

पब्लिश होने की तारीख: 30 अप्रैल, 2026
एआई की सुविधा पहले से मौजूद होने की वजह से, आपकी वेबसाइट या वेब ऐप्लिकेशन एआई की मदद से टास्क पूरे कर सकता है. इसके लिए, आपको मॉडल डिप्लॉय, मैनेज या सेल्फ-होस्ट करने की ज़रूरत नहीं होती. आपको डेमो से प्रोडक्शन के लिए तैयार सुविधा पर जाने में मुश्किल हो सकती है. इस दस्तावेज़ में, तकनीकी और यूज़र एक्सपीरियंस से जुड़ी बातों के बारे में बताया गया है. इससे आपको आम तौर पर होने वाली गलतियों से बचने में मदद मिलेगी.
मॉडल को सही समय पर तैयार करें
इन पर लागू होता है: सभी एपीआई. जैसे, Summarizer, Translator, और Writer.
यह करें: जैसे ही आपको पता चले कि उपयोगकर्ता को एआई की सुविधा का इस्तेमाल करना है, वैसे ही सेशन शुरू करें. उदाहरण के लिए, जब कोई उपयोगकर्ता एआई टूल से जुड़े किसी पेज पर जाता है, एआई वर्कस्पेस पर कर्सर घुमाता है या सुविधा के आस-पास मौजूद यूज़र इंटरफ़ेस (यूआई) से इंटरैक्ट करता है. सेशन को पहले से चालू करने से, मॉडल को बैकग्राउंड में चुपचाप मेमोरी में लोड होने की अनुमति मिलती है. इस दौरान, उपयोगकर्ता अपना टास्क सेट अप कर रहा होता है. इससे, कोल्ड-स्टार्ट लेटेंसी से बचा जा सकता है. मौजूदा नतीजे को रेंडर करना शुरू करने के तुरंत बाद, एआई से जुड़ा अगला टास्क शुरू करें. इससे आपको एक कदम आगे रहने में मदद मिलेगी. उदाहरण के लिए, अगर सुविधा को बार-बार इस्तेमाल करने के लिए डिज़ाइन किया गया है, तो ऐसा करें.
ऐसा न करें: जब तक ज़रूरी न हो, तब तक सेशन शुरू करने के लिए उपयोगकर्ता के "जनरेट करें" पर क्लिक करने का इंतज़ार न करें. इस वजह से, कोल्ड स्टार्ट में देरी होती है. ऐसा इसलिए होता है, क्योंकि मॉडल को पहले मेमोरी में लोड करना होता है और फिर उसे एक्ज़ीक्यूशन पाइपलाइन तैयार करनी होती है.
जनरेटिव एआई की मदद से ऐसेट बनाते समय शुरुआती प्रॉम्प्ट सेट करना
लागू होता है: Prompt API.
यह करें: सेशन शुरू करते समय सिस्टम को निर्देश दें, ताकि पहले प्रॉम्प्ट का जवाब तेज़ी से मिल सके.
ऐसा न करें: खाली सेशन से शुरू करें और सिस्टम के निर्देशों को पहले prompt() कॉल के हिस्से के तौर पर भेजें. इससे लेटेन्सी बढ़ जाती है, क्योंकि मॉडल को उन निर्देशों को आखिरी समय में प्रोसेस करना पड़ता है.
// ✅ DO: Create the session as early as possible (tip on warming up the model early) and use initialPrompts for system instructions in the create call
const session = await LanguageModel.create({
initialPrompts: [
{ role: 'system', content: 'You are a helpful assistant specialized in code reviews.' }
]
});
// A few moments later, when the user triggers the AI feature
const review = await session.prompt(`Review the following code:\n\n${code}`);
// ❌ DON'T: Send instructions using prompt() after creation
// const slowerSession = await LanguageModel.create();
// await slowerSession.prompt(`You are a helpful assistant specialized in code reviews.\n\nReview the following code:\n\n${code}`); // Higher latency
बार-बार किए जाने वाले टास्क के लिए सेशन क्लोन करना
लागू होता है: Prompt API.
Prompt API के लिए, हर सेशन में बातचीत के कॉन्टेक्स्ट को ट्रैक किया जाता है. इसमें पिछले सभी इंटरैक्शन को ध्यान में रखा जाता है. क्लोन किए गए सेशन में, उसके पैरंट सेशन की सभी चीज़ें शामिल होती हैं. जैसे, शुरुआती प्रॉम्प्ट और क्लोन किए जाने तक की पूरी बातचीत का इतिहास. इसलिए, अपने इस्तेमाल को इस तरह से स्ट्रक्चर करें कि सिर्फ़ ज़रूरी चीज़ें ही इनहेरिट हों.
