

תאריך פרסום: 30 באפריל 2026
בעזרת AI מובנה, האתר או אפליקציית האינטרנט שלכם יכולים לבצע משימות מבוססות-AI, בלי שתצטרכו לפרוס, לנהל או לארח מודלים בעצמכם. יכול להיות שיהיה לכם קשה לעבור מהדגמה לתכונה שמוכנה לייצור. במסמך הזה מפורטים שיקולים טכניים ושיקולים שקשורים לחוויית המשתמש, שיעזרו לכם להימנע מטעויות נפוצות.
הכנת המודל בזמן סביר
רלוונטי לכל ממשקי ה-API, למשל Summarizer, Translator ו-Writer.
פעולות מומלצות: כדאי לאתחל את הסשן ברגע שברור שהמשתמש מתכוון להשתמש בתכונת ה-AI. למשל, כשהמשתמש עובר לממשק של כלי AI רלוונטי, מעביר את העכבר מעל סביבת עבודה של AI או יוצר אינטראקציה עם ממשק המשתמש שמסביב לתכונה. חימום מוקדם של הסשן מאפשר לטעון את המודל לזיכרון בשקט ברקע בזמן שהמשתמש מגדיר את המשימה, וכך נמנעת חביון של התחלה קרה שאפשר למנוע. כדאי לנסות להקדים את התהליך ולהתחיל את משימת ה-AI הבאה שסביר שתצטרכו לבצע ברגע שמתחיל העיבוד של התוצאה הנוכחית. למשל, אם התכונה מיועדת לשימוש איטרטיבי.
לא מומלץ: אלא אם יש צורך בכך, אל תחכו שהמשתמש ילחץ על 'יצירה' כדי לאתחל את הסשן. הדבר גורם לעיכוב בהפעלה במצב התחלתי, כי המודל צריך קודם להיטען לזיכרון ולהכין את צינור הביצוע שלו.
הגדרת הנחיות ראשוניות במהלך היצירה
רלוונטי ל: Prompt API.
מומלץ: לספק הוראות למערכת במהלך אתחול הסשן כדי לשפר את המהירות של ההנחיה הראשונה.
אל תעשו את זה: תתחילו עם סשן ריק ותשלחו הוראות למערכת כחלק מהקריאה הראשונה ל-prompt(). הפעולה הזו מגדילה את זמן האחזור כי היא מחייבת את המודל לעבד את ההוראות האלה ברגע האחרון.
// ✅ DO: Create the session as early as possible (tip on warming up the model early) and use initialPrompts for system instructions in the create call
const session = await LanguageModel.create({
initialPrompts: [
{ role: 'system', content: 'You are a helpful assistant specialized in code reviews.' }
]
});
// A few moments later, when the user triggers the AI feature
const review = await session.prompt(`Review the following code:\n\n${code}`);
// ❌ DON'T: Send instructions using prompt() after creation
// const slowerSession = await LanguageModel.create();
// await slowerSession.prompt(`You are a helpful assistant specialized in code reviews.\n\nReview the following code:\n\n${code}`); // Higher latency
שיבוט סשנים למשימות שחוזרות על עצמן
רלוונטי ל: Prompt API.
ב-Prompt API, כל סשן עוקב אחרי ההקשר של השיחה, ומתחשב בכל האינטראקציות הקודמות. השיבוט מעתיק את כל הנתונים מהסשן המקורי, כולל ההנחיות הראשוניות וכל היסטוריית האינטראקציות עד לנקודת השיבוט. לכן, כדאי לתכנן את השימוש כך שיועתקו רק הנתונים שאתם צריכים.
מומלץ:
- יצירת סשן בסיסי: כדי לטפל ביעילות במשימות לא קשורות, צריך ליצור סשן בסיסי שמכיל רק את הוראות המערכת ולא מכיל הקשר שיחה קודם.
- שיבוט של תצורת הבסיס: משתמשים ב-
clone()בסשן הבסיס הזה כדי ליצור משימות חדשות ולחסוך את התקורה של ניתוח מחדש של הוראות המערכת. כך תוכלו ליצור שיחות מקבילות או לאפס משימה למצב הבסיסי שלה.
לא מומלץ:
- אל תשתמשו באותו סשן למשימות לא קשורות, ואל תשכפלו סשן שכבר מכיל היסטוריית אינטראקציות מיותרת. שני הדפוסים האלה עלולים לגרום להקשר קודם לא רלוונטי להפריע למשימה הנוכחית.
- אל תתקשר שוב ושוב אל
create()עם אותן הוראות מערכת. כדי לשפר את הביצועים, כדאי להשתמש במקום זאת בדפוס שיבוט.
