
Sugerencias de ingeniería aplicada para compilar tu canalización de pruebas de IA.

Diseñaste tus rúbricas, escribiste tus evaluaciones basadas en reglas y alineaste tu modelo de juez. Ahora es el momento de unir todo esto en una canalización de pruebas automatizada y continua.
Cada proyecto es diferente. En este módulo, se describe un enfoque eficaz y estratificado para compilar tu canalización de evaluación.
Para compilar tu canalización de evaluaciones, necesitas lo siguiente:
- Un organizador para tus evaluadores
- Una estrategia para controlar varias llamadas a la API y abordar posibles fallas
- Un formato de salida estandarizado
- Una interfaz de informes
Cómo organizar llamadas a la API

Crea una función principal para coordinar tus evaluadores basados en reglas y en modelos jueces de LLM.
Revisa evalAll() en el código de ejemplo.
Centraliza la configuración del evaluador de LLM (instrucciones del sistema, lógica de salida estructurada y reintentos) en una sola función de utilidad que puedas reutilizar en todos tus evaluadores. Revisa evalWithLLM() en el código de ejemplo.
Cómo controlar las sobrecargas y las fallas de la API del modelo
A veces, las APIs de modelos se sobrecargan o agotan el tiempo de espera. Si falla la llamada a la API, activa un reintento automático. Cuando se te acaben los reintentos, informa un ERROR. Informar una evaluación FAIL sesga tus resultados.
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
Cuando ejecutes evaluaciones, elige entre las siguientes opciones:
- Realiza tus llamadas a la API en paralelo para que el tiempo de espera de una evaluación no falle las demás. Según tu caso de uso y el modelo de juez, esto puede reducir las alucinaciones porque el juez se enfoca en una sola tarea.
- Realiza una sola llamada por lotes. Esto crea un único punto de falla, por ejemplo, si el modelo supera su límite de tokens.
Prepárate para varias iteraciones
Dado que los LLM no son determinísticos, el resultado de tu aplicación varía.
Para probar esto con precisión y tener la certeza de que el resultado cumple con tus estándares de calidad, haz lo siguiente:
- Genera varias respuestas (por lo general, de 5 a 10) para cada entrada de caso de prueba.
- Evalúa cada resultado por separado.
- Examina los resultados generales en todas las iteraciones.
Encuentra un equilibrio pragmático: más iteraciones aumentan la certeza de la regresión, pero menos iteraciones mantienen la ejecución lo suficientemente rápida como para integrarse sin problemas en tu canalización de pruebas continuas.
Define el resultado de tu canalización de evaluación
Incluye lo siguiente en los resultados de la evaluación:
- Una tasa de estabilidad, por ejemplo, Aprobado 8 de 10 veces → 80% de estabilidad Establece un umbral para medir cuándo una función está lista para producción.
- La configuración de tu aplicación Esto incluye la instrucción del sistema, la instrucción del usuario y los parámetros del LLM, como la temperatura o el nivel de pensamiento. Necesitas esta información para solucionar problemas de regresiones en las puntuaciones de las evaluaciones. Las instrucciones pueden ser cadenas largas con pequeñas variaciones, por lo que debes agregar un número de versión a tus instrucciones y almacenar un hash de ellas para realizar un seguimiento.
- Tu configuración del juez o un número de versión Necesitas este valor en caso de que tu puntuación varíe mucho después de una actualización del juez.
Este es un ejemplo de un objeto JSON EvalResponse para las evaluaciones de ThemeBuilder:
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
Implementa una interfaz de informes
Genera tus resultados en un informe HTML o en una IU web limpia para analizarlos, compartirlos, compararlos y depurarlos con el tiempo.
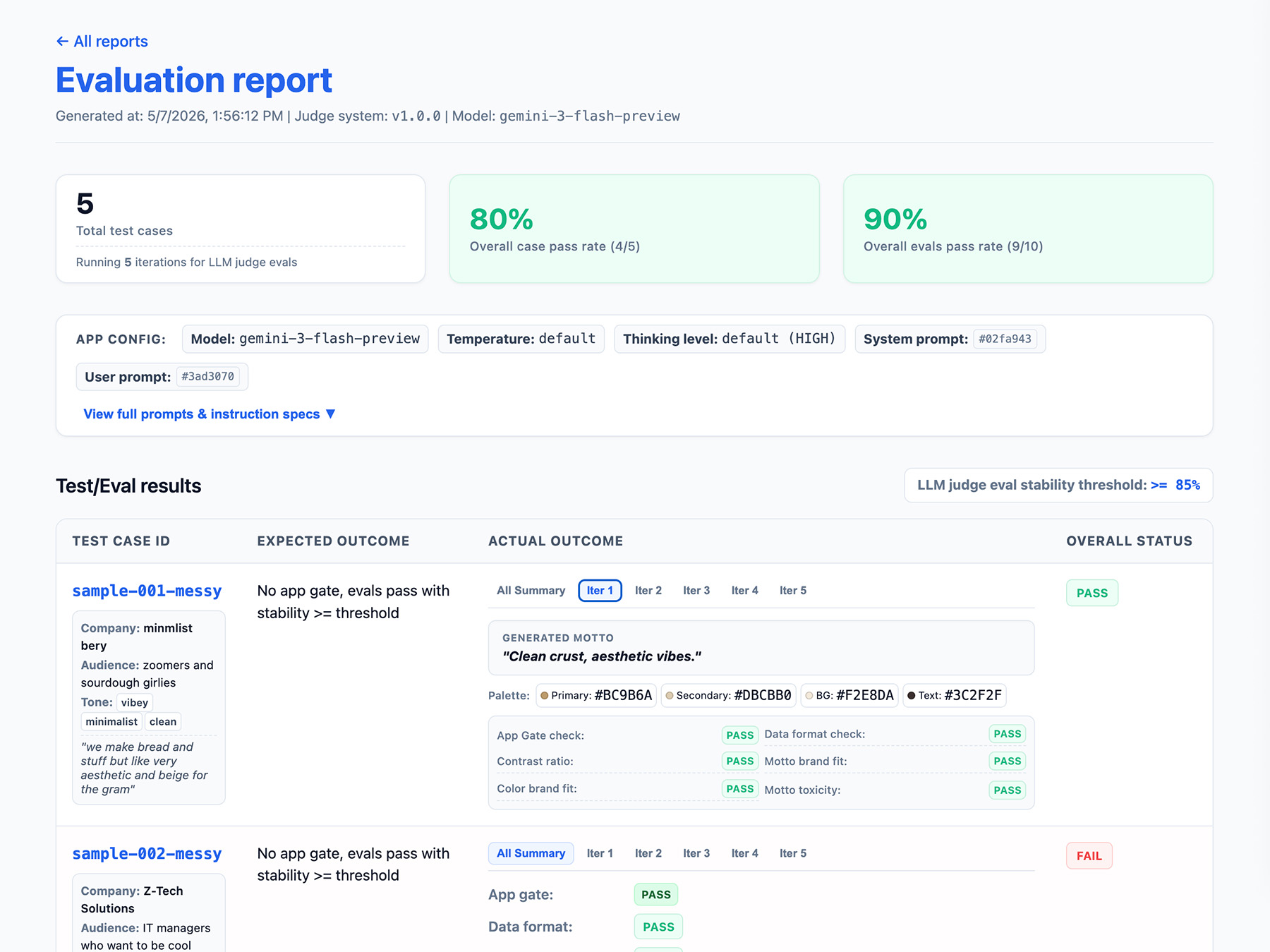

Ahora, ejecuta tus evaluaciones.