

Dipublikasikan: 30 April 2026
Dengan AI bawaan, situs atau aplikasi web Anda dapat melakukan tugas yang didukung AI, tanpa perlu men-deploy, mengelola, atau menghosting sendiri model. Anda mungkin merasa sulit untuk beralih dari demo ke fitur yang siap produksi. Dokumen ini membahas pertimbangan teknis dan UX untuk membantu Anda menghindari kesalahan umum.
Siapkan model pada waktu yang wajar
Berlaku untuk: semua API, misalnya, Summarizer, Translator, dan Writer.
Lakukan: Mulai sesi segera setelah Anda mengetahui dengan jelas niat pengguna untuk menggunakan fitur AI, misalnya, saat pengguna membuka halaman alat AI yang relevan, mengarahkan kursor ke ruang kerja AI, atau berinteraksi dengan UI di sekitar fitur. Memanaskan sesi memungkinkan model dimuat ke dalam memori secara diam-diam di latar belakang saat pengguna menyiapkan tugasnya, sehingga menghilangkan latensi mulai dingin yang dapat dihindari. Cobalah untuk selangkah lebih maju dengan memulai tugas AI berikutnya yang paling mungkin dilakukan segera setelah Anda mulai merender hasil saat ini, misalnya, jika fitur dirancang untuk penggunaan berulang.
Jangan: Kecuali jika diperlukan, jangan menunggu pengguna mengklik "Buat" untuk memulai sesi. Hal ini menyebabkan penundaan cold start, karena model harus dimuat terlebih dahulu ke dalam memori dan menyiapkan pipeline eksekusinya.
Menetapkan perintah awal selama pembuatan
Berlaku untuk: Prompt API.
Lakukan: Berikan petunjuk sistem selama inisialisasi sesi untuk meningkatkan kecepatan perintah pertama.
Jangan: Mulai dengan sesi kosong dan kirimkan petunjuk sistem sebagai bagian dari
panggilan prompt() pertama. Hal ini meningkatkan latensi karena memaksa model untuk memproses petunjuk tersebut pada saat terakhir.
// ✅ DO: Create the session as early as possible (tip on warming up the model early) and use initialPrompts for system instructions in the create call
const session = await LanguageModel.create({
initialPrompts: [
{ role: 'system', content: 'You are a helpful assistant specialized in code reviews.' }
]
});
// A few moments later, when the user triggers the AI feature
const review = await session.prompt(`Review the following code:\n\n${code}`);
// ❌ DON'T: Send instructions using prompt() after creation
// const slowerSession = await LanguageModel.create();
// await slowerSession.prompt(`You are a helpful assistant specialized in code reviews.\n\nReview the following code:\n\n${code}`); // Higher latency
Meng-clone sesi untuk tugas berulang
Berlaku untuk: Prompt API.
Untuk Prompt API, setiap sesi melacak konteks percakapan, dengan mempertimbangkan semua interaksi sebelumnya. Karena clone mewarisi semuanya dari sesi induknya, termasuk perintah awal dan semua histori interaksi hingga titik cloning, susun penggunaan Anda untuk mewarisi hanya yang Anda butuhkan.
Anjuran:
- Buat sesi dasar: Untuk menangani tugas yang tidak terkait secara efisien, buat sesi dasar yang hanya berisi petunjuk sistem Anda dan tidak ada konteks percakapan sebelumnya.
- Meng-clone baseline: Gunakan
clone()pada sesi dasar tersebut untuk tugas baru guna menghemat overhead penguraian ulang petunjuk sistem. Dengan begitu, Anda dapat membuat percakapan paralel atau mereset tugas ke dasarnya.
Jangan:
- Jangan menggunakan kembali sesi yang sama untuk tugas yang tidak terkait, dan hindari meng-clone sesi yang sudah berisi histori interaksi yang tidak perlu. Kedua pola tersebut dapat menyebabkan konteks sebelumnya yang tidak terkait mengganggu tugas Anda saat ini.
- Jangan memanggil
create()berulang kali dengan petunjuk sistem yang identik. Gunakan pola cloning sebagai gantinya untuk mengoptimalkan performa.