// ✅ DO: Create a baseline session and clone it for each new task
const baseSession = await LanguageModel.create({
initialPrompts: [{
role: 'system',
content: 'You are a technical editor...',
}],
});
// Clone the base session once for the first task
const task1 = await baseSession.clone();
const response1 = await task1.prompt("Review this first draft...");
// ... Repeat the cloning pattern for subsequent independent tasks
// Each task starts fresh from the baseline system instructions
// ❌ DON'T:
// Bad performance pattern: repeated create() calls for identical tasks.
// This forces the model to re-parse instructions every time, increasing latency.
// const sessionA = await LanguageModel.create({ initialPrompts: [...] });
// await sessionA.prompt("Task 1...");
// const sessionB = await LanguageModel.create({ initialPrompts: [...] });
// await sessionB.prompt("Task 2...");
// Bad quality pattern: reusing the same session for unrelated tasks.
// const session = await LanguageModel.create();
// await session.prompt("Analyze this financial report...");
// Unrelated task in the same session:
// await session.prompt("Now write a children's story...");
השמדת סשנים שלא בשימוש
הכלל חל על: כל ממשקי ה-API.
מומלץ: להפעיל באופן יזום את destroy() בסשנים שכבר לא צריך, כדי לפנות זיכרון כשלא משתמשים יותר בתכונה מסוימת. אם משתמשים בתבנית שיבוט, צריך לשמור את סשן הבסיס ולמחוק את השיבוטים שכבר לא צריך.
לא מומלץ: להשאיר כמה סשנים גדולים פעילים. כל סשן צורך זיכרון, מה שיוצר שימוש מיותר במשאבים ועלול להפוך לבעיה. הסשנים ינוקו באופן טבעי על ידי איסוף האשפה, אבל קריאה ל-destroy() תפנה זיכרון מהר יותר.
// ✅ DO: Use the clone and destroy it immediately after
const clone = await baseSession.clone();
const response = await clone.prompt("Quick task...");
// Free memory right away: destry the clone, keep the baseSession
clone.destroy();
הצגת תשובות בסטרימינג בצורה בטוחה ויעילה
רלוונטי לכל ממשקי ה-API עם תמיכה בסטרימינג (Prompt, Summarizer, Writer, Rewriter ו-Translator).
מומלץ: להתייחס לכל הפלט של LLM כאל תוכן לא מהימן. צריך לבצע סניטציה של הפלט המלא המשולב, ולא רק של חלקים ממנו, כי קוד זדוני יכול להיות מפוצל בין עדכונים. לפני העיבוד, משתמשים ב-Sanitizer API במקומות שבהם הוא נתמך. כדי למנוע ירידה בביצועים, כדאי להשתמש בכלי לניתוח Markdown בסטרימינג, כמו streaming-markdown.
לא מומלץ: להגדיר ישירות את innerHTML בכל עדכון של נתח. הפעולה הזו איטית, במיוחד כשמדובר בעיצוב מורכב כמו הדגשת תחביר, והיא חשופה להחדרה.
import * as smd from "streaming-markdown";
// Set up virtual buffer and Sanitizer API
const sanitizer = new Sanitizer({
allowElements: ['figure', 'figcaption', 'p', 'br', 'strong', 'em', 'img', 'a'],
allowAttributes: {
'loading': ['img'], 'decoding': ['img'], 'src': ['img'], 'href': ['a']
}
});
// Create an off-screen fragment so the parser doesn't cause flicker
// or trigger XSS in the live DOM during the building process.
const buffer = new DocumentFragment();
const parser = smd.parser_new(buffer);
// Use sanitizer as a gatekeeper / cleaner function so we can combine it with the streaming Markdown parser
function syncSanitized(target, sourceFragment) {
// .sanitize() returns a fresh, clean DocumentFragment
const cleanFragment = sanitizer.sanitize(sourceFragment);
// replaceChildren is the modern high-performance way to swap DOM content
target.replaceChildren(cleanFragment);
}
// Streaming Logic
// `chunks` keeps track of the raw string (useful for logs/debug)
chunks += chunk;
// Let the parser build the DOM incrementally in the buffer.
// This is high-performance because the buffer is not live
smd.parser_write(parser, chunk);
// Use the Sanitizer API to port the content safely to the container.
syncSanitized(container, buffer);
אופטימיזציה של הקלט לשיפור המהירות
הכלל חל על: כל ממשקי ה-API.
מומלץ: להעביר למודל רק את מה שבאמת נחוץ. מסירים כל מה שלא רלוונטי למשימה. במערכי נתונים גדולים, כדאי לספק סקירה כללית קצרה ומבחר קטן של פריטים רלוונטיים.
לא מומלץ: לשלוח לממשקי ה-API טקסט גולמי לא מעובד, מטא-נתונים לא נחוצים, תגי HTML או רשימות גדולות לא מסוננות. החביון גדל באופן משמעותי עם גודל הקלט, ולכן יכול להיות שהתכונה מבוססת ה-AI לא תפעל כראוי במכשירים רבים.
// ✅ DO: Send only relevant text
const cleanText = document.querySelector('#article').innerText;
const summary = await Summarizer.summarize(cleanText);
// ❌ DON'T: Send the entire DOM structure
// const dirtyText = document.querySelector('#article').innerHTML;
שימוש בפלט מובנה לתוצאות צפויות
רלוונטי ל: Prompt API.
מומלץ: כשרוצים שהמודל יחזיר נתונים בפורמט ספציפי, כדאי להשתמש בפלט מובנה על ידי הוספת שדה responseConstraint כדי לספק סכימת JSON. כך תוכלו לוודא שהפלט צפוי ולא תצטרכו לבצע עיבוד מורכב או ניתוח ידני.
לא מומלץ: להסתמך רק על הוראות בשפה טבעית (כמו 'פלט רק של JSON'). יכול להיות שהמודלים יכללו מילות קישור שמשבשות את מנתח התוכן.
// ✅ DO: Use a JSON Schema for predictable results
const schema = {
type: "object",
properties: {
isTopicCats: { type: "boolean" }
}
};
const result = await session.prompt(`Is this post about cats?\n\n${post}`, {
responseConstraint: schema,
});
console.log(JSON.parse(result).isTopicCats);
הפרדה בין יצירת הסרטון לבין מגבלות האורך
רלוונטי ל-Prompt API, כי זה ה-API היחיד שתומך בסכימות של פלט מובנה.
מומלץ: לאפשר למודל ליצור את התשובה שלו באופן טבעי, ואז להשתמש בלוגיקה בצד הלקוח כדי לחתוך את הטקסט כך שיתאים לממשק המשתמש.
לא מומלץ: להגביל את מספר התווים באמצעות maxLength: 125 סכימות של פלט מובנה. אם התשובה של המודל ארוכה יותר מהמגבלה שהגדרתם, יכול להיות שהמודל יעבור לטוקנים בצפיפות גבוהה, כמו שפות זרות או אמוג'י, כדי לדחוס את המשמעות, וכתוצאה מכך הפלט יהיה חסר משמעות.
/* DO: Handle overflow using CSS */
.result {
overflow: hidden;
white-space: nowrap;
text-overflow: ellipsis; /* Displays '…' */
}
// ❌ DON'T: Force length in the prompt
const result = await session.prompt("Write a bio in exactly 50 characters.");
עדכון המשתמש
הכלל חל על: כל ממשקי ה-API.
מומלץ: בהתאם למורכבות ולמשך הצפוי של המשימה, כדאי להשתמש באנימציות, ברמזים חזותיים ובאינדיקטורים של התקדמות כדי לעדכן את המשתמש. הגישה האופטימלית תלויה בתרחיש לדוגמה ובאורך הצפוי של הפלט של ה-API. הנה כמה רעיונות:
- סטרימינג של תוכן ארוך: בסיכומים או בצ'אט, הסטרימינג יוצר כברירת מחדל אפקט של מכונת כתיבה לכל טוקן. השיטה הזו נראית טבעית ומספקת משוב מיידי.
- לא סטרימינג למשימות קצרות (או למשימות אסינכרוניות ארוכות): אם הפלט קצר, למשל טקסט חלופי, אפשר ליצור ממשק משתמש מלוטש יותר בלי סטרימינג. בנוסף, הוא מאפשר להכין מראש את משימת ה-AI הבאה בזמן שהמשימה הנוכחית עוברת עיבוד. הגישה הזו מתאימה גם למשימות ארוכות אסינכרוניות או למשימות ברקע. אם המשתמש לא נחסם בפלט כדי להמשיך בתהליך, אין צורך דחוף ליצור את הפלט בזמן שהוא מתרחש. לסמן בממשק המשתמש שהתהליך מתבצע.
- מעברים חזותיים לעדכונים: כשמתרגמים או משכתבים טקסט, משתמשים באנימציות, למשל, שינוי צורה של מילה.
אל: תעדכנו את ממשק המשתמש בלי רמזים חזותיים.
התאמה למודל המנטלי של המשתמש לגבי זמן ועבודה
הכלל חל על: כל ממשקי ה-API.
