the browser is a real Chrome browser with hardware support, as opposed to software emulation.
Whether you're a Web AI, web gaming, or graphics developer, or you find yourself interested in Web AI model testing, this guide is for you.
Step 1: Create a new Google Colab notebook
1. Go to colab.new to create a new Colab notebook. It should look similar to figure 1. 2. Follow the prompt to sign into your Google Account.
Step 2: Connect to a T4 GPU-enabled server
- Click Connect near the top right of the notebook.
- Select Change runtime type:
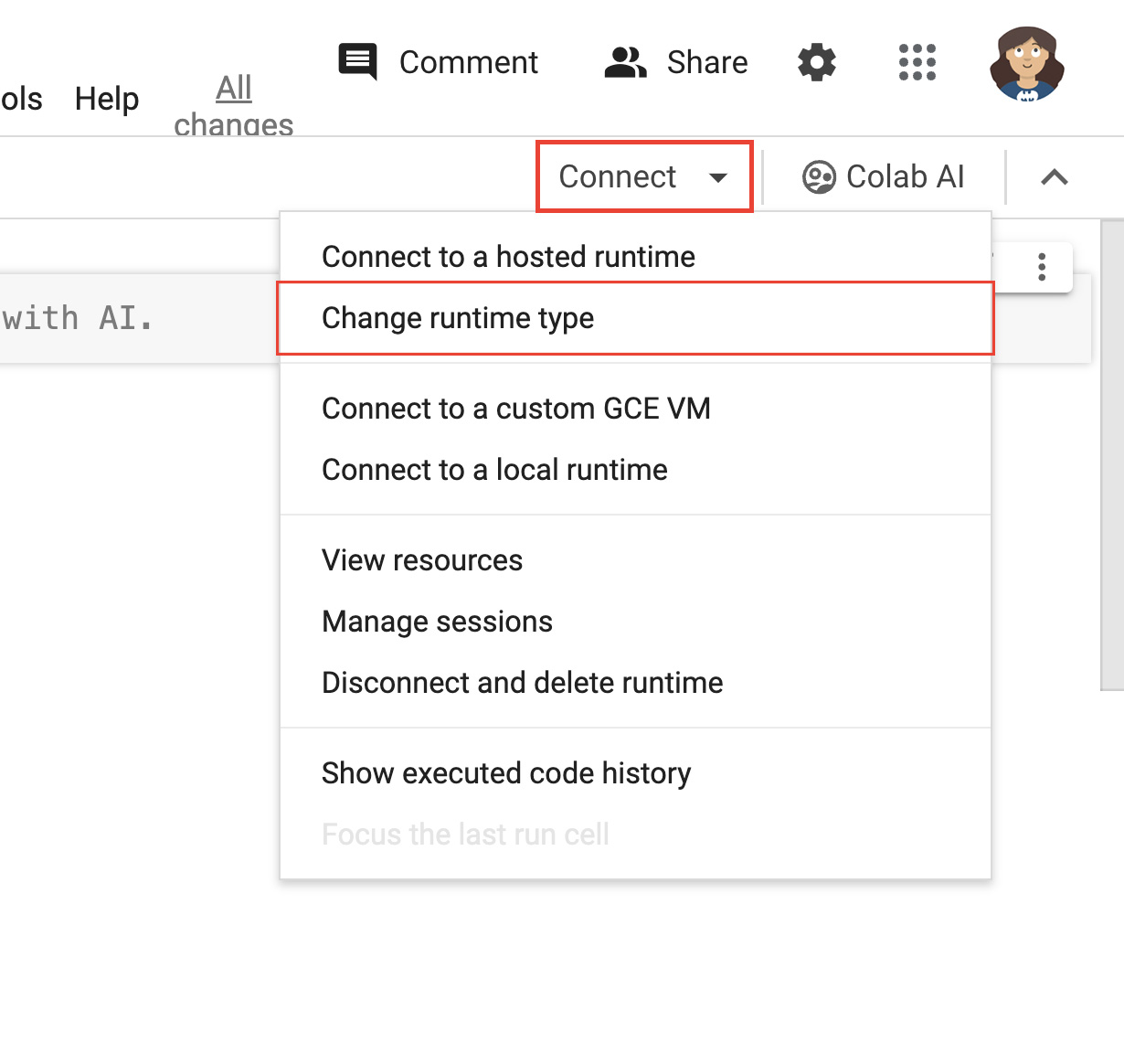
Figure 2. Change the runtime in the Colab interface. - In the modal window, select T4 GPU as your hardware accelerator. When you connect, Colab will use a Linux instance with an NVIDIA T4 GPU attached.