// ✅ DO: Create a baseline session and clone it for each new task
const baseSession = await LanguageModel.create({
initialPrompts: [{
role: 'system',
content: 'You are a technical editor...',
}],
});
// Clone the base session once for the first task
const task1 = await baseSession.clone();
const response1 = await task1.prompt("Review this first draft...");
// ... Repeat the cloning pattern for subsequent independent tasks
// Each task starts fresh from the baseline system instructions
// ❌ DON'T:
// Bad performance pattern: repeated create() calls for identical tasks.
// This forces the model to re-parse instructions every time, increasing latency.
// const sessionA = await LanguageModel.create({ initialPrompts: [...] });
// await sessionA.prompt("Task 1...");
// const sessionB = await LanguageModel.create({ initialPrompts: [...] });
// await sessionB.prompt("Task 2...");
// Bad quality pattern: reusing the same session for unrelated tasks.
// const session = await LanguageModel.create();
// await session.prompt("Analyze this financial report...");
// Unrelated task in the same session:
// await session.prompt("Now write a children's story...");
Menghancurkan sesi yang tidak digunakan
Berlaku untuk: Semua API.
Lakukan: Panggil destroy() secara eksplisit pada
sesi yang tidak lagi Anda perlukan, untuk mengosongkan memori saat fitur
tidak lagi digunakan. Jika Anda menggunakan pola cloning, pertahankan sesi dasar dan
hancurkan clone yang tidak lagi Anda perlukan.
Jangan: Membiarkan beberapa sesi besar tetap aktif. Setiap sesi menggunakan memori,
yang menyebabkan penggunaan resource yang tidak perlu dan dapat menjadi masalah. Sesi
akan dibersihkan secara alami oleh pengumpul sampah, tetapi memanggil destroy()
membebaskan memori lebih cepat.
// ✅ DO: Use the clone and destroy it immediately after
const clone = await baseSession.clone();
const response = await clone.prompt("Quick task...");
// Free memory right away: destry the clone, keep the baseSession
clone.destroy();
Merender respons streaming dengan aman dan efisien
Berlaku untuk: Semua API dengan dukungan streaming (Prompt, Summarizer, Writer, Rewriter, dan Translator).
Lakukan: Perlakukan semua output LLM sebagai konten yang tidak tepercaya. Bersihkan seluruh output gabungan, bukan hanya potongan, karena kode berbahaya dapat dibagi di seluruh update. Sebelum merender, gunakan Sanitizer API jika didukung. Untuk menghindari penurunan performa, gunakan parser Markdown streaming seperti streaming-markdown.
Jangan: Menetapkan innerHTML secara langsung pada setiap update chunk. Hal ini lambat,
terutama dengan pemformatan yang kompleks seperti penyorotan sintaksis, dan rentan terhadap
injeksi.
import * as smd from "streaming-markdown";
// Set up virtual buffer and Sanitizer API
const sanitizer = new Sanitizer({
allowElements: ['figure', 'figcaption', 'p', 'br', 'strong', 'em', 'img', 'a'],
allowAttributes: {
'loading': ['img'], 'decoding': ['img'], 'src': ['img'], 'href': ['a']
}
});
// Create an off-screen fragment so the parser doesn't cause flicker
// or trigger XSS in the live DOM during the building process.
const buffer = new DocumentFragment();
const parser = smd.parser_new(buffer);
// Use sanitizer as a gatekeeper / cleaner function so we can combine it with the streaming Markdown parser
function syncSanitized(target, sourceFragment) {
// .sanitize() returns a fresh, clean DocumentFragment
const cleanFragment = sanitizer.sanitize(sourceFragment);
// replaceChildren is the modern high-performance way to swap DOM content
target.replaceChildren(cleanFragment);
}
// Streaming Logic
// `chunks` keeps track of the raw string (useful for logs/debug)
chunks += chunk;
// Let the parser build the DOM incrementally in the buffer.
// This is high-performance because the buffer is not live
smd.parser_write(parser, chunk);
// Use the Sanitizer API to port the content safely to the container.
syncSanitized(container, buffer);
Mengoptimalkan input untuk kecepatan
Berlaku untuk: Semua API.
