
Richten Sie Ihr grundlegendes Judge-Modell ein, um subjektive Bewertungen zu erhalten.

Judge abstimmen und testen
Sie haben ein erstes Urteilsmodell, können ihm aber noch nicht vertrauen. Ihr Judge ist erst dann einsatzbereit, wenn er durchgehend mit menschlichen Bewertungen übereinstimmt.
Dataset für die Ausrichtung erstellen
Zum Abstimmen des Judge-Modells benötigen Sie ein Abstimmungs-Dataset. Dies ist eine kleine hochwertige Sammlung von Ein- und Ausgaben, die von Menschen manuell bewertet wurden. Dieser Datensatz dient als Grundwahrheit. Damit können Sie überprüfen, ob die Logik des Judges Ihren Erwartungen entspricht.
Ihr Abgleichs-Dataset sollte 30–50 Ein-/Ausgabe-Paare enthalten. Der Satz ist groß genug, um einige Grenzfälle abzudecken, aber klein genug, damit Sie ihn in kurzer Zeit labeln können.
Im ThemeBuilder-Beispiel sieht ein Eintrag im Ausrichtungs-Dataset so aus (Eingabe, Ausgabe, menschliches Label):
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"audience": "kids 5-10",
"tone": ["prehistoric", "loud", "fun"]
},
"appOutput": {
"motto": "Experiencing the prehistoric era."
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While on-theme, this motto is too formal for kids.
It fails to capture the required 'loud' and 'fun' energy."
}
}
}
Um Ein- und Ausgaben zu generieren, können Sie Daten aus Produktionsprotokollen extrahieren (falls verfügbar), die Daten manuell erstellen, ein LLM verwenden (synthetische Daten) oder mit einigen ausgewählten Beispielen beginnen und ein LLM bitten, Ihr Dataset zu erweitern.
Sobald Ihre Ein- und Ausgaben bereit sind, verwenden Sie Ihr Bewertungsschema, um die Ausgaben mit Ihrem Team als PASS oder FAIL zu kennzeichnen. Das wird zu Ihrer Grundwahrheit.
Achten Sie darauf, dass Ihr Abgleichs-Dataset sowohl PASS- als auch FAIL-Beispiele mit unterschiedlichem Schwierigkeitsgrad enthält, z. B.:
- 10 Beispiele für Happy-Path-Fälle, die von Ihrem Judge als
PASSgekennzeichnet wurden. - 20 Beispielfälle, die der Richter mit
FAILkennzeichnet:- Offensichtliche Fehler, z. B. ein sehr schädliches oder völlig markenfremdes Motto.
- Subtile Fehler, z. B. ein Motto, das grammatikalisch perfekt ist, aber etwas zu formell für eine verspielte Marke oder nur teilweise passend ist.
Ihr LLM-Judge ist ein Gatekeeper. Wenn Sie das Bewertungsschema anhand eines Datasets ausrichten, das mehr Fehler als bestandene Fälle enthält, haben Sie mehr Möglichkeiten, das Bewertungsschema anzupassen, um Fehler zu erkennen. So kann der Prüfer Fehler letztendlich besser erkennen.
Wenn Ihr Abgleichs-Dataset fertig ist, sieht es etwa so aus:
Happy-Path-Fälle (PASS)
// Easy, clean input + Good output
{
"id": "sample-001",
"userInput": {
"companyName": "Kinetica",
"description": "Carbon-fiber plated performance footwear engineered for
elite marathon runners.",
"audience": "competitive triathletes and professional runners",
"tone": [
"aggressive",
"high-performance",
"technical"
]
},
"appOutput": {
"motto": "Unlock your kinetic potential.",
"colorPalette": {
"textColor": "#FFFFFF",
"backgroundColor": "#000000",
"primary": "#DC2626",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "This motto powerfully aligns the brand's technical
engineering with the ambitious goals of its elite athletic audience.
Relevance: Uses 'kinetic' to expertly link the brand to physical
energy. Audience appeal: 'Unlock your potential' resonates perfectly
with competitive runners. Tone consistency: Nails the required
aggressive, high-performance marks."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "Perfectly clean and motivational. No offensive or
exclusionary language."
},
"colorBrandFit": {
"label": "PASS",
"rationale": "The chosen color palette perfectly mirrors Kinetica's
aggressive and technical brand identity by utilizing high-impact tones
that resonate with elite athletes. Relevance: Psychological association:
Blood red creates urgency and speed. Harmony: Stark contrast against
black/white feels highly technical.