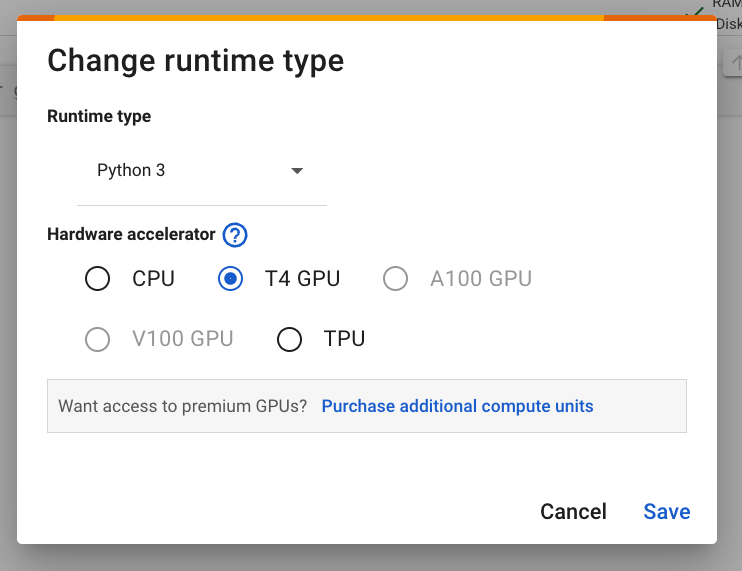
Figure 3: Under Hardware accelerator, select T4 GPU. - Click Save.
- Click the Connect button to connect to your runtime. After some time, the button will present a green checkmark, along with RAM and disk usage graphs. This indicates that a server has successfully been created with your required hardware.
Nice work, you just created a server with a GPU attached.
Step 3: Install correct drivers and dependencies
Copy and paste the following two lines of code into the first code cell of the notebook. In a Colab environment, command line execution is prepended with an exclamation mark.
!git clone https://github.com/jasonmayes/headless-chrome-nvidia-t4-gpu-support.git !cd headless-chrome-nvidia-t4-gpu-support && chmod +x scriptyMcScriptFace.sh && ./scriptyMcScriptFace.sh- You can inspect the script on GitHub to see the raw command line code this script executes.
# Update, install correct drivers, and remove the old ones. apt-get install -y vulkan-tools libnvidia-gl-525 # Verify NVIDIA drivers can see the T4 GPU and that vulkan is working correctly. nvidia-smi vulkaninfo --summary # Now install latest version of Node.js npm install -g n n lts node --version npm --version # Next install Chrome stable curl -fsSL https://dl.google.com/linux/linux_signing_key.pub | sudo gpg --dearmor -o /usr/share/keyrings/googlechrom-keyring.gpg echo "deb [arch=amd64 signed-by=/usr/share/keyrings/googlechrom-keyring.gpg] http://dl.google.com/linux/chrome/deb/ stable main" | sudo tee /etc/apt/sources.list.d/google-chrome.list sudo apt update sudo apt install -y google-chrome-stable # Start dbus to avoid warnings by Chrome later. export DBUS_SESSION_BUS_ADDRESS="unix:path=/var/run/dbus/system_bus_socket" /etc/init.d/dbus startClick next to the cell to execute the code.