Lakukan: Hanya teruskan ke model apa yang benar-benar diperlukan. Hilangkan semua yang tidak relevan dengan tugas yang sedang dikerjakan. Untuk set data besar, berikan ringkasan singkat dan pilihan kecil item yang relevan.
Jangan: Mengirim teks mentah yang belum diproses, metadata yang tidak perlu, tag HTML, atau daftar besar yang tidak difilter ke API. Latensi meningkat secara signifikan seiring dengan ukuran input, yang dapat membuat fitur AI tampak rusak di banyak perangkat.
// ✅ DO: Send only relevant text
const cleanText = document.querySelector('#article').innerText;
const summary = await Summarizer.summarize(cleanText);
// ❌ DON'T: Send the entire DOM structure
// const dirtyText = document.querySelector('#article').innerHTML;
Menggunakan output terstruktur untuk hasil yang dapat diprediksi
Berlaku untuk: Prompt API.
Lakukan: Jika Anda ingin model menampilkan data dalam format tertentu, gunakan
output
terstruktur
dengan memberikan kolom responseConstraint untuk memberikan Skema JSON. Hal ini memastikan output dapat diprediksi dan mencegah Anda memerlukan pascapemrosesan yang rumit atau penguraian manual.
Jangan: Mengandalkan petunjuk bahasa alami (seperti "output hanya JSON") saja. Model mungkin menyertakan pengisi percakapan yang merusak parser Anda.
// ✅ DO: Use a JSON Schema for predictable results
const schema = {
type: "object",
properties: {
isTopicCats: { type: "boolean" }
}
};
const result = await session.prompt(`Is this post about cats?\n\n${post}`, {
responseConstraint: schema,
});
console.log(JSON.parse(result).isTopicCats);
Memisahkan pembuatan dari batasan panjang
Berlaku untuk: Prompt API, karena merupakan satu-satunya API yang mendukung skema output terstruktur.
Lakukan: Biarkan model membuat responsnya secara alami, lalu gunakan logika sisi klien untuk memangkas teks agar sesuai dengan UI Anda.
Jangan: Terapkan batas karakter yang ketat seperti maxLength: 125 menggunakan
skema output terstruktur. Jika respons
model lebih panjang dari batas yang Anda tetapkan, model dapat beralih ke
token kepadatan tinggi seperti bahasa asing atau emoji untuk memadatkan makna,
sehingga menghasilkan output yang tidak masuk akal.
/* DO: Handle overflow using CSS */
.result {
overflow: hidden;
white-space: nowrap;
text-overflow: ellipsis; /* Displays '…' */
}
// ❌ DON'T: Force length in the prompt
const result = await session.prompt("Write a bio in exactly 50 characters.");
Selalu memberi tahu pengguna
Berlaku untuk: Semua API.
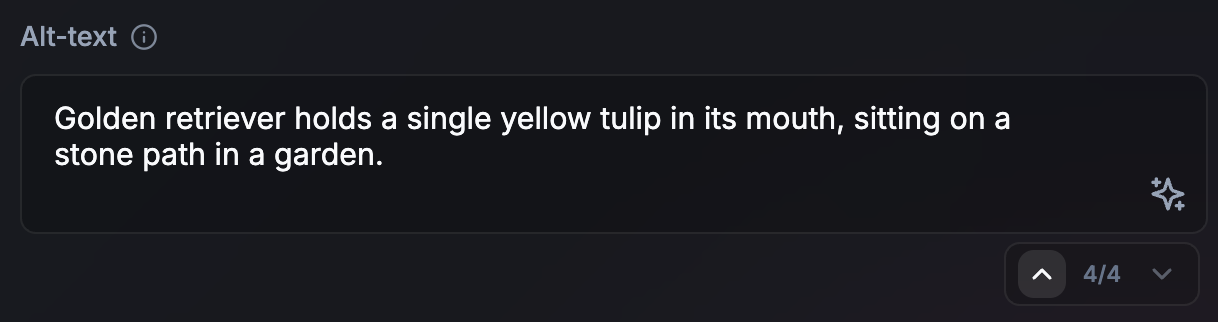
Lakukan: Bergantung pada kompleksitas dan perkiraan durasi tugas, gunakan animasi, petunjuk visual, dan indikator progres untuk terus memberi tahu pengguna. Pendekatan yang optimal bergantung pada kasus penggunaan Anda dan perkiraan panjang output API. Beberapa ide:
- Streaming untuk konten panjang: Untuk ringkasan atau chat, streaming membuat efek mesin tik per token secara default. Hal ini dapat terasa alami dan memberikan masukan langsung.
