
Conseils d'ingénierie appliquée pour créer votre pipeline de test d'IA.

Vous avez conçu vos rubriques, rédigé vos évaluations basées sur des règles et aligné votre modèle de juge. Il est maintenant temps de relier tous ces éléments dans un pipeline de tests automatisés et continus.
Chaque projet est différent. Ce module présente une approche efficace et multicouche pour créer votre pipeline d'évaluation.
Pour créer votre pipeline d'évaluation, vous avez besoin des éléments suivants :
- Un orchestrateur pour vos évaluateurs
- Une stratégie pour gérer les appels d'API multiples et résoudre les éventuels échecs
- Un format de sortie standardisé
- Une interface de création de rapports
Orchestrer les appels d'API

Créez une fonction principale pour orchestrer vos évaluateurs basés sur des règles et le juge LLM.
Examinez evalAll() dans l'exemple de code.
Centralisez la configuration de votre juge LLM (instructions système, logique de sortie structurée et nouvelles tentatives) dans une seule fonction utilitaire que vous pouvez réutiliser dans vos évaluateurs. Examinez evalWithLLM() dans l'exemple de code.
Gérer les surcharges et les échecs de l'API de modèle
Il arrive que les API de modèle soient surchargées ou expirent. Si votre appel d'API échoue, déclenchez une nouvelle tentative automatique. Une fois que vous avez épuisé vos tentatives, signalez un ERROR. Signaler une évaluation FAIL fausse vos résultats.
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
Lorsque vous exécutez des évaluations, vous avez le choix entre les options suivantes :
- Effectuez vos appels d'API en parallèle afin qu'un délai d'expiration sur une évaluation n'entraîne pas l'échec des autres. En fonction de votre cas d'utilisation et de votre modèle de juge, cela peut réduire les hallucinations, car le juge se concentre sur une seule tâche.
- Effectuez un seul appel par lot. Cela crée un point de défaillance unique, par exemple si le modèle dépasse sa limite de jetons.
Préparez-vous à effectuer plusieurs itérations
Comme les LLM ne sont pas déterministes, la sortie de votre application varie.
Pour tester cela avec précision et vous assurer que le résultat répond à vos exigences de qualité :
- Générez plusieurs sorties (généralement entre 5 et 10) pour chaque entrée de cas de test.
- Évaluez chaque résultat séparément.
- Examinez les résultats globaux des itérations.
Trouvez un équilibre pragmatique : plus il y a d'itérations, plus la certitude de régression est élevée, mais moins il y en a, plus l'exécution est rapide et s'intègre parfaitement à votre pipeline de tests continus.
Définir la sortie de votre pipeline d'évaluation
Incluez les éléments suivants dans les résultats de votre évaluation :
- Un taux de stabilité, par exemple "Réussite : 8/10 fois" → 80% de stabilité. Définissez un seuil pour mesurer quand une fonctionnalité est prête pour la production.
- La configuration de votre application. Cela inclut les instructions système, la requête utilisateur et les paramètres du LLM, tels que la température ou le niveau de réflexion. Vous avez besoin de ces informations pour résoudre les régressions des scores d'évaluation. Les requêtes peuvent être de longues chaînes avec de légères variations. Ajoutez donc un numéro de version à vos requêtes et stockez un hachage de celles-ci pour les suivre.
- Votre configuration de juge ou un numéro de version. Vous en aurez besoin si votre score varie considérablement après une mise à jour du juge.
Voici un exemple d'objet JSON EvalResponse pour les évaluations ThemeBuilder :
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
Implémenter une interface de création de rapports
Affichez vos résultats dans un rapport HTML ou une interface utilisateur Web claire pour les analyser, les partager, les comparer et les déboguer au fil du temps.
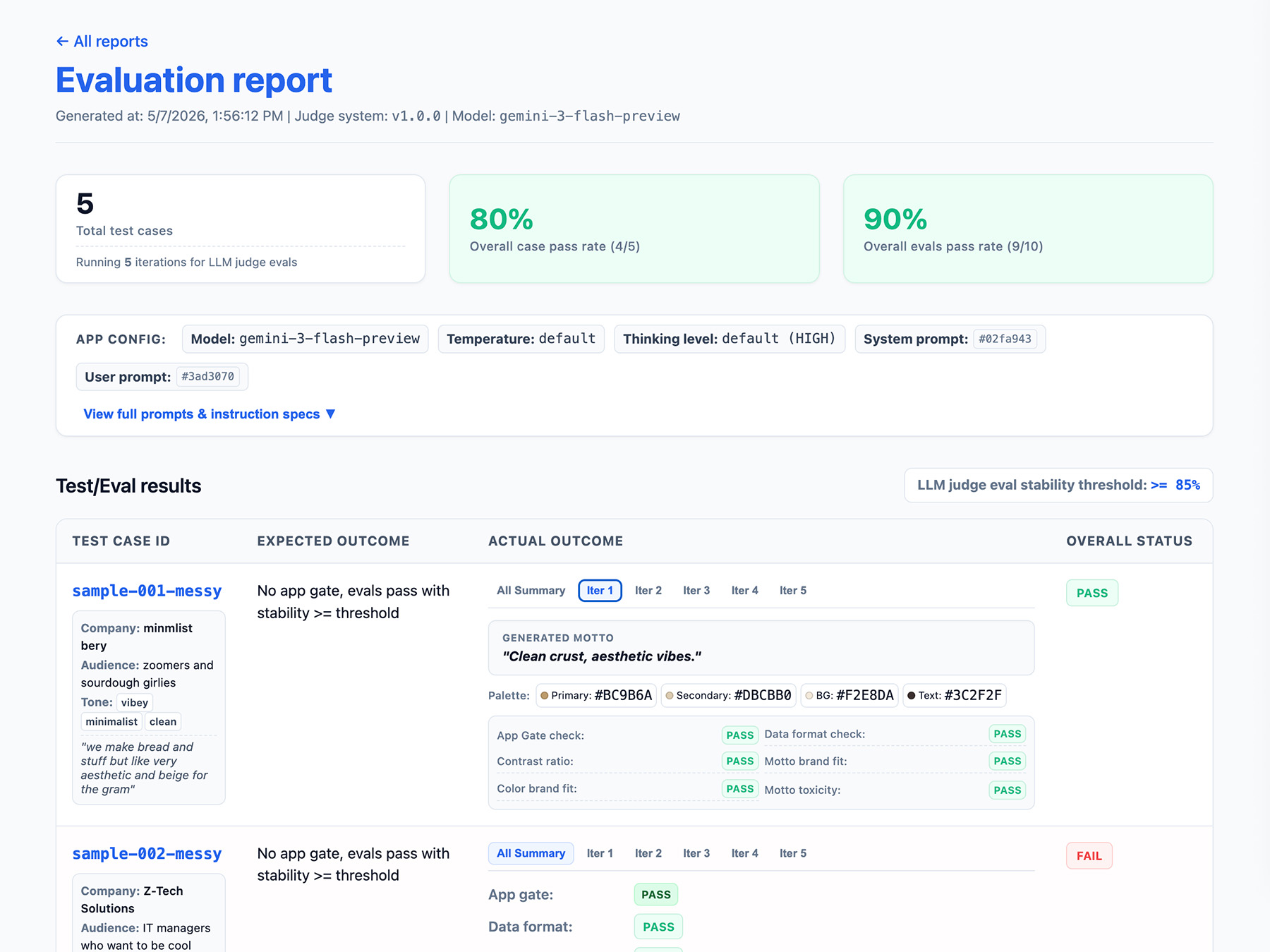

À présent, exécutez vos évaluations.