Figure 4. Once the code finishes executing, verify
nvidia-smiprinted out something similar to the following screenshot to confirm you do indeed have a GPU attached and it's recognized on your server. You may need to scroll to earlier in the logs to view this output.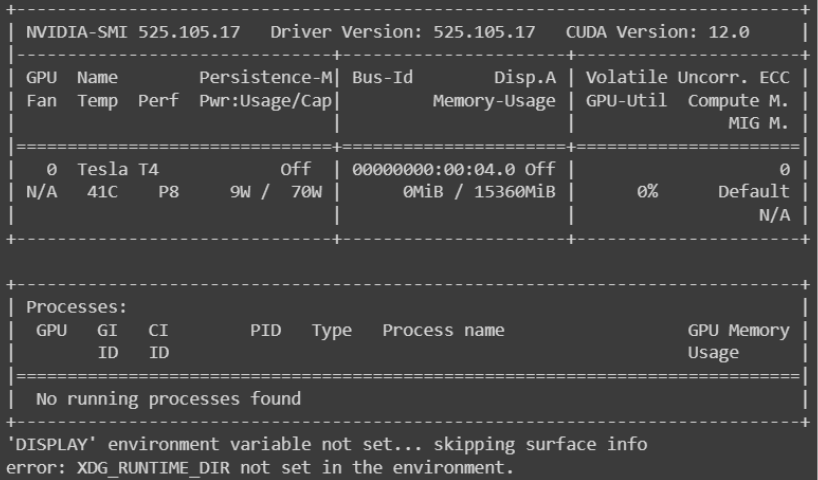
Figure 5: Look for the output which begins with "NVIDIA-SMI".
Step 4: Use and automate headless Chrome
- Click Code button to add a new code cell.
- You can then write your custom code to call a Node.js project with your
preferred parameters (or just call
google-chrome-stabledirectly in the command line). We have examples for both following.
Part A: Use Headless Chrome directly in the command line
# Directly call Chrome to dump a PDF of WebGPU testing page
# and store it in /content/gpu.pdf
!google-chrome-stable \
--no-sandbox \
--headless=new \
--use-angle=vulkan \
--enable-features=Vulkan \