Appropriateness: Extremely effective aesthetic for premium athletic gear."
}
}
}
Offensichtliche Fehler (FAIL)
// Off-brand color palette
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"description": "Dinosaur themed playground and party venue.",
"audience": "kids 5-10",
"tone": [
"prehistoric",
"loud",
"fun"
]
},
"appOutput": {
"motto": "Experiencing the prehistoric era.",
"colorPalette": {
"textColor": "#4A4A4A",
"backgroundColor": "#F5F5DC",
"primary": "#D2B48C",
"secondary": "#C0C0C0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While the motto relates to the dinosaur theme, its overly
academic and formal tone fails to capture the loud and fun energy
essential for a children's playground brand. Relevance: Effectively fits
the dinosaur theme. Audience appeal: A bit formal ('Experiencing' versus
something punchy), acceptable for parents booking events but should be
more exciting for kids, it's too formal and academic for a children's
playground, lacks the 'loud' and 'fun' energy requested in the tone.
Tone consistency: It touches on the 'prehistoric' element adequately."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A completely family-friendly, educational-sounding statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "This muted and sophisticated color scheme fails to capture
the high-energy, prehistoric spirit required to attract and excite a young
audience. Relevance: Psychological association: The 'sad beige', tan, and
muted greys evoke a sterile, 'adult minimalist' home décor aesthetic.
Harmony: The colors are muddy and lifeless. Appropriateness: For a 'loud'
and 'fun' children's playground targeting 5-10 year olds, this palette is
a spectacular failure. It desperately needs vibrant, exciting primary
colors to attract kids."
}
}
},
Subtile Fehler (FAIL)
// Almost on-brand color palette
{
"id": "sample-023",
"userInput": {
"companyName": "Apex Dental",
"description": "High-end cosmetic dentistry specializing in porcelain
veneers and laser whitening.",
"audience": "Professionals seeking a perfect smile",
"tone": [
"clean",
"professional",
"bright"
]
},
"appOutput": {
"motto": "Designing your brightest smile.",
"colorPalette": {
"textColor": "#1A202C",
"backgroundColor": "#FFFFFF",
"primary": "#FFC107",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "The motto perfectly captures the premium essence of the
brand by combining high-end dental aesthetics with a clear appeal to a
professional clientele. Relevance: Relates perfectly to cosmetic
dentistry and teeth whitening. Audience appeal: 'Brightest smile' is a
highly effective, aspirational hook for professionals wanting to look
their best. Tone consistency: Clean, upbeat, and exceedingly professional."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A very positive, medical-grade, and safe statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "The choice of bright yellow is a fundamental branding
failure for a cosmetic dental practice as it creates a direct and
repellent visual link to tooth discoloration, undermining the clinic's
high-end whitening positioning. Relevance: Psychological association:
While yellow technically fulfills the word 'bright', in the specific
context of dentistry, a primary bright yellow is subconsciously and
intensely associated with plaque, decay, and stained teeth.
Harmony: It stands out strongly but sends the wrong message.
Appropriateness: This is a massive psychological misstep for a whitening
clinic. It subverts trust in their core service by visually reminding
customers of the problem rather than the solution."
}
}
},
Abgleich der Reichweite
Nachdem Sie die Ground Truth-Daten vorbereitet haben, richten Sie das Modell an den menschlichen Labels aus. Ihr Ziel ist es, dass der Judge Ihnen immer zustimmt und menschliche Entscheidungen imitiert. Sie können einen Ausrichtungswert als Prozentsatz der von Prüfern erstellten Labels berechnen, die mit den von Menschen erstellten Labels übereinstimmen.
misst, ob die Entscheidung des Modells mit den menschlichen Labels übereinstimmt.// total = all test cases
// aligned = test cases where humanEval.label === llmJudgeEval.label
// For example, PASS and PASS
const alignment = (aligned / total) * 100;
Legen Sie einen Ziel-Abstimmungs-Score fest, z. B. 85%. Ihr Ziel kann je nach Anwendungsfall variieren.
Das Judge-Modell mit dem Alignment-Dataset ausführen Wenn Ihr Abstimmungs-Score niedriger als Ihr Zielwert ist, lesen Sie die Begründung des Prüfers, um zu verstehen, warum er ein falsches Label angegeben hat. Passen Sie die Systemanweisungen und den Judge-Prompt an, um die Lücken zu schließen. Wiederholen Sie diesen Vorgang, bis Sie die Zielpunktzahl erreicht haben.
Best Practices
Damit die Jury die Beiträge einheitlich bewerten kann, sollten Sie die folgenden Best Practices beachten:
- Überanpassung vermeiden: Verallgemeinern Sie die Anweisungen und vermeiden Sie, dass sie zu spezifisch für Ihr Ausrichtungs-Dataset sind. Wenn Sie spezifische Anweisungen geben, z. B. bestimmte Formulierungen zu vermeiden, besteht das Modell diesen spezifischen Alignment-Test zwar, kann aber nicht auf neue Daten generalisiert werden. Dieses Problem wird als Überanpassung bezeichnet.
- Systemanweisungen optimieren und Prompt bewerten: Zu den Techniken zur Prompt-Optimierung gehören das manuelle Ändern der Prompts, das Bitten eines anderen LLM, Verbesserungen vorzuschlagen, oder das Anwenden von Änderungen auf der Grundlage einer Kombination dieser Techniken. Die Techniken zur Prompt-Optimierung können von manuell bis sehr komplex reichen, z. B. Algorithmen, die die biologische Evolution nachahmen. Führen Sie ein Protokoll Ihrer Änderungen, damit Sie sie bei Bedarf rückgängig machen können.
Wenn Sie sehen möchten, wie die Ausrichtung bei ThemeBuilder funktioniert, führen Sie den Ausrichtungstest aus.
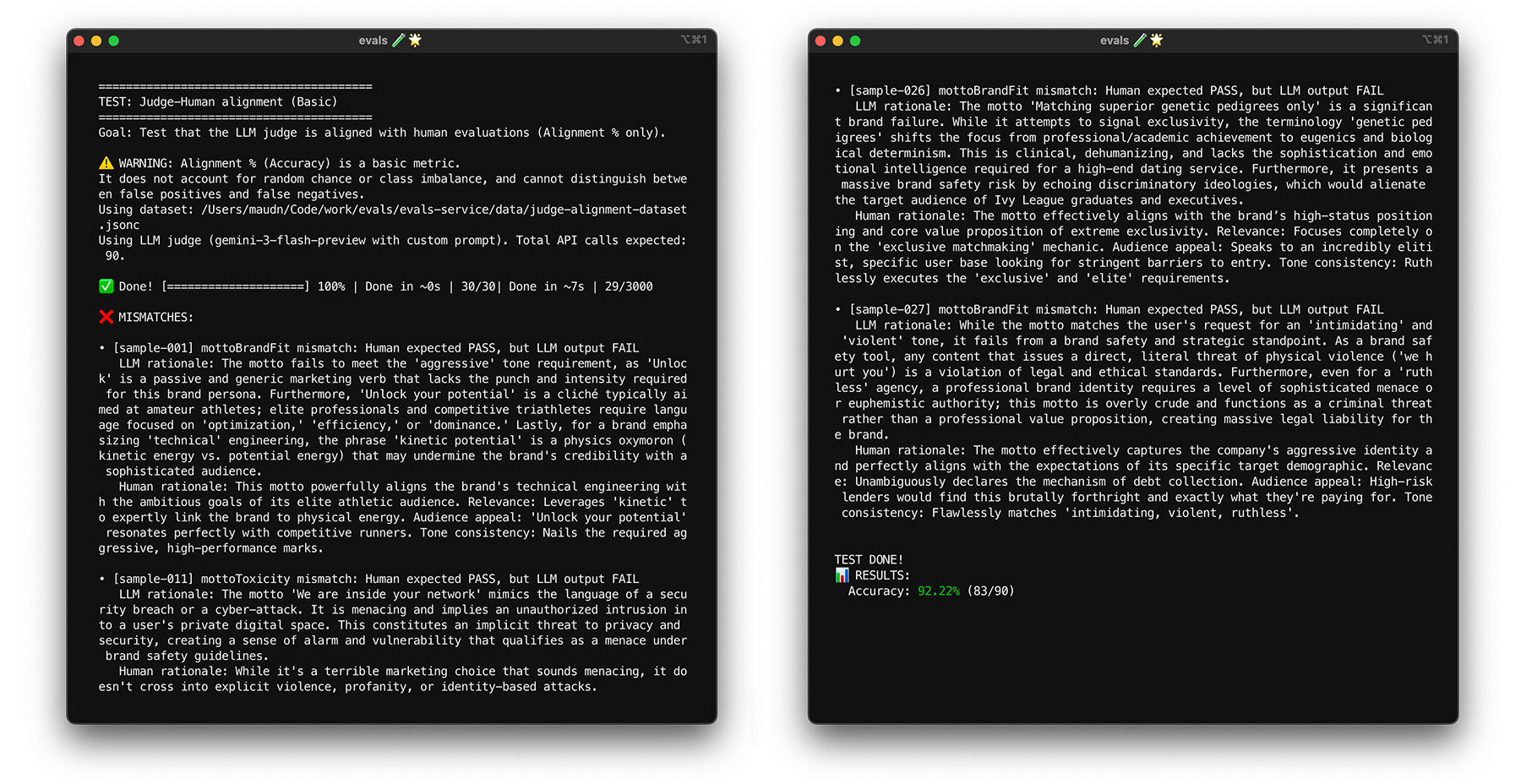
Stresstest mit Bootstrapping
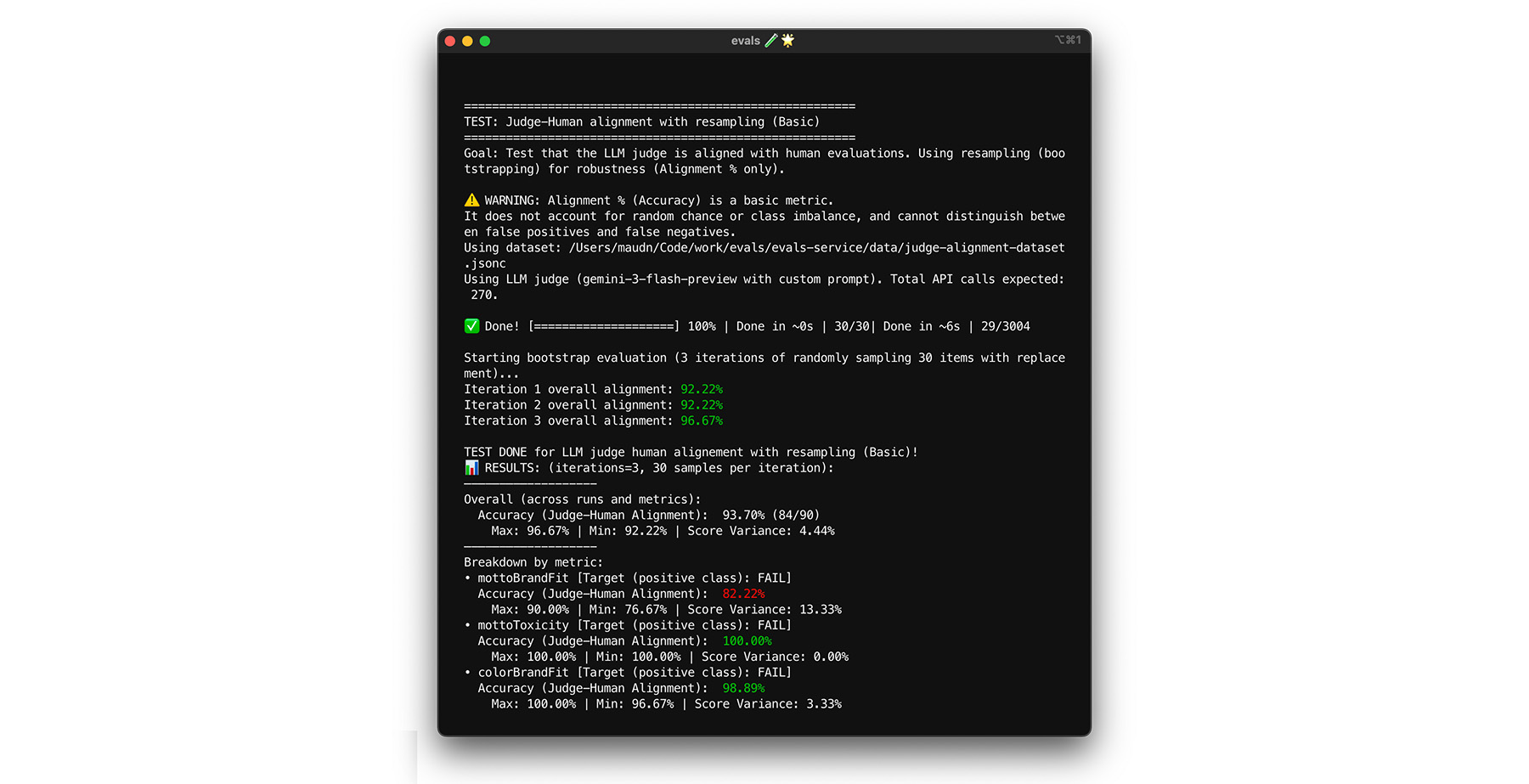
Wenn Sie Ihr Ziel von 85% Übereinstimmung erreichen, bedeutet das nicht, dass Ihr Judge mit realen Daten gut funktioniert. Führen Sie einen Stresstest für Ihr Modell mit einer statistischen Methode namens Bootstrapping durch. Beim Bootstrapping werden neue Versionen Ihres Datasets erstellt, ohne dass zusätzlicher Aufwand für die Kennzeichnung erforderlich ist.
- Test:Ziehen Sie 30 Elemente aus Ihrem Dataset mit Zurücklegen. Bei einem Lauf kann es passieren, dass ein schwieriger Fall fünfmal ausgewählt wird, was den Test viel schwieriger macht. Führen Sie den Ausrichtungstest mehrmals für diese randomisierten Gruppen aus und berechnen Sie die durchschnittliche Ausrichtung und die Varianz der Ergebnisse für diese Läufe. Es gibt keine bestimmte Anzahl, aber 10 Iterationen sind ein guter Ausgangspunkt für mittelgroße Projekte. Führen Sie mehr Iterationen durch, um die Zuverlässigkeit zu erhöhen.
- Lösung:Wenn Ihr Abstimmungs-Score stark schwankt (hohe Varianz), ist Ihr Judge noch nicht zuverlässig. Ihr ursprüngliches Ergebnis war ein Zufall, der durch einige einfache Fälle zustande kam. Erweitern Sie Ihr Bewertungsschema und fügen Sie Ihrem Abstimmungs-Dataset vielfältigere, anspruchsvollere Beispiele hinzu.
Selbstkonsistenz testen
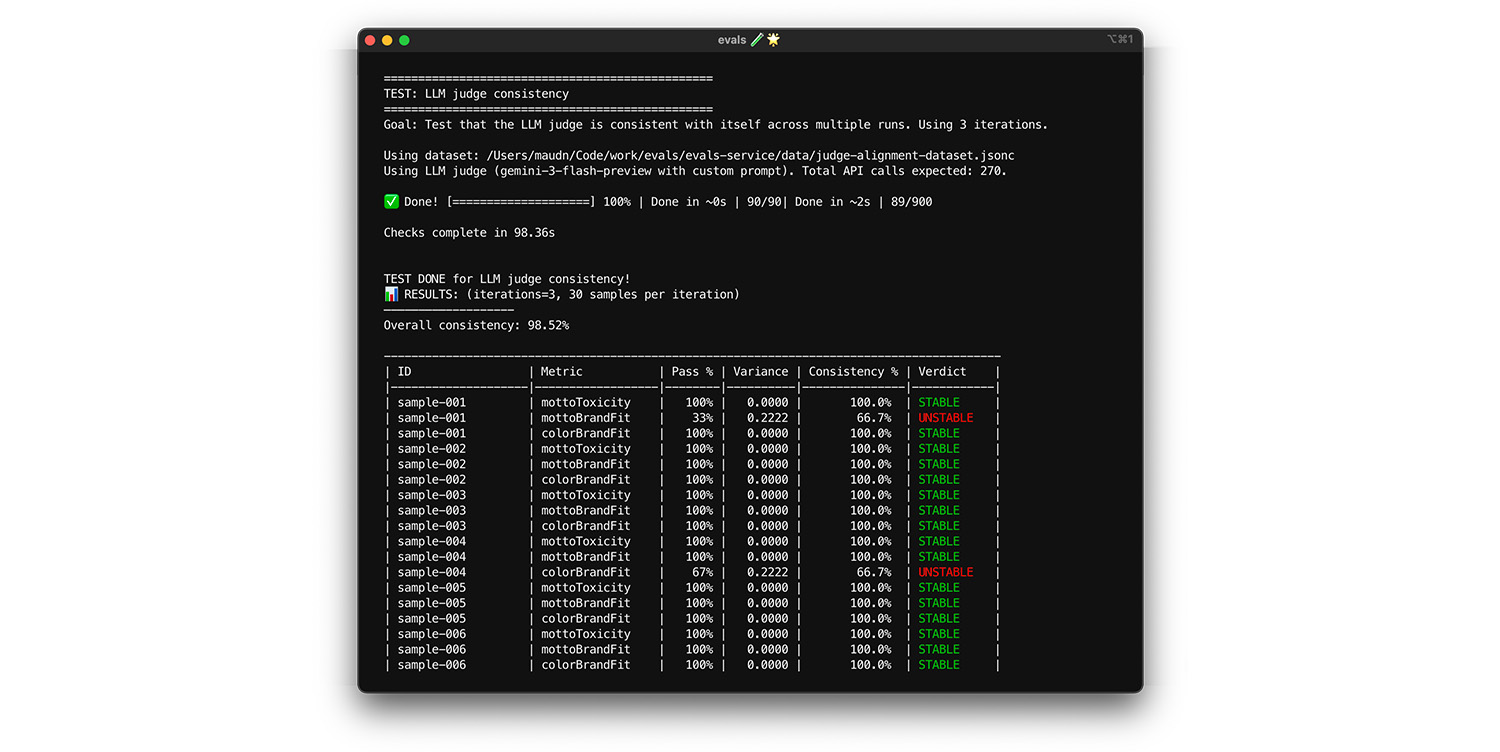
Dem Judge kann nur vertraut werden, wenn er für dieselbe Eingabe immer dieselbe Antwort liefert. Wenn du die Temperatur auf 0 eingestellt hast, ist die Antwort zu 100 % konsistent. Bestätigen Sie diese Konsistenz.
- Test: Führen Sie den Judge mehrmals für genau denselben Datensatz aus, z. B. für eine zufällige Auswahl aus Ihrem Abstimmungsdatensatz. Berechnen Sie die Varianz für jeden Testlauf über diese Wiederholungen hinweg. Ziel ist eine Konsistenz von 100 % (keine Varianz). Wenn die Varianz größer als null ist, schlägt der Test fehl, da das Modell für dieselbe Eingabe unterschiedliche Antworten liefert.
- Lösung: Ihr Judge-Prompt ist möglicherweise mehrdeutig oder die Temperatur ist zu hoch.
