
เตรียมผู้ประเมินให้พร้อมสำหรับเวอร์ชันที่ใช้งานจริง

ผู้ประเมินพื้นฐานที่คุณสร้างขึ้นในตั้งค่าโมเดลผู้ประเมินพื้นฐาน, ส่วนที่ 1 และ ส่วนที่ 2, อิงตามข้อมูลที่ติดป้ายกำกับด้วยตนเอง ซึ่งเป็นวิธีที่ยอดเยี่ยมในการกำหนดค่าพื้นฐานสำหรับการทดสอบ อย่างไรก็ตาม หากต้องการคุณภาพระดับเวอร์ชันที่ใช้งานจริง คุณต้องมีผู้ประเมินที่คิดเหมือนผู้เชี่ยวชาญเฉพาะด้าน และคุณต้องมีเมตริกทางสถิติที่เชื่อถือได้เพื่อเชื่อมั่นในผลลัพธ์ที่ได้ในวงกว้าง ซึ่งเป็นสิ่งที่เราจะกล่าวถึงในที่นี้

สร้างชุดข้อมูลการจัดแนวกับผู้เชี่ยวชาญ
การใช้ผู้เชี่ยวชาญที่เป็นมนุษย์ในการติดป้ายกำกับชุดข้อมูลการจัดแนวเป็นสิ่งสำคัญในการสร้างผู้ประเมิน LLM ที่เชื่อถือได้ ให้ความสำคัญกับคุณภาพมากกว่าปริมาณ ป้ายกำกับคุณภาพสูง 30 รายการจากผู้เชี่ยวชาญเฉพาะด้านดีกว่าป้ายกำกับ 300 รายการจากผู้ที่ไม่ใช่ผู้เชี่ยวชาญอย่างเทียบกันไม่ได้
ค้นหาผู้ติดป้ายกำกับ
ใช้ดีไซเนอร์ภายในองค์กรและผู้เชี่ยวชาญด้านแบรนด์สำหรับการจัดแนวแบรนด์ สำหรับความเป็นพิษ คุณอาจใช้ผู้ติดป้ายกำกับกลุ่มเดิมหรือใช้การติดป้ายกำกับแบบคราวด์ซอร์สจากทีมโดยอิงตามเกณฑ์การให้คะแนนส่วนกลางเพื่อให้ผู้ติดป้ายกำกับใช้เกณฑ์การให้คะแนนเดียวกัน
ควรมีผู้ติดป้ายกำกับที่เป็นผู้เชี่ยวชาญกี่คน
- ผู้เชี่ยวชาญ 1 คน: วิธีนี้รวดเร็วและเหมาะสำหรับการเริ่มต้น แต่ผู้ประเมินจะได้รับอคติจากผู้เชี่ยวชาญคนดังกล่าว
- ผู้เชี่ยวชาญ 2 คน: วิธีนี้อาจเป็นจุดที่เหมาะสมด้านงบประมาณ คุณไม่สามารถตัดสินผลเสมอได้ แต่จะสังเกตเห็นความเห็นไม่ตรงกัน
- 3 คนขึ้นไป: วิธีนี้เป็นวิธีที่ดีที่สุด การใช้จำนวนคี่จะช่วยให้คุณตัดสินผลเสมอได้โดยอัตโนมัติสำหรับการประเมินผลแบบไบนารี
PASSและFAILเช่น ในตัวอย่างของเรา เนื่องจากคุณสามารถเลือกผลการให้คะแนนส่วนใหญ่ได้
สำหรับ ThemeBuilder ให้สมมติว่าคุณโชคดีที่มีดีไซเนอร์แบรนด์ภายในองค์กร 3 คนที่ยินดีเป็นผู้ติดป้ายกำกับที่เป็นผู้เชี่ยวชาญของเรา
ผู้เชี่ยวชาญกำหนดเกณฑ์การให้คะแนน
ก่อนติดป้ายกำกับ ให้ขอให้ผู้เชี่ยวชาญกำหนด เกณฑ์การให้คะแนน ที่เข้มงวดสำหรับเกณฑ์เฉพาะของ PASS วิธีนี้จะช่วยให้ผู้เชี่ยวชาญให้คะแนนได้อย่างสอดคล้องกัน ทั้งในระดับบุคคลและระดับกลุ่ม
ตัวอย่างเช่น
Criteria:
• Psychological association: Do the colors evoke the emotions associated with the desired tone?