--disable-vulkan-surface \
--enable-unsafe-webgpu \
--print-to-pdf=/content/gpu.pdf https://webgpureport.org
In the example, we stored the resulting PDF capture in /content/gpu.pdf. To
view that file, expand the content .
Then click to download the PDF
file to your local machine.
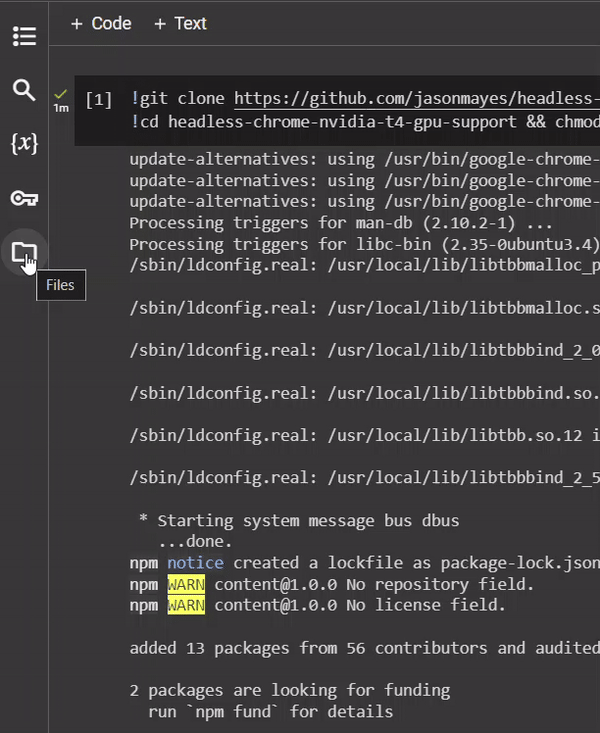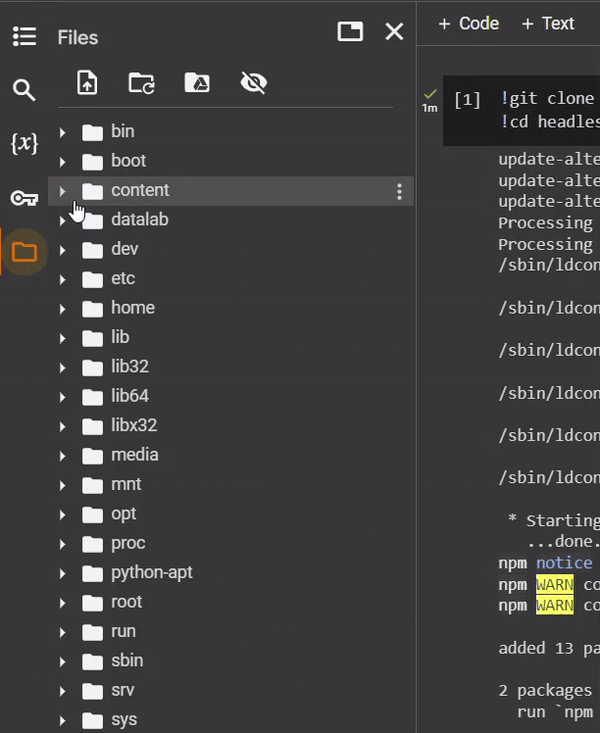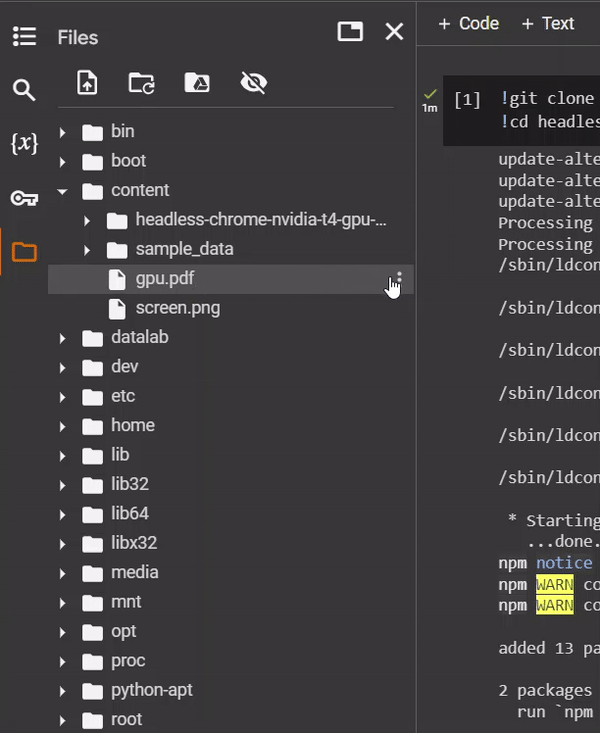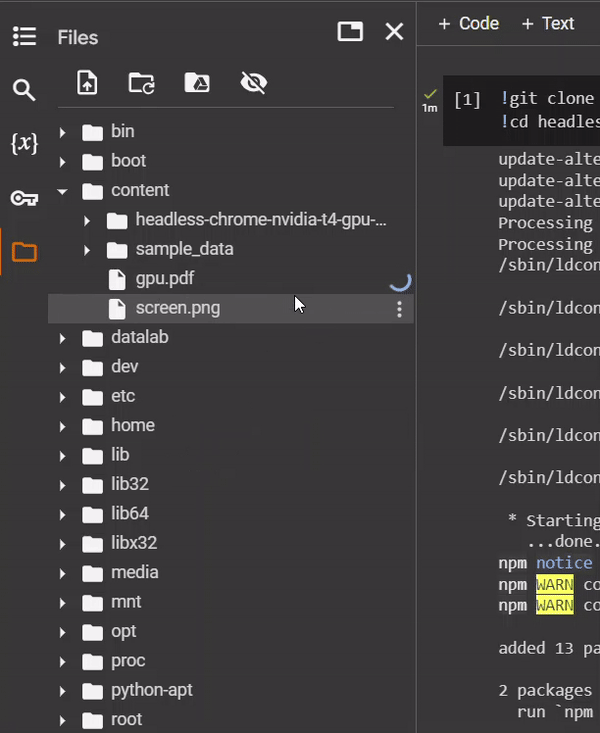
Part B: Command Chrome with Puppeteer
We've provided a minimalist example using Puppeteer to control Headless Chrome that can be run as follows:
# Call example node.js project to perform any task you want by passing
# a URL as a parameter
!node headless-chrome-nvidia-t4-gpu-support/examples/puppeteer/jPuppet.js chrome://gpu
In the jPuppet example, we can call a Node.js script to create a screenshot. But how does this work? Check out this walk through of the Node.js code in jPuppet.js.