यह करें:
- एक बुनियादी सेशन बनाएं: अलग-अलग टास्क को असरदार तरीके से मैनेज करने के लिए, एक बुनियादी सेशन बनाएं. इसमें सिर्फ़ सिस्टम के निर्देश शामिल हों और बातचीत का पिछला कॉन्टेक्स्ट न हो.
- बेसलाइन को क्लोन करें: नए टास्क के लिए, उस बेस सेशन पर
clone()का इस्तेमाल करें, ताकि सिस्टम के निर्देशों को फिर से पार्स करने का समय बचाया जा सके. इससे, एक साथ कई बातचीत की जा सकती हैं या किसी टास्क को उसकी शुरुआती स्थिति में रीसेट किया जा सकता है.
यह न करें:
- एक ही सेशन का इस्तेमाल, अलग-अलग टास्क के लिए न करें. साथ ही, ऐसे सेशन को क्लोन करने से बचें जिसमें पहले से ही गैर-ज़रूरी इंटरैक्शन का इतिहास मौजूद हो. इन दोनों पैटर्न की वजह से, पिछले कॉन्टेक्स्ट की ऐसी जानकारी मिल सकती है जो आपके मौजूदा टास्क से जुड़ी नहीं है.
- सिस्टम के एक जैसे निर्देशों के साथ,
create()को बार-बार कॉल न करें. परफ़ॉर्मेंस को ऑप्टिमाइज़ करने के लिए, क्लोनिंग पैटर्न का इस्तेमाल करें.
// ✅ DO: Create a baseline session and clone it for each new task
const baseSession = await LanguageModel.create({
initialPrompts: [{
role: 'system',
content: 'You are a technical editor...',
}],
});
// Clone the base session once for the first task
const task1 = await baseSession.clone();
const response1 = await task1.prompt("Review this first draft...");
// ... Repeat the cloning pattern for subsequent independent tasks
// Each task starts fresh from the baseline system instructions
// ❌ DON'T:
// Bad performance pattern: repeated create() calls for identical tasks.
// This forces the model to re-parse instructions every time, increasing latency.
// const sessionA = await LanguageModel.create({ initialPrompts: [...] });
// await sessionA.prompt("Task 1...");
// const sessionB = await LanguageModel.create({ initialPrompts: [...] });
// await sessionB.prompt("Task 2...");
// Bad quality pattern: reusing the same session for unrelated tasks.
// const session = await LanguageModel.create();
// await session.prompt("Analyze this financial report...");
// Unrelated task in the same session:
// await session.prompt("Now write a children's story...");
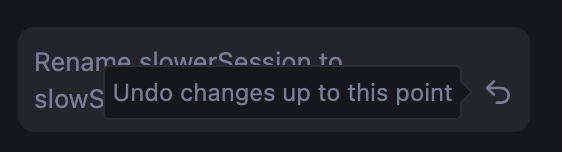
इस्तेमाल नहीं किए गए सेशन मिटाएं
इन पर लागू होता है: सभी एपीआई.
यह करें: जिन सेशन की अब ज़रूरत नहीं है उन्हें साफ़ तौर पर destroy() पर कॉल करें, ताकि जब किसी सुविधा का इस्तेमाल न किया जा रहा हो, तब मेमोरी खाली हो जाए. अगर क्लोनिंग पैटर्न का इस्तेमाल किया जाता है, तो बेस सेशन को बनाए रखें और उन क्लोन को मिटा दें जिनकी अब ज़रूरत नहीं है.
ऐसा न करें: एक साथ कई बड़े सेशन चालू न रखें. हर सेशन मेमोरी का इस्तेमाल करता है. इससे संसाधनों का ज़रूरत से ज़्यादा इस्तेमाल होता है और यह समस्या बन सकती है. सेशन को गार्बेज कलेक्टर अपने-आप मिटा देगा. हालांकि, destroy() को कॉल करने से मेमोरी को ज़्यादा तेज़ी से खाली किया जा सकता है.
// ✅ DO: Use the clone and destroy it immediately after
const clone = await baseSession.clone();
const response = await clone.prompt("Quick task...");
// Free memory right away: destry the clone, keep the baseSession
clone.destroy();
स्ट्रीमिंग के जवाबों को सुरक्षित और असरदार तरीके से रेंडर करना
इन पर लागू होता है: स्ट्रीमिंग की सुविधा वाले सभी एपीआई (प्रॉम्प्ट, जवाब की खास जानकारी देने वाला, लिखने वाला, फिर से लिखने वाला, और अनुवाद करने वाला).
क्या करें: एलएलएम के सभी आउटपुट को अविश्वसनीय कॉन्टेंट के तौर पर मानें. पूरे आउटपुट को साफ़ करें, न कि सिर्फ़ हिस्सों को. ऐसा इसलिए, क्योंकि अपडेट के दौरान नुकसान पहुंचाने वाले कोड को अलग-अलग हिस्सों में बांटा जा सकता है. रेंडर करने से पहले, जहां भी हो सके वहां Sanitizer API का इस्तेमाल करें. परफ़ॉर्मेंस में गिरावट से बचने के लिए, स्ट्रीमिंग मार्कडाउन पार्सर का इस्तेमाल करें. जैसे, streaming-markdown.
ऐसा न करें: हर चंक अपडेट पर सीधे तौर पर innerHTML सेट न करें. यह प्रोसेस धीमी है. खास तौर पर, सिंटैक्स हाइलाइटिंग जैसी जटिल फ़ॉर्मैटिंग के साथ. साथ ही, इसमें इंजेक्शन का खतरा भी होता है.
import * as smd from "streaming-markdown";
// Set up virtual buffer and Sanitizer API
const sanitizer = new Sanitizer({
allowElements: ['figure', 'figcaption', 'p', 'br', 'strong', 'em', 'img', 'a'],
allowAttributes: {
'loading': ['img'], 'decoding': ['img'], 'src': ['img'], 'href': ['a']
}
});
// Create an off-screen fragment so the parser doesn't cause flicker
// or trigger XSS in the live DOM during the building process.
const buffer = new DocumentFragment();
const parser = smd.parser_new(buffer);
// Use sanitizer as a gatekeeper / cleaner function so we can combine it with the streaming Markdown parser
function syncSanitized(target, sourceFragment) {
// .sanitize() returns a fresh, clean DocumentFragment
const cleanFragment = sanitizer.sanitize(sourceFragment);
// replaceChildren is the modern high-performance way to swap DOM content
target.replaceChildren(cleanFragment);
}
// Streaming Logic
// `chunks` keeps track of the raw string (useful for logs/debug)
chunks += chunk;
// Let the parser build the DOM incrementally in the buffer.
// This is high-performance because the buffer is not live
smd.parser_write(parser, chunk);
// Use the Sanitizer API to port the content safely to the container.
syncSanitized(container, buffer);
स्पीड के लिए इनपुट ऑप्टिमाइज़ करना
इन पर लागू होता है: सभी एपीआई.
यह करें: मॉडल को सिर्फ़ ज़रूरी जानकारी दें. जवाब में ऐसी कोई भी जानकारी शामिल न करो जो सवाल के हिसाब से काम की न हो. बड़े डेटासेट के लिए, खास जानकारी दें और काम के आइटम का छोटा सा कलेक्शन उपलब्ध कराएं.
यह न करें: एपीआई को बिना प्रोसेस किया गया टेक्स्ट, गै़र-ज़रूरी मेटाडेटा, एचटीएमएल टैग या फ़िल्टर न की गई बड़ी सूचियां न भेजें. इनपुट साइज़ बढ़ने पर, जवाब मिलने में लगने वाला समय काफ़ी बढ़ जाता है. इस वजह से, कई डिवाइसों पर एआई की सुविधा ठीक से काम नहीं करती.
// ✅ DO: Send only relevant text
const cleanText = document.querySelector('#article').innerText;
const summary = await Summarizer.summarize(cleanText);
// ❌ DON'T: Send the entire DOM structure
// const dirtyText = document.querySelector('#article').innerHTML;
अनुमानित नतीजों के लिए स्ट्रक्चर्ड आउटपुट का इस्तेमाल करना
लागू होता है: Prompt API.
यह करें: जब आपको मॉडल से किसी खास फ़ॉर्मैट में डेटा चाहिए, तब स्ट्रक्चर्ड आउटपुट का इस्तेमाल करें. इसके लिए, responseConstraint फ़ील्ड में JSON स्कीमा दें. इससे यह पक्का होता है कि आउटपुट का अनुमान लगाया जा सकता है. साथ ही, आपको पोस्ट-प्रोसेसिंग या मैन्युअल पार्सिंग की ज़रूरत नहीं पड़ती.
ऐसा न करें: सिर्फ़ नैचुरल लैंग्वेज निर्देशों (जैसे, "सिर्फ़ JSON आउटपुट करें") पर भरोसा न करें. मॉडल में बातचीत के दौरान इस्तेमाल होने वाले ऐसे फ़िलर शामिल हो सकते हैं जो आपके पार्सर को तोड़ देते हैं.
// ✅ DO: Use a JSON Schema for predictable results
const schema = {
type: "object",
properties: {
isTopicCats: { type: "boolean" }
}
};
const result = await session.prompt(`Is this post about cats?\n\n${post}`, {
responseConstraint: schema,
});
console.log(JSON.parse(result).isTopicCats);
जनरेट किए गए जवाब की लंबाई से जुड़ी पाबंदियों को अलग करना
लागू होता है: Prompt API पर, क्योंकि यह ऐसा इकलौता एपीआई है जो स्ट्रक्चर्ड आउटपुट स्कीमा के साथ काम करता है.
यह करें: मॉडल को नैचुरल तरीके से जवाब जनरेट करने दें. इसके बाद, क्लाइंट-साइड लॉजिक का इस्तेमाल करके, टेक्स्ट को अपने यूज़र इंटरफ़ेस (यूआई) के हिसाब से छोटा करें.
ऐसा न करें: स्ट्रक्चर्ड आउटपुट स्कीमा का इस्तेमाल करके, maxLength: 125 जैसे वर्णों की सीमाएं तय न करें. जब किसी मॉडल का जवाब, आपकी तय की गई सीमा से ज़्यादा होता है, तो मॉडल, मतलब को छोटा करने के लिए ज़्यादा डेंसिटी वाले टोकन पर स्विच कर सकता है. जैसे, विदेशी भाषाएँ या इमोजी. इससे बेतुका आउटपुट मिल सकता है.
/* DO: Handle overflow using CSS */
.result {
overflow: hidden;
white-space: nowrap;
text-overflow: ellipsis; /* Displays '…' */
}
// ❌ DON'T: Force length in the prompt
const result = await session.prompt("Write a bio in exactly 50 characters.");
उपयोगकर्ता को जानकारी देते रहना
इन पर लागू होता है: सभी एपीआई.
यह करें: टास्क की मुश्किल और उसके पूरा होने में लगने वाले समय के हिसाब से, एनिमेशन, विज़ुअल क्यू, और प्रोग्रेस इंडिकेटर का इस्तेमाल करें, ताकि उपयोगकर्ता को जानकारी मिलती रहे. सबसे सही तरीका, आपके इस्तेमाल के उदाहरण और एपीआई के आउटपुट की अनुमानित लंबाई पर निर्भर करता है. यहां कुछ आइडिया दिए गए हैं:
- लंबे कॉन्टेंट के लिए स्ट्रीमिंग: खास जानकारी या चैट के लिए, स्ट्रीमिंग की सुविधा डिफ़ॉल्ट रूप से हर टोकन के लिए टाइपराइटर इफ़ेक्ट बनाती है. इससे आपको स्वाभाविक तौर पर और तुरंत सुझाव मिल सकते हैं.
- छोटे टास्क (या लंबे एसिंक टास्क) के लिए नॉन-स्ट्रीमिंग: छोटे आउटपुट के लिए, जैसे कि ऑल्ट-टेक्स्ट, नॉन-स्ट्रीमिंग से बेहतर यूज़र इंटरफ़ेस (यूआई) बनाया जा सकता है. इससे मौजूदा टास्क रेंडर होने के दौरान, अगले एआई टास्क को तैयार करने का समय भी मिलता है. यह तरीका, लंबे समय तक चलने वाले एसिंक्रोनस या बैकग्राउंड टास्क के लिए भी काम करता है. अगर उपयोगकर्ता को जवाब पाने के लिए ब्लॉक नहीं किया गया है, तो जवाब को तुरंत जनरेट करने की कोई ज़रूरत नहीं है. यूज़र इंटरफ़ेस (यूआई) में यह सिग्नल दें कि प्रोसेस जारी है.
- अपडेट के लिए विज़ुअल ट्रांज़िशन: टेक्स्ट का अनुवाद करते समय या उसे फिर से लिखते समय, ऐनिमेशन का इस्तेमाल करें. उदाहरण के लिए, शब्द को बदलना.
यह न करें: विज़ुअल क्यू के बिना यूज़र इंटरफ़ेस (यूआई) को अपडेट न करें.
समय और काम के बारे में उपयोगकर्ता के मेंटल मॉडल के मुताबिक होना चाहिए
इन पर लागू होता है: सभी एपीआई.
क्या करें: अगर जवाब तुरंत मिल जाता है, तो एक या दो सेकंड का आर्टिफ़िशियल डिले जोड़ें. हालांकि, उपयोगकर्ताओं को नतीजे ज़्यादा भरोसेमंद लग सकते हैं, जब उन्हें लगता है कि जनरेट करने की प्रोसेस, टास्क को पूरा करने में आने वाली उनकी मुश्किलों के हिसाब से है. एआई प्रोसेस पूरी होने का सिग्नल देने के लिए, ऐनिमेशन का इस्तेमाल करें.
ऐसा न करें: यूज़र इंटरफ़ेस (यूआई) को तुरंत बदलकर, उपयोगकर्ताओं को हैरान न करें.
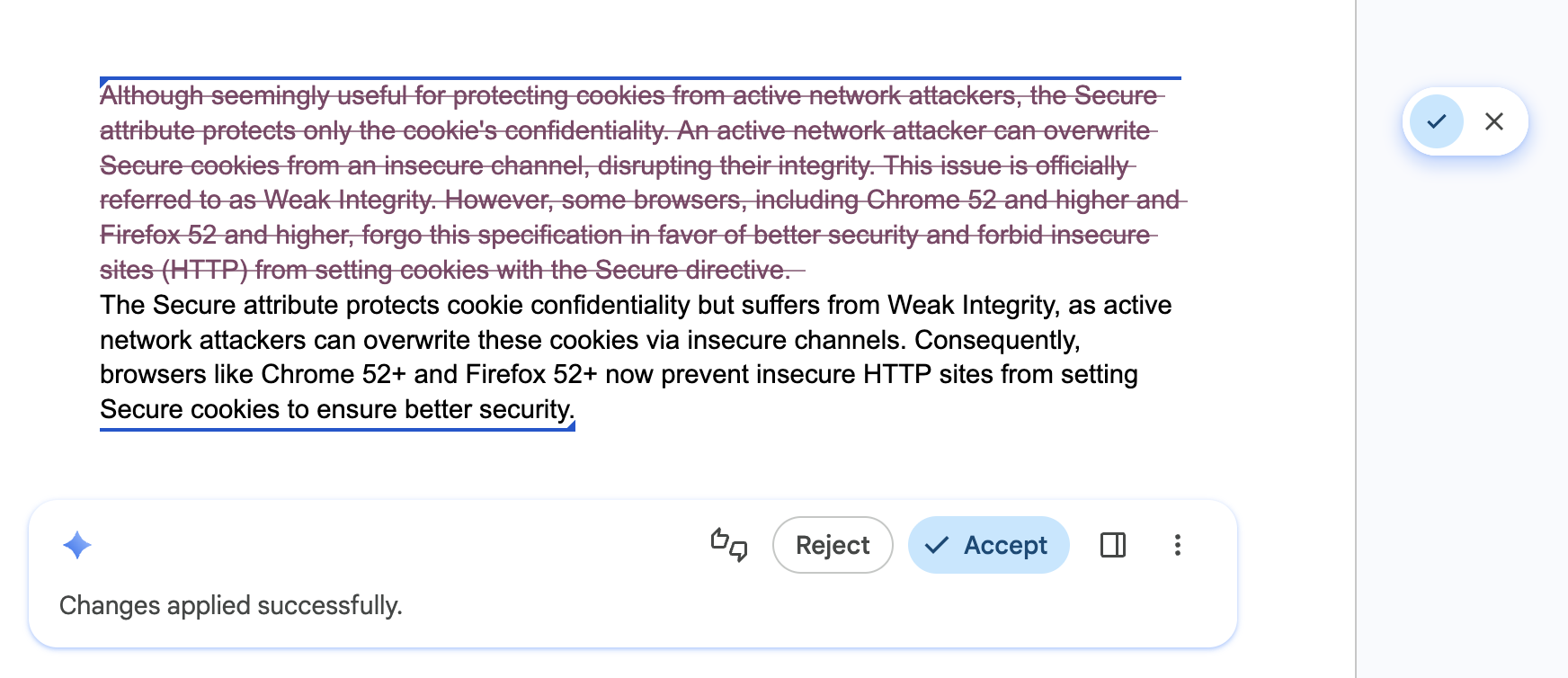
इससे उपयोगकर्ताओं को एआई की मदद से किए गए बदलावों पर तुरंत जाने और उन्हें पहले जैसा करने की अनुमति मिलती है
इन पर लागू होता है: सभी एपीआई.
क्या करें: अपने यूज़र इंटरफ़ेस (यूआई) में स्टेपर या नेविगेशन इतिहास शामिल करें. इससे लोग, भरोसे के साथ अलग-अलग नतीजे देख पाएंगे. साथ ही, वे एआई से किए गए बदलावों को तुरंत पहले जैसा कर पाएंगे. इससे यह पक्का होता है कि अलग-अलग वर्शन अब भी आसानी से उपलब्ध हैं.
ऐसा न करें: उपयोगकर्ता के पिछले ड्राफ़्ट या एआई के उस जवाब को न बदलें जो उसे पसंद आया हो. साथ ही, उसे वापस जाने, पहले जैसा करने या वर्शन की तुलना करने का विकल्प न दें.
उपयोगकर्ता को कंट्रोल करने और सेटिंग बदलने की सुविधा देना
इन पर लागू होता है: सभी एपीआई.
यह काम करें: जनरेट किए गए सभी कॉन्टेंट का फ़ाइनल एडिटर उपयोगकर्ता को बनाएं. उपयोगकर्ता को आसानी से समझ में आने वाले ओवरराइड उपलब्ध कराएं, ताकि वह फ़ाइनल आउटपुट का पूरा मालिकाना हक बनाए रख सके. एपीआई से गलत नतीजे मिल सकते हैं.
ऐसा न करें: एआई से जनरेट किए गए जवाब को ही एकमात्र विकल्प के तौर पर न दिखाएं.
बार-बार होने वाले टास्क के लिए, कैश मेमोरी में सेव किए गए नतीजे
इन पर लागू होता है: सभी एपीआई.
यह करें: बार-बार किए जाने वाले इनपुट या क्वेरी के लिए, स्थानीय नतीजों की कैश मेमोरी लागू करें. उदाहरण के लिए, sessionStorage या IndexedDB का इस्तेमाल करके. कैश मेमोरी के हिट को बढ़ाने के लिए, इनपुट को सामान्य बनाएं. इसके लिए, सफ़ेद जगह को ट्रिम करें और छोटे अक्षरों का इस्तेमाल करें. ज़्यादा इनपुट के लिए, जैसे कि इमेज, कैश मेमोरी की कुंजी के तौर पर इस्तेमाल करने के लिए हैश जनरेट करें. अपनी कैश मेमोरी के लिए, टाइम टू लिव (टीटीएल) की वैल्यू कम रखें. इसके अलावा, कैश मेमोरी में सेव किए गए नतीजों को अपडेट करते समय, उन्हें बैकग्राउंड में दिखाया जा सकता है. अगर नतीजे से उपयोगकर्ता संतुष्ट नहीं है, तो उसे नया अनुमान लगाने की सुविधा दें.
ऐसा न करें: एक ही खोज क्वेरी या एक जैसे डेटा इनपुट के लिए, एक ही अनुमान को बार-बार न चलाएं. ऐसा तब किया जाता है, जब बदलाव करना ज़रूरी नहीं होता. उदाहरण के लिए, जब कोई उपयोगकर्ता खोज के नतीजों के बीच आगे-पीछे नेविगेट करता है. इससे रिस्पॉन्सिवनेस और लोकल कंप्यूट का बेहतर इस्तेमाल होता है.
// ✅ DO: Check a local cache before running inference
async function getAiResponse(userInput, forceRefresh = false) {
// Normalize the query to increase cache hits
const query = userInput.trim().toLowerCase();
const cacheKey = `ai_results_${query}`;
const TTL_MS = 3600000; // 1 hour conservative TTL
if (!forceRefresh) {
const itemStr = localStorage.getItem(cacheKey);
if (itemStr) {
const item = JSON.parse(itemStr);
const now = Date.now();
// Check if the item has expired
if (now < item.expiry) {
// Lightweight safety check before rendering
if (isValid(item.value)) return item.value;
} else {
// Delete the stale entry if the TTL has passed
localStorage.removeItem(cacheKey);
}
}
}
// Fallback: Run inference if no valid cache exists
const session = await LanguageModel.create();
const response = await session.prompt(userInput);
// Store the result for future use (with an expiration)
const cacheData = {
value: response,
expiry: Date.now() + TTL_MS
};
localStorage.setItem(cacheKey, JSON.stringify(cacheData));
return response;
}