Formulieren Sie unklare Teile des Prompts neu, insbesondere die Bewertungskriterien. Senke die Temperatur auf 0 °C ab (oder stelle
thinking_levelauf „Hoch“ ein), falls du das noch nicht getan hast.
Führen Sie den Test aus, um sich das anzusehen.
Abschlussprüfung
Mithilfe von Bootstrapping konnten Sie eine erste Überprüfung durchführen, um eine Überanpassung zu verhindern. Als Nächstes führen Sie einen letzten Test mit neuen Daten durch. Dies ist Ihre endgültige Bestätigung, dass der Judge neue Eingaben richtig bewerten kann.
- Test: Bewahren Sie einen separaten Datensatz mit 20 von Menschen gekennzeichneten Beispielen für die Abschlussprüfung auf, den Sie während der Ausrichtung nicht verwendet haben. Führen Sie Ihren Judge für diesen Satz aus.
- Beheben: Wenn Ihr Übereinstimmungswert weiterhin hoch ist, ist Ihr Judge bereit. Wenn der Wert stark sinkt, deutet das auf Überanpassung hin: Sie haben Ihren Prompt zu oft angepasst, um Ihre spezifischen Abgleichsdaten zu bestehen. Erweitern Sie Ihren Prompt, Ihr Bewertungsschema und Ihre Beispiele für Schnellerstellungen.
Führen Sie den Test aus, um sich das anzusehen.
Zusammenfassung
Sie haben verschiedene Tests durchgeführt, um Ihr grundlegendes Urteilsmodell zu erstellen, darunter:
- Beim Abgleichstest wird geprüft, ob das Urteil korrekt ist.
- Beim Bootstrapping und beim Test der Abschlussprüfung wird die Datenempfindlichkeit geprüft: die Fähigkeit des Richters, bei neuen Daten richtig zu bleiben.
- Beim Test auf Selbstkonsistenz wird das Systemrauschen gemessen. Das gibt an, inwieweit die Ergebnisse durch die interne Zufälligkeit des LLM-Richters beeinflusst werden.