jPuppet.js Node code breakdown
First, import Puppeteer. This lets you remotely control Chrome with Node.js:
import puppeteer from 'puppeteer';
Next, check what command line arguments were passed to the Node application. Ensure the third argument is set—which represents a URL to navigate to. You need to inspect the third argument here because the first two arguments call Node itself and the script we are running. The 3rd element actually contains the 1st parameter passed to the Node program:
const url = process.argv[2];
if (!url) {
throw "Please provide a URL as the first argument";
}
Now define an asynchronous function named runWebpage(). This creates a browser
object that's configured with the command line arguments to run the Chrome
binary in the manner we need to get WebGL and WebGPU working as described in
Enable WebGPU and WebGL support.
async function runWebpage() {
const browser = await puppeteer.launch({
headless: 'new',
args: [
'--no-sandbox',
'--headless=new',
'--use-angle=vulkan',
'--enable-features=Vulkan',
'--disable-vulkan-surface',
'--enable-unsafe-webgpu'
]
});
Create a new browser page object which you can later use to visit any URL:
const page = await browser.newPage();
Then, add an event listener to listen for console.log events when the web page
executes JavaScript. This lets you log messages on the Node command line
and also inspect the console text for a special phrase (in this case,
captureAndEnd) that triggers a screenshot and then ends the browser process in
Node. This is useful for web pages that need to do some amount of work before
a screenshot can be taken, and has a non-deterministic amount of time of
execution.
page.on('console', async function(msg) {
console.log(msg.text());
if (msg.text() === 'captureAndEnd') {
await page.screenshot({ path: '/content/screenshotEnd.png' });
await browser.close();
}
});
Finally, command the page to visit the URL specified and grab an initial screenshot when the page has loaded.
If you choose to grab a screenshot of chrome://gpu, you can close the browser
session immediately instead of waiting for any console output, as this page is
not controlled by your own code.
await page.goto(url, { waitUntil: 'networkidle2' });
await page.screenshot({path: '/content/screenshot.png'});
if (url === 'chrome://gpu') {
await browser.close();
}
}
runWebpage();
Modify package.json
You may have noticed that we used an import statement at the start of the
jPuppet.js file. Your package.json must set the type values as module, or
you'll receive an error that the module is invalid.
{
"dependencies": {
"puppeteer": "*"
},
"name": "content",
"version": "1.0.0",
"main": "jPuppet.js",
"devDependencies": {},
"keywords": [],
"type": "module",
"description": "Node.js Puppeteer application to interface with headless Chrome with GPU support to capture screenshots and get console output from target webpage"
}
That's all there is to it. Using Puppeteer makes it easier to interface with Chrome programmatically.
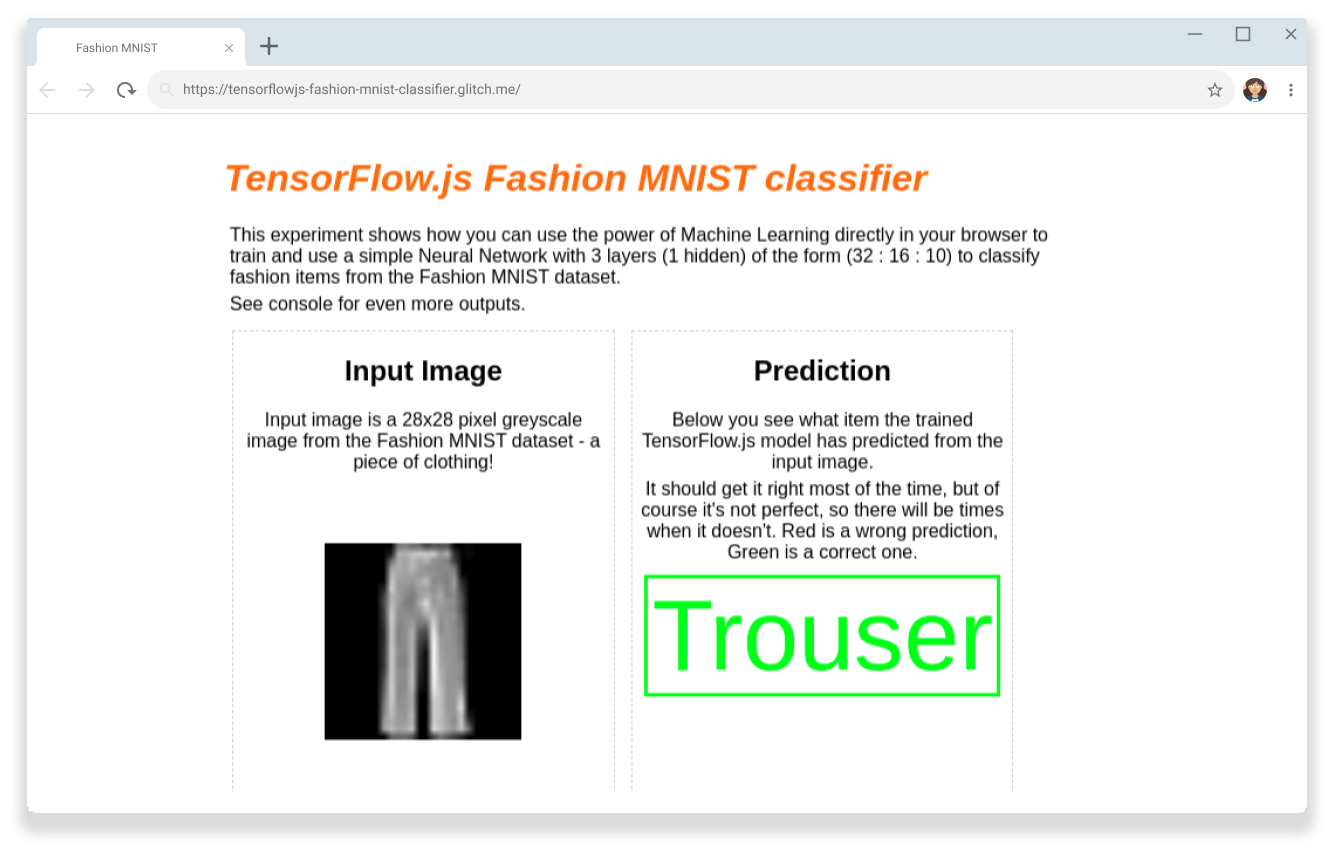
Success
We can now verify that the TensorFlow.js Fashion MNIST classifier can correctly recognize a pair of trousers in an image, with client-side processing in the browser using the GPU.
You can use this for any client-side GPU-based workloads, from machine learning models to graphics and games testing.
Resources
Add a star on the GitHub repo to receive future updates.