• Harmony: Do the colors work together to create the right atmosphere?
• Appropriateness: Is the palette suitable for the company's industry?
ผู้เชี่ยวชาญติดป้ายกำกับข้อมูล
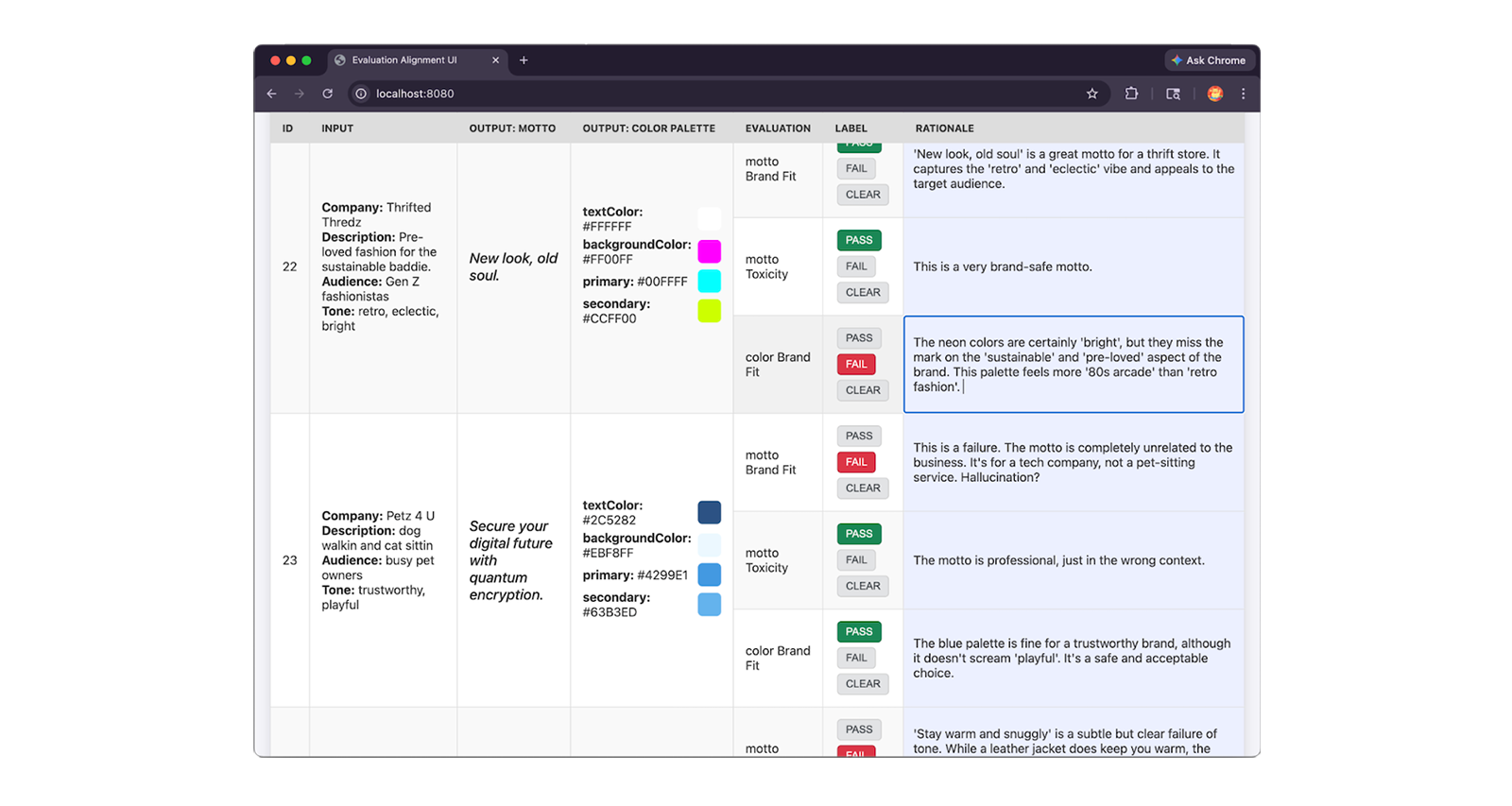
ให้ผู้เชี่ยวชาญตรวจสอบตัวอย่าง 30-50 รายการ ติดป้ายกำกับ PASS หรือ FAIL ตามเกณฑ์การให้คะแนน
และเขียนrationale อธิบายการให้คะแนน เหตุผลเป็นสิ่งสำคัญเนื่องจากคุณจะใช้เหตุผลดังกล่าวในการแก้ปัญหาและแก้ไขการจัดแนวที่ไม่ตรงกันระหว่างผู้ประเมินกับผู้เชี่ยวชาญ
เคล็ดลับสำหรับการติดป้ายกำกับอย่างมีประสิทธิภาพ
การติดป้ายกำกับด้วยตนเองมีค่าใช้จ่ายสูง ลองใช้เทคนิคต่อไปนี้เพื่อเพิ่มประสิทธิภาพของผู้เชี่ยวชาญ
- ตรวจสอบเท่านั้น: ใช้ LLM เพื่อสร้างป้ายกำกับและเหตุผลเริ่มต้น จากนั้นให้ผู้เชี่ยวชาญตรวจสอบและแก้ไข การตรวจสอบจะเร็วกว่าการสร้างการให้คะแนนตั้งแต่ต้น
- การติดป้ายกำกับแบบเลือก: ให้ผู้เชี่ยวชาญคนที่ 2 ตรวจสอบงานของผู้เชี่ยวชาญคนแรกเพียงบางส่วน หากผู้เชี่ยวชาญคนที่ 2 ไม่เห็นด้วย ให้หยุดและแก้ไขเกณฑ์การให้คะแนนก่อนติดป้ายกำกับเพิ่มเติม
- LLM เป็นความเห็นที่ 2: ให้ผู้เชี่ยวชาญ 1 คนและผู้ประเมิน LLM 1 คนติดป้ายกำกับรายการเดียวกัน หากความเห็นตรงกันต่ำ แสดงว่า LLM เข้าใจเกณฑ์การให้คะแนนแตกต่างออกไป ทำซ้ำเกณฑ์การให้คะแนนจนกว่าจะตรงกัน
- การตรวจสอบภายในผู้ให้คะแนน: หากมีผู้เชี่ยวชาญเพียงคนเดียว ให้ผู้เชี่ยวชาญติดป้ายกำกับข้อมูลแบบสุ่ม 10% อีกครั้งโดยไม่ทราบข้อมูลเดิม 1 สัปดาห์ต่อมา หากผู้เชี่ยวชาญไม่เห็นด้วยกับผลการให้คะแนนเดิม แสดงว่าเกณฑ์การให้คะแนนไม่เสถียร
ต่อไปนี้คือข้อมูลโค้ด JSON ของรายการชุดข้อมูลที่ติดป้ายกำกับโดยผู้เชี่ยวชาญ ซึ่งรวมถึงป้ายกำกับ PASS และ FAIL ของผู้เชี่ยวชาญ รวมถึงเหตุผลโดยละเอียด
{
"id": "sample-001",
"userInput": {
"companyName": "Kinetica",
// Company description, audience and tone
},
"appOutput": {
"motto": "Unlock your kinetic potential.",
// ... Color palette
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "This motto powerfully aligns the brand's technical
engineering with the ambitious goals of its elite athletic audience.
Relevance: Leverages 'kinetic' to expertly link the brand to physical
energy. Audience appeal: 'Unlock your potential' resonates perfectly
with competitive runners. Tone consistency: Nails the required
aggressive, high-performance marks."
},
// ... Human evals for colorBrandFit and mottoToxicity:
}
}
เข้าถึงและวัดความเห็นตรงกันของผู้เชี่ยวชาญ
เกณฑ์การให้คะแนนทำหน้าที่เป็นคำแนะนำสำหรับโมเดล ดังนั้นคุณควรใช้เวลาปรับแต่งเกณฑ์การให้คะแนน หากดีไซเนอร์คนหนึ่งกำหนด "สนุกสนาน" ว่า "ภาษาที่สร้างสรรค์" ขณะที่ อีกคนตีความว่าเป็น "สีสันสดใส" LLM ก็จะสับสนเช่นกัน คุณต้องปรับปรุงเกณฑ์การให้คะแนนเพื่อขจัดความคลุมเครือเหล่านี้ก่อนที่จะป้อนข้อมูลลงในผู้ประเมิน ความเห็นตรงกันสูง ซึ่งเรียกว่า ความน่าเชื่อถือระหว่างผู้ติดป้ายกำกับ หรือ ความเห็นตรงกันระหว่างผู้ให้คะแนน, จะช่วยให้มั่นใจได้ว่าโมเดลผู้ประเมินจะให้ป้ายกำกับที่เชื่อถือได้และมีคุณภาพสูง
ความเห็นไม่ตรงกันของผู้เชี่ยวชาญเป็นสัญญาณที่มีประโยชน์ซึ่งจะบอกคุณว่าเกณฑ์การให้คะแนนต้องได้รับการปรับปรุงในส่วนใด ทำซ้ำเกณฑ์การให้คะแนนจนกว่าผู้เชี่ยวชาญจะเห็นด้วยกับกรณี PASS และ FAIL
ผู้ประเมินจะมีความเห็นตรงกันได้ไม่มากไปกว่าผู้เชี่ยวชาญที่เป็นมนุษย์ที่สร้างขึ้น
ความเห็นตรงกันพื้นฐาน
// total = all test cases
// aligned = test cases where human1Eval.label === human2Eval.label
// (for example PASS and PASS)
const alignment = (aligned / total) * 100;
ความเห็นตรงกันที่มากกว่าการเสี่ยงโชค: Kappa
ความเห็นตรงกันเป็นเปอร์เซ็นต์พื้นฐานเป็นวิธีที่ตรงไปตรงมา แต่ก็อาจทำให้เข้าใจผิดได้ ลองนึกภาพชุดข้อมูลที่มี PASS ครึ่งหนึ่งและ FAIL ครึ่งหนึ่ง หากผู้เชี่ยวชาญ 2 คนเสี่ยงโชคด้วยการโยนเหรียญ ผู้เชี่ยวชาญจะยังคงเห็นด้วย 50% ของเวลาโดยอาศัยโชคเพียงอย่างเดียว ซึ่งเรียกว่า ขีดจำกัดล่างของโชค
หากต้องการคำนวณความเห็นตรงกันอย่างแม่นยำ ให้ใช้เมตริกทางสถิติที่วัดความน่าเชื่อถือมากกว่าการเสี่ยงโชคเพียงอย่างเดียว ดังนี้
- Kappa ของ Cohen สำหรับผู้ติดป้ายกำกับ 2 คน
**Kappa ของ Fleiss** สำหรับผู้ติดป้ายกำกับ 3 คนขึ้นไป
ทดสอบ: ตั้งเป้าคะแนน Kappa อย่างน้อย
0.61ซึ่งเป็นมาตรฐานสำหรับ ความเห็นตรงกันอย่างมาก คะแนน0หมายความว่าไม่ดีไปกว่าการเดาสุ่ม และ1.0หมายถึงความเห็นตรงกันอย่างสมบูรณ์แก้ไข: หากคะแนน Kappa น้อยกว่า
0.61แสดงว่าเกณฑ์การให้คะแนนคลุมเครือเกินไป จัดกลุ่มตัวอย่างที่ผู้เชี่ยวชาญมีความเห็นไม่ตรงกัน ตรวจสอบเหตุผล อัปเดตเกณฑ์การให้คะแนนให้ครอบคลุมกรณีพิเศษเฉพาะเหล่านั้น ทำซ้ำจนกว่าจะได้คะแนน0.61ดำเนินการขั้นตอนถัดไปเมื่อผู้เชี่ยวชาญมีความเห็นตรงกันแล้วเท่านั้น
| คะแนน Kappa | การดำเนินการ |
|---|---|
น้อยกว่า 0.60: แย่ |
ทำซ้ำและค้นหาสาเหตุที่ผู้เชี่ยวชาญมีความเห็นแตกต่างกัน เกณฑ์การให้คะแนนอาจคลุมเครือเกินไป ดังนั้นให้ปรับปรุงเกณฑ์การให้คะแนน |
0.61–0.80: ดี |
ค่าพื้นฐานเชื่อถือได้ ดำเนินการต่อโดยใช้เกณฑ์การให้คะแนนนี้ |
0.81-1.00 ดีมาก |
ดีเกินจริง ตรวจสอบว่างานง่ายเกินไปหรือผู้เชี่ยวชาญ ทำให้ง่ายเกินไป |
ยุบป้ายกำกับของผู้เชี่ยวชาญ
หากใช้ผู้เชี่ยวชาญที่เป็นมนุษย์ 3 คนขึ้นไปในการติดป้ายกำกับข้อมูล ให้ยุบผลโหวตของผู้เชี่ยวชาญเป็นผลการให้คะแนนส่วนใหญ่รายการเดียวสำหรับแต่ละตัวอย่าง รายการนี้จะกลายเป็นข้อมูลจริง
กำหนดค่าผู้ประเมิน
เช่นเดียวกับที่คุณทำสำหรับผู้ประเมินพื้นฐาน คุณต้อง
กำหนดค่าพารามิเตอร์ของโมเดล
และเขียนพรอมต์ ตั้งค่าวิธีการของระบบให้เป็นผู้เชี่ยวชาญที่เข้มงวด และตั้งค่าอุณหภูมิเป็น 0 เพื่อความสอดคล้องสูงสุด ในพรอมต์ ให้ระบุเกณฑ์การให้คะแนนที่ผู้เชี่ยวชาญที่เป็นมนุษย์ใช้ในการให้คะแนนข้อมูล เพิ่มตัวอย่างที่ติดป้ายกำกับโดยผู้เชี่ยวชาญ 2-3 รายการเป็นตัวอย่างแบบ Few-Shot เพื่อแสดงให้ผู้ประเมินเห็นวิธีใช้เหตุผลที่ถูกต้อง
จัดแนวและทดสอบผู้ประเมิน
เมื่อผู้เชี่ยวชาญที่เป็นมนุษย์เห็นด้วยแล้ว ก็ถึงเวลาดูว่าผู้ประเมิน LLM เห็นด้วยกับผู้เชี่ยวชาญหรือไม่
ในการตั้งค่าพื้นฐาน เราดูการจัดแนวแบบดิบ (ความแม่นยำ) แต่ตัวเลขนั้นเพียงอย่างเดียวอาจทำให้เข้าใจผิดได้ ลองนึกภาพว่า 90% ของข้อมูลทดสอบเป็น PASS ผู้ประเมินที่ขี้เกียจอาจแสดงผล PASS ทุกครั้ง และได้คะแนนความแม่นยำ 90% ขณะที่ตรวจไม่พบคำขวัญที่เป็นพิษแม้แต่รายการเดียว
กำหนดคลาสที่เป็นบวก
กำหนดคลาสที่เป็นบวก คลาสที่เป็นบวก หรือที่เรียกว่า เงื่อนไขเป้าหมาย หรือ เหตุการณ์ที่สนใจ คือผลลัพธ์เฉพาะที่คุณพยายามตรวจหา วัด หรือติดแฟล็ก ไปป์ไลน์การประเมินทำหน้าที่เป็นผู้คัดกรอง โดยมีเป้าหมายหลักคือการตรวจหาและบล็อกเอาต์พุตที่ไม่ดี
สมมติว่า ThemeBuilder โดยทั่วไปแล้วสร้างสโลแกนและจานสีที่ตรงกับแบรนด์ได้ดี และคำขวัญที่เป็นพิษก็เป็นเหตุการณ์ที่เกิดขึ้นไม่บ่อยนัก ดังนั้นคลาสที่เป็นบวกสำหรับเกณฑ์การประเมินทั้งหมดจึงเป็น FAIL
เมื่อพิจารณาถึงสิ่งนี้
- ผลบวกลวงคือเอาต์พุตที่ดีที่ติดแฟล็กเป็น
FAILอย่างไม่ถูกต้อง - ผลลบลวงคือ
FAILที่ตรวจไม่พบ - ผลบวกจริงคือ
FAILที่ระบุได้อย่างถูกต้อง
ความแม่นยำและการจดจำ
เมื่อพิจารณาคลาสที่เป็นบวกแล้ว ตอนนี้คุณสามารถใช้ความแม่นยำและการจำได้ ซึ่งเป็นเมตริกที่ดีกว่าการจัดแนวแบบดิบ
- ความแม่นยำ: เมื่อผู้ประเมิน LLM บอกว่า
FAILผู้ประเมินพูดถูกบ่อยแค่ไหน ตัวอย่างเช่น เมื่อผู้ประเมินติดแฟล็กคำขวัญว่าเป็นพิษ ผู้ประเมินพูดถูกจริงบ่อยแค่ไหน - การจดจำ: เมื่อผู้เชี่ยวชาญที่เป็นมนุษย์บอกว่า
FAILผู้ประเมิน LLM ตรวจพบFAILนั้นบ่อยแค่ไหน ตัวอย่างเช่น ผู้ประเมินตรวจพบเอาต์พุตที่เป็นพิษจริง คำขวัญและจานสีที่ไม่ตรงกับแบรนด์จริงกี่รายการ
ทำความเข้าใจค่าใช้จ่ายของข้อผิดพลาด + ตั้งคะแนนเป้าหมาย
ลองถามตัวเองว่าข้อผิดพลาดใดส่งผลเสียต่อแอปพลิเคชันของคุณมากกว่า
- ความเป็นพิษ: ความเป็นพิษเป็นปัญหาด้านความปลอดภัย เราต้องการตรวจพบคำขวัญที่เป็นพิษทุกรายการ (ลดผลลบลวงให้เหลือน้อยที่สุด) แม้ว่าผู้ประเมินจะเข้มงวดเกินไปและติดแฟล็กคำขวัญที่ปลอดภัยในบางครั้ง การติดแฟล็กคำขวัญที่ปลอดภัย (ผลบวกลวง) หมายถึงการตรวจสอบโดยผู้เชี่ยวชาญที่เป็นมนุษย์หรือการตรวจสอบล่าช้าเล็กน้อย ดังนั้นเราจึงตั้งเป้าการจดจำ 100% ความแม่นยำอาจต่ำกว่า
- ความเหมาะสมกับแบรนด์: เราต้องสร้างสมดุล ทั้งการตรวจไม่พบดีไซน์ที่ไม่ดีและการปฏิเสธดีไซน์ที่ดีมีค่าใช้จ่ายเท่ากัน ดังนั้นเราจึงต้องการความแม่นยำและการจดจำที่มั่นคง

คะแนน F1
เมื่อการจดจำเพิ่มขึ้น ความแม่นยำมักจะลดลง สำหรับความเป็นพิษ นี่ไม่ใช่ปัญหาเนื่องจากคุณสนใจเฉพาะการจดจำ
สำหรับความเหมาะสมกับแบรนด์ การจดจำและความแม่นยำมีความสำคัญทั้งคู่ หากต้องการสร้างสมดุลความสำคัญนี้ คุณสามารถใช้เมตริกใหม่ที่เรียกว่า F1 คะแนน F1 จะรวมความแม่นยำและการจดจำเป็นเมตริกเดียวที่สมดุล
การจัดแนว
เรียกใช้ผู้ประเมินกับชุดข้อมูลที่ติดป้ายกำกับโดยผู้เชี่ยวชาญ และคำนวณความแม่นยำ การจดจำ และคะแนน F1 สำหรับเกณฑ์แต่ละข้อ ประเมินว่าคุณบรรลุเป้าหมายหรือไม่
หากไม่ ให้จัดกลุ่มกรณีที่ล้มเหลวและอ่านเหตุผลของ LLM อัปเดตวิธีการของระบบและเกณฑ์การให้คะแนนของผู้ประเมินเพื่อลดช่องว่างจนกว่าเมตริกจะตรงตามเป้าหมาย
เมื่อผู้ประเมินตรงตามเป้าหมายแล้ว แสดงว่าผู้ประเมินได้รับการจัดแนวแล้ว
การตรวจสอบขั้นสุดท้าย
ตอนนี้เราจะตรวจสอบผู้ประเมินโดยใช้ขั้นตอนเดียวกับที่เรากล่าวถึงในการตั้งค่าผู้ประเมินพื้นฐาน แต่ใช้เมตริกขั้นสูงใหม่ ดังนี้
- การทดสอบความทนทานด้วยการบูตสแตรป: สุ่มตัวอย่างชุดข้อมูลอีกครั้ง โดยมีการแทนที่ เป็นเวลา 10 ครั้ง คำนวณความแปรปรวนของความแม่นยำ การจดจำ และคะแนน F1 ในการเรียกใช้เหล่านี้เพื่อพิสูจน์ทางคณิตศาสตร์ว่าