

Publié le 30 avril 2026
Grâce à l'IA intégrée, votre site Web ou votre application Web peut effectuer des tâches basées sur l'IA sans avoir à déployer, gérer ni auto-héberger des modèles. Il peut être difficile de passer d'une démonstration à une fonctionnalité prête pour la production. Ce document aborde les considérations techniques et d'expérience utilisateur pour vous aider à éviter les pièges courants.
Préparer le modèle à un moment raisonnable
S'applique à : toutes les API, par exemple Summarizer, Translator et Writer.
À faire : initialisez la session dès que vous avez clairement établi l'intention de l'utilisateur d'utiliser la fonctionnalité d'IA, par exemple lorsqu'il accède à une surface d'outils d'IA pertinente, pointe sur un espace de travail d'IA ou interagit avec l'UI environnante de la fonctionnalité. Le préchauffage de la session permet au modèle de se charger en mémoire en arrière-plan pendant que l'utilisateur configure sa tâche, ce qui élimine la latence de démarrage à froid évitable. Essayez d'avoir une longueur d'avance en démarrant la tâche d'IA suivante la plus probable dès que vous commencez à afficher le résultat actuel, par exemple si la fonctionnalité est conçue pour une utilisation itérative.
À éviter : sauf si cela est nécessaire, n'attendez pas que l'utilisateur clique sur "Générer" pour initialiser la session. Cela entraîne un délai de démarrage à froid, car le modèle doit d'abord se charger en mémoire et préparer son pipeline d'exécution.
Définir des prompts initiaux lors de la création
S'applique à : l'API Prompt.
À faire : fournissez des instructions système lors de l'initialisation de la session pour améliorer la vitesse du premier prompt.
À éviter : ne commencez pas par une session vide et n'envoyez pas d'instructions système dans le cadre de
le premier appel prompt(). Cela augmente la latence, car cela oblige le modèle à traiter ces instructions au dernier moment.
// ✅ DO: Create the session as early as possible (tip on warming up the model early) and use initialPrompts for system instructions in the create call
const session = await LanguageModel.create({
initialPrompts: [
{ role: 'system', content: 'You are a helpful assistant specialized in code reviews.' }
]
});
// A few moments later, when the user triggers the AI feature
const review = await session.prompt(`Review the following code:\n\n${code}`);
// ❌ DON'T: Send instructions using prompt() after creation
// const slowerSession = await LanguageModel.create();
// await slowerSession.prompt(`You are a helpful assistant specialized in code reviews.\n\nReview the following code:\n\n${code}`); // Higher latency
Cloner des sessions pour les tâches répétitives
S'applique à : l'API Prompt.
Pour l'API Prompt, chaque session suit le contexte de la conversation, en tenant compte de toutes les interactions précédentes. Étant donné qu'un clone hérite de tout de sa session parente, y compris des prompts initiaux et de l'historique de toutes les interactions jusqu'au point de clonage, structurez votre utilisation pour n'hériter que de ce dont vous avez besoin.
À faire :
- Créer une session de base : pour gérer efficacement les tâches non liées, créez une session de base qui ne contient que vos instructions système et aucun contexte de conversation précédent.
- Cloner la référence : utilisez
clone()sur cette session de base pour les nouvelles tâches afin d'éviter la surcharge liée à l'analyse des instructions système. Cela vous permet de créer des conversations parallèles ou de réinitialiser une tâche à sa référence.
À éviter :
- N'utilisez pas la même session pour des tâches non liées et évitez de cloner une session qui contient déjà un historique d'interactions inutiles. Les deux modèles peuvent entraîner l'interférence d'un contexte précédent non lié avec votre tâche actuelle.
- N'appelez pas
create()de manière répétée avec des instructions système identiques. Utilisez plutôt le modèle de clonage pour optimiser les performances.
// ✅ DO: Create a baseline session and clone it for each new task
const baseSession = await LanguageModel.create({
initialPrompts: [{
role: 'system',
content: 'You are a technical editor...',
}],
});
// Clone the base session once for the first task
const task1 = await baseSession.clone();
const response1 = await task1.prompt("Review this first draft...");
// ... Repeat the cloning pattern for subsequent independent tasks
// Each task starts fresh from the baseline system instructions
// ❌ DON'T:
// Bad performance pattern: repeated create() calls for identical tasks.
// This forces the model to re-parse instructions every time, increasing latency.
// const sessionA = await LanguageModel.create({ initialPrompts: [...] });
// await sessionA.prompt("Task 1...");
// const sessionB = await LanguageModel.create({ initialPrompts: [...] });
// await sessionB.prompt("Task 2...");
// Bad quality pattern: reusing the same session for unrelated tasks.
// const session = await LanguageModel.create();
// await session.prompt("Analyze this financial report...");
// Unrelated task in the same session:
// await session.prompt("Now write a children's story...");
Détruire les sessions inutilisées
S'applique à : toutes les API.
À faire : appelez explicitement destroy() sur
les sessions dont vous n'avez plus besoin pour libérer de la mémoire lorsqu'une fonctionnalité
n'est plus utilisée. Si vous utilisez un modèle de clonage, conservez la session de base et détruisez les clones dont vous n'avez plus besoin.
À éviter : ne laissez pas plusieurs sessions volumineuses actives. Chaque session consomme de la mémoire, ce qui crée une utilisation inutile des ressources et peut devenir un problème. Les sessions seront naturellement nettoyées par le récupérateur de mémoire, mais l'appel de destroy() libère de la mémoire plus rapidement.
// ✅ DO: Use the clone and destroy it immediately after
const clone = await baseSession.clone();
const response = await clone.prompt("Quick task...");
// Free memory right away: destry the clone, keep the baseSession
clone.destroy();
Afficher les réponses de streaming de manière sûre et efficace
S'applique à : toutes les API compatibles avec le streaming (Prompt, Summarizer, Writer, Rewriter et Translator).
À faire : traitez toutes les sorties LLM comme du contenu non fiable. Nettoyez la sortie combinée complète, et pas seulement les blocs, car le code malveillant peut être divisé en plusieurs mises à jour. Avant le rendu, utilisez l'API Sanitizer si elle est compatible. Pour éviter une baisse des performances, utilisez un analyseur Markdown de streaming tel que streaming-markdown.
À éviter : ne définissez pas directement innerHTML sur chaque mise à jour de bloc. Cette opération est lente, en particulier avec une mise en forme complexe comme la coloration syntaxique, et vulnérable à l'injection.
import * as smd from "streaming-markdown";
// Set up virtual buffer and Sanitizer API
const sanitizer = new Sanitizer({
allowElements: ['figure', 'figcaption', 'p', 'br', 'strong', 'em', 'img', 'a'],
allowAttributes: {
'loading': ['img'], 'decoding': ['img'], 'src': ['img'], 'href': ['a']
}
});
// Create an off-screen fragment so the parser doesn't cause flicker
// or trigger XSS in the live DOM during the building process.
const buffer = new DocumentFragment();
const parser = smd.parser_new(buffer);
// Use sanitizer as a gatekeeper / cleaner function so we can combine it with the streaming Markdown parser
function syncSanitized(target, sourceFragment) {
// .sanitize() returns a fresh, clean DocumentFragment
const cleanFragment = sanitizer.sanitize(sourceFragment);
// replaceChildren is the modern high-performance way to swap DOM content
target.replaceChildren(cleanFragment);
}
// Streaming Logic
// `chunks` keeps track of the raw string (useful for logs/debug)
chunks += chunk;
// Let the parser build the DOM incrementally in the buffer.
// This is high-performance because the buffer is not live
smd.parser_write(parser, chunk);
// Use the Sanitizer API to port the content safely to the container.
syncSanitized(container, buffer);
Optimiser l'entrée pour la vitesse
S'applique à : toutes les API.
À faire : ne transmettez au modèle que ce qui est strictement nécessaire. Supprimez tout ce qui n'est pas pertinent pour la tâche à accomplir. Pour les ensembles de données volumineux, fournissez un bref aperçu et une petite sélection d'éléments pertinents.
À éviter : n'envoyez pas de texte brut non traité, de métadonnées inutiles, de balises HTML ni de longues listes non filtrées aux API. La latence augmente considérablement avec la taille de l'entrée, ce qui peut donner l'impression que la fonctionnalité d'IA est défectueuse sur de nombreux appareils.
// ✅ DO: Send only relevant text
const cleanText = document.querySelector('#article').innerText;
const summary = await Summarizer.summarize(cleanText);
// ❌ DON'T: Send the entire DOM structure
// const dirtyText = document.querySelector('#article').innerHTML;
Utiliser une sortie structurée pour des résultats prévisibles
S'applique à : l'API Prompt.
À faire : lorsque vous avez besoin que le modèle renvoie des données dans un format spécifique, utilisez
une sortie structurée
en fournissant un champ responseConstraint pour fournir un schéma JSON. Cela garantit que la sortie est prévisible et vous évite d'avoir besoin d'un post-traitement complexe ou d'une analyse manuelle.
À éviter : ne vous fiez pas uniquement aux instructions en langage naturel (comme "n'afficher que du JSON") seules. Les modèles peuvent inclure des remplissages conversationnels qui interrompent votre analyseur.
// ✅ DO: Use a JSON Schema for predictable results
const schema = {
type: "object",
properties: {
isTopicCats: { type: "boolean" }
}
};
const result = await session.prompt(`Is this post about cats?\n\n${post}`, {
responseConstraint: schema,
});
console.log(JSON.parse(result).isTopicCats);
Dissocier la génération des contraintes de longueur
S'applique à : l'API Prompt, car il s'agit de la seule API compatible avec les schémas de sortie structurée.
À faire : laissez le modèle générer sa réponse naturellement, puis utilisez une logique côté client pour tronquer le texte afin qu'il s'adapte à votre UI.
À éviter : n'appliquez pas de limites strictes de caractères comme maxLength: 125 à l'aide de
schémas de sortie structurée. Lorsque la réponse d'un modèle est plus longue que la limite que vous avez définie, le modèle peut passer à des jetons haute densité tels que des langues étrangères ou des emoji pour compresser le sens, ce qui entraîne une sortie absurde.
/* DO: Handle overflow using CSS */
.result {
overflow: hidden;
white-space: nowrap;
text-overflow: ellipsis; /* Displays '…' */
}
// ❌ DON'T: Force length in the prompt
const result = await session.prompt("Write a bio in exactly 50 characters.");
L'information est clé
S'applique à : toutes les API.
À faire : en fonction de la complexité et de la durée prévue de la tâche, utilisez des animations, des repères visuels et des indicateurs de progression pour informer l'utilisateur. L'approche optimale dépend de votre cas d'utilisation et de la longueur attendue de la sortie de l'API. Voici quelques idées :
- Streaming pour les contenus longs : pour les résumés ou les chats, le streaming crée par défaut un effet de machine à écrire par jeton. Cela peut sembler naturel et fournir un feedback immédiat.
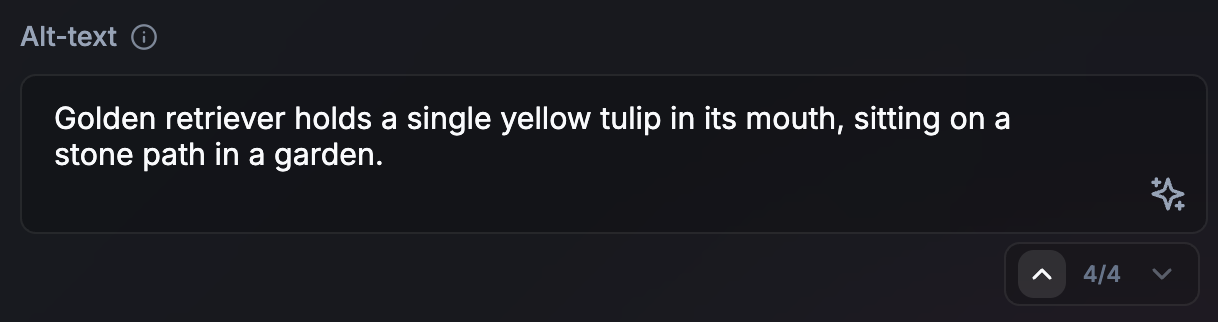
- Non-streaming pour les tâches courtes (ou les tâches asynchrones longues) : pour les sorties courtes, par exemple le texte alternatif, le non-streaming peut créer une UI plus soignée. Il permet également de préparer de manière spéculative la tâche d'IA suivante pendant que la tâche actuelle est en cours de rendu. Cette approche fonctionne également pour les tâches asynchrones ou en arrière-plan plus longues. Si l'utilisateur n'est pas bloqué sur la sortie pour poursuivre son parcours, il n'est pas urgent de produire la sortie au fur et à mesure. Indiquez que le processus est en cours dans l'UI.
- Transitions visuelles pour les mises à jour : lorsque vous traduisez ou réécrivez du texte, utilisez des animations, par exemple la morphose des mots.
À éviter : ne mettez pas à jour l'UI sans repères visuels.
S'aligner sur le modèle mental de l'utilisateur concernant le temps et le travail
S'applique à : toutes les API.
À faire : envisagez un délai artificiel d'une ou deux secondes si une réponse est presque instantanée. Paradoxalement, les utilisateurs peuvent trouver les résultats plus fiables lorsqu'ils perçoivent un processus de génération qui correspond à la difficulté perçue de la tâche. Utilisez des animations pour indiquer qu'un processus d'IA a eu lieu.
À éviter : ne surprenez pas les utilisateurs avec des remplacements d'UI instantanés.
Permettre aux utilisateurs de naviguer rapidement et d'annuler les modifications apportées par l'IA
S'applique à : toutes les API.
À faire : équipez votre UI d'un stepper ou d'un historique de navigation qui permet aux utilisateurs d'explorer différents résultats en toute confiance et de leur permettre d'annuler rapidement les modifications apportées par l'IA. Cela garantit que différentes versions restent facilement disponibles.
À éviter : n'écrasez pas le brouillon précédent de l'utilisateur ni un résultat d'IA qu'il aurait pu apprécier sans moyen de revenir en arrière, de rétablir ou de comparer les versions.
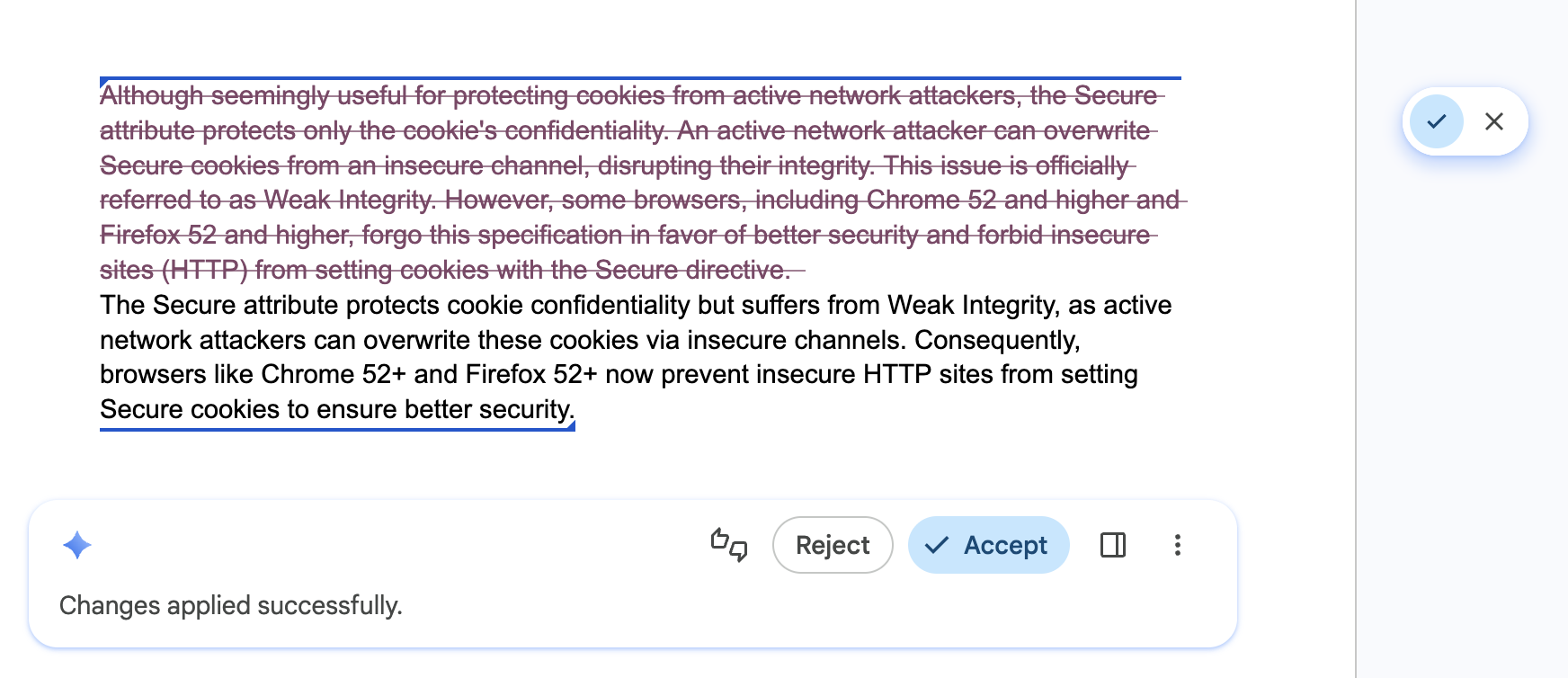
Donner le contrôle aux utilisateurs et leur permettre de remplacer les paramètres
S'applique à : toutes les API.
À faire : faites de l'utilisateur l'éditeur final de tout le contenu généré. Fournissez des remplacements intuitifs afin que l'utilisateur conserve la pleine propriété de la sortie finale. Les API peuvent produire des résultats incorrects.
À éviter : n'imposez pas un résultat généré par l'IA comme seule option.
Mettre en cache les résultats pour les tâches répétées
S'applique à : toutes les API.