מומלץ: אם התשובה כמעט מיידית, כדאי להוסיף עיכוב מלאכותי של שנייה או שתיים. באופן פרדוקסלי, יכול להיות שמשתמשים ימצאו תוצאות אמינות יותר אם הם יתפסו את תהליך היצירה כמתאים לרמת הקושי של המשימה. להשתמש באנימציות כדי לציין שתהליך AI התרחש.
אל: תפתיעו את המשתמשים בהחלפות מיידיות של ממשק המשתמש.
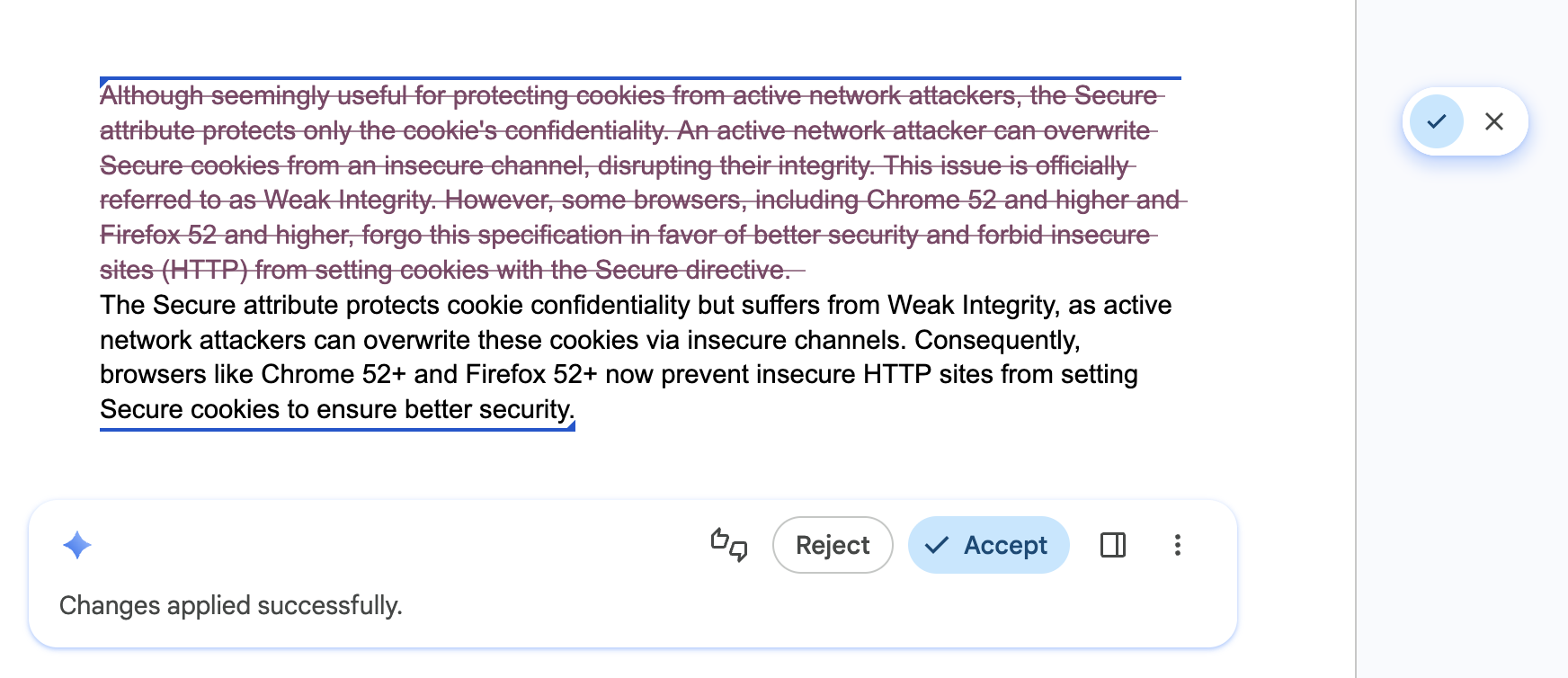
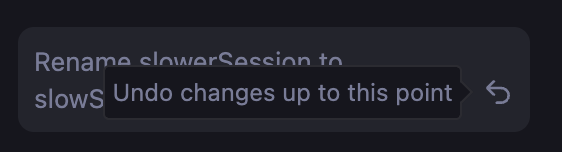
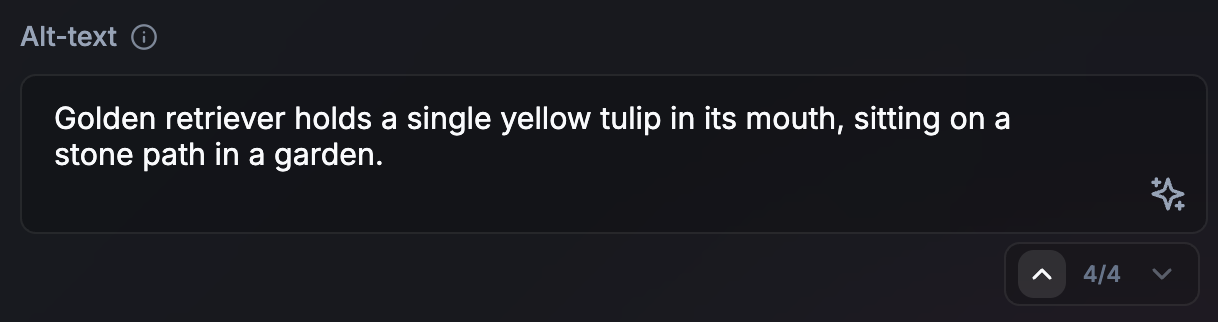
המשתמשים יכולים לנווט במהירות ולבטל עריכות שבוצעו על ידי AI
הכלל חל על: כל ממשקי ה-API.