- Non-streaming untuk tugas pendek (atau tugas asinkron panjang): Untuk output pendek, misalnya, teks alternatif, non-streaming dapat membuat UI yang lebih sempurna. Fitur ini juga memberikan waktu untuk mempersiapkan tugas AI berikutnya secara spekulatif saat tugas saat ini dirender. Pendekatan ini juga berfungsi untuk tugas asinkron atau latar belakang yang lebih lama. Jika pengguna tidak diblokir pada output untuk melanjutkan perjalanannya, tidak ada kebutuhan mendesak untuk menghasilkan output saat hal itu terjadi. Memberi sinyal bahwa proses sedang berlangsung di UI.
- Transisi visual untuk pembaruan: Saat menerjemahkan atau menulis ulang teks, gunakan animasi, misalnya, pengubahan bentuk kata.
Jangan: Mengupdate UI tanpa isyarat visual.
Selaras dengan model mental pengguna tentang waktu dan pekerjaan
Berlaku untuk: Semua API.
Lakukan: Pertimbangkan penundaan buatan selama satu atau dua detik jika respons hampir instan. Anehnya, pengguna mungkin menganggap hasil lebih tepercaya jika mereka melihat proses pembuatan yang sesuai dengan tingkat kesulitan tugas yang mereka rasakan. Gunakan animasi untuk menandakan bahwa proses AI telah terjadi.
Jangan: Mengejutkan pengguna dengan penggantian UI instan.
Memungkinkan pengguna menavigasi dan mengurungkan pengeditan AI dengan cepat
Berlaku untuk: Semua API.
Lakukan: Lengkapi UI Anda dengan stepper atau histori navigasi yang memungkinkan pengguna menjelajahi berbagai hasil dengan percaya diri, dan memungkinkan mereka mengurungkan pengeditan AI dengan cepat. Hal ini memastikan bahwa berbagai versi masih tersedia.
Jangan: Menimpa draf pengguna sebelumnya, atau hasil AI yang mungkin disukai pengguna tanpa cara untuk kembali, mengembalikan, atau membandingkan versi.
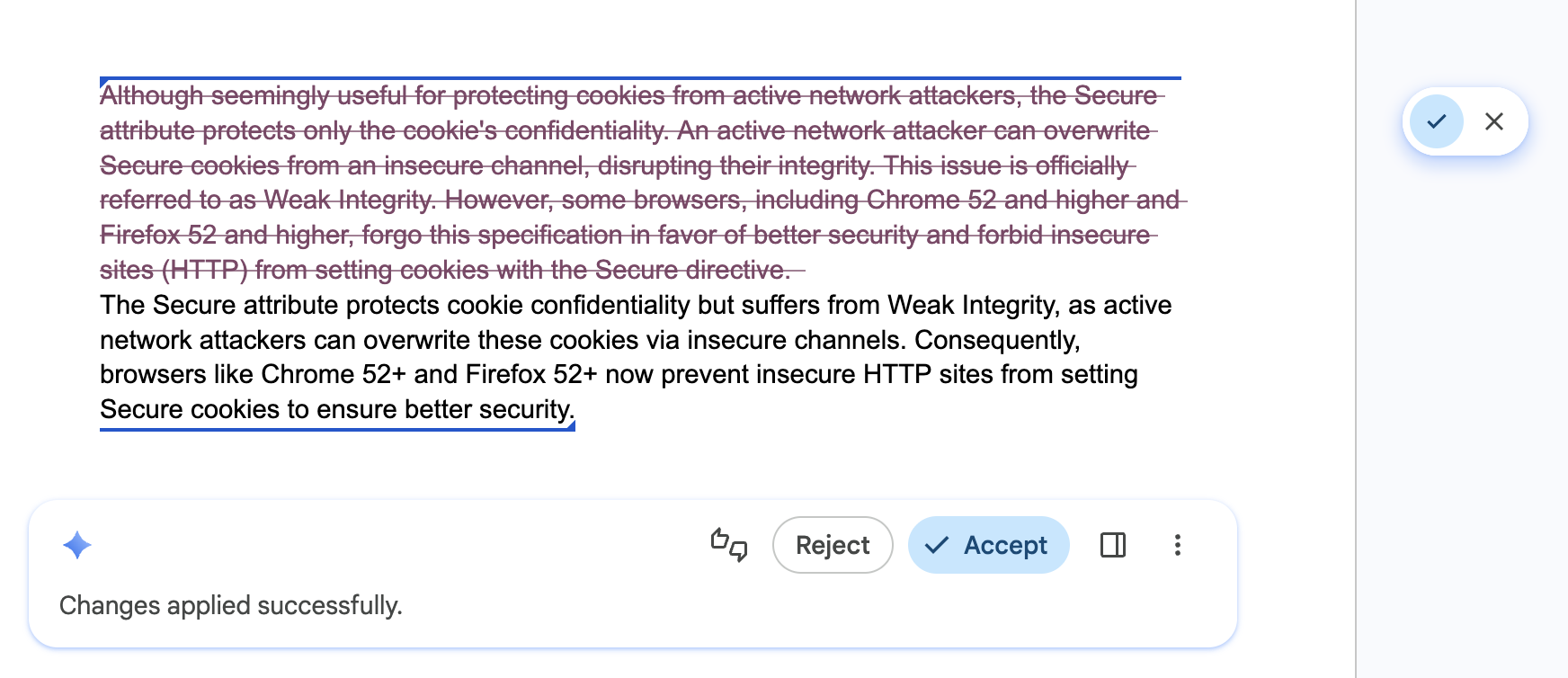
Mendukung kontrol dan penggantian pengguna
Berlaku untuk: Semua API.
Lakukan: Menjadikan pengguna sebagai editor akhir semua konten yang dibuat. Menyediakan penggantian intuitif sehingga pengguna mempertahankan kepemilikan penuh untuk output akhir. API dapat memberikan hasil yang salah.
Jangan: Memaksakan hasil buatan AI sebagai satu-satunya opsi.
Menyimpan hasil dalam cache untuk tugas berulang
Berlaku untuk: Semua API.
Lakukan: Terapkan cache hasil lokal (misalnya, menggunakan sessionStorage atau
IndexedDB) untuk input atau kueri berulang. Lakukan normalisasi input dengan menghapus spasi dan mengubah huruf menjadi huruf kecil untuk meningkatkan cache ditemukan. Untuk input berat, misalnya, gambar, buat hash untuk digunakan sebagai kunci cache. Tetapkan time to live (TTL) yang konservatif untuk cache Anda (atau sajikan hasil yang di-cache sambil memperbaruinya di latar belakang). Izinkan pengguna memicu inferensi baru jika hasilnya tidak memuaskan.
Jangan: Menjalankan ulang inferensi yang sama untuk kueri penelusuran berulang atau input data yang identik jika variabilitas tidak diinginkan, misalnya saat pengguna berpindah-pindah antara hasil penelusuran. Hal ini mengoptimalkan responsivitas dan penggunaan komputasi lokal yang efisien.
// ✅ DO: Check a local cache before running inference
async function getAiResponse(userInput, forceRefresh = false) {
// Normalize the query to increase cache hits
const query = userInput.trim().toLowerCase();
const cacheKey = `ai_results_${query}`;
const TTL_MS = 3600000; // 1 hour conservative TTL
if (!forceRefresh) {
const itemStr = localStorage.getItem(cacheKey);
if (itemStr) {
const item = JSON.parse(itemStr);
const now = Date.now();
// Check if the item has expired
if (now < item.expiry) {
// Lightweight safety check before rendering
if (isValid(item.value)) return item.value;
} else {
// Delete the stale entry if the TTL has passed
localStorage.removeItem(cacheKey);
}
}
}
// Fallback: Run inference if no valid cache exists
const session = await LanguageModel.create();
const response = await session.prompt(userInput);
// Store the result for future use (with an expiration)
const cacheData = {
value: response,
expiry: Date.now() + TTL_MS
};
localStorage.setItem(cacheKey, JSON.stringify(cacheData));
return response;
}