À faire : implémentez un cache de résultats local (par exemple, à l'aide de sessionStorage ou IndexedDB) pour les entrées ou requêtes répétées. Normalisez l'entrée en supprimant les espaces et en mettant en minuscules pour augmenter les succès de mise en cache. Pour les entrées volumineuses, par exemple les images, générez un hachage à utiliser comme clé de cache. Définissez une durée de vie (TTL) conservatrice pour votre cache (ou diffusez les résultats mis en cache tout en les mettant à jour en arrière-plan). Laissez l'utilisateur déclencher une nouvelle inférence si le résultat n'est pas satisfaisant.
À éviter : n'exécutez pas la même inférence pour une requête de recherche répétée ou une entrée de données identique lorsque la variabilité n'est pas souhaitable, par exemple lorsqu'un utilisateur navigue entre les résultats de recherche. Cela permet d'optimiser la réactivité et l'utilisation efficace du calcul local.
// ✅ DO: Check a local cache before running inference
async function getAiResponse(userInput, forceRefresh = false) {
// Normalize the query to increase cache hits
const query = userInput.trim().toLowerCase();
const cacheKey = `ai_results_${query}`;
const TTL_MS = 3600000; // 1 hour conservative TTL
if (!forceRefresh) {
const itemStr = localStorage.getItem(cacheKey);
if (itemStr) {
const item = JSON.parse(itemStr);
const now = Date.now();
// Check if the item has expired
if (now < item.expiry) {
// Lightweight safety check before rendering
if (isValid(item.value)) return item.value;
} else {
// Delete the stale entry if the TTL has passed
localStorage.removeItem(cacheKey);
}
}
}
// Fallback: Run inference if no valid cache exists
const session = await LanguageModel.create();
const response = await session.prompt(userInput);
// Store the result for future use (with an expiration)
const cacheData = {
value: response,
expiry: Date.now() + TTL_MS
};
localStorage.setItem(cacheKey, JSON.stringify(cacheData));
return response;
}