מומלץ: להוסיף לממשק המשתמש רכיב של מעבר בין שלבים או היסטוריית ניווט, כדי לאפשר למשתמשים לבדוק תוצאות שונות בביטחון, ולבטל במהירות עריכות שבוצעו על ידי AI. כך תוכלו לוודא שגרסאות שונות עדיין יהיו זמינות בקלות.
אל: תדרוס את הטיוטה הקודמת של המשתמש או תוצאה של AI שהוא אולי אהב, בלי אפשרות לחזור אחורה, לבטל את הפעולה או להשוות בין הגרסאות.
הענקת שליטה למשתמשים והרשאות עקיפה
הכלל חל על: כל ממשקי ה-API.
מומלץ: להגדיר את המשתמש כעורך הסופי של כל התוכן שנוצר. לספק ביטולים אינטואיטיביים כדי שהמשתמש ישמור על בעלות מלאה על הפלט הסופי. יכול להיות שה-API יפיק תוצאות שגויות.
לא כדאי: להגדיר תוצאה שנוצרה על ידי AI כאפשרות היחידה.
שמירת תוצאות במטמון למשימות חוזרות
הכלל חל על: כל ממשקי ה-API.
מומלץ: להטמיע מטמון של תוצאות מקומיות (לדוגמה, באמצעות sessionStorage או IndexedDB) עבור קלט או שאילתות חוזרים. כדי להגדיל את מספר הפעמים שהמערכת מוצאת את הנתונים במטמון, צריך לבצע נורמליזציה של הקלט על ידי הסרת רווחים מיותרים והפיכת האותיות לאותיות קטנות. לגבי קלט כבד, למשל תמונות, צריך ליצור גיבוב לשימוש כמפתח מטמון. מגדירים אורך חיים (TTL) שמרני למטמון (או מציגים תוצאות מהמטמון בזמן העדכון שלהן ברקע). לאפשר למשתמש להפעיל הסקה חדשה אם התוצאה לא מספקת.
אסור: להריץ מחדש את אותה מסקנה לשאילתת חיפוש חוזרת או לקלט נתונים זהה, במקרים שבהם לא רצוי להשתמש במשתנים, למשל כשמשתמש מנווט קדימה ואחורה בין תוצאות חיפוש. כך משפרים את הרספונסיביות ואת השימוש היעיל בחישובים מקומיים.
// ✅ DO: Check a local cache before running inference
async function getAiResponse(userInput, forceRefresh = false) {
// Normalize the query to increase cache hits
const query = userInput.trim().toLowerCase();
const cacheKey = `ai_results_${query}`;
const TTL_MS = 3600000; // 1 hour conservative TTL
if (!forceRefresh) {
const itemStr = localStorage.getItem(cacheKey);
if (itemStr) {
const item = JSON.parse(itemStr);
const now = Date.now();
// Check if the item has expired
if (now < item.expiry) {
// Lightweight safety check before rendering
if (isValid(item.value)) return item.value;
} else {
// Delete the stale entry if the TTL has passed
localStorage.removeItem(cacheKey);
}
}
}
// Fallback: Run inference if no valid cache exists
const session = await LanguageModel.create();
const response = await session.prompt(userInput);
// Store the result for future use (with an expiration)
const cacheData = {
value: response,
expiry: Date.now() + TTL_MS
};
localStorage.setItem(cacheKey, JSON.stringify(cacheData));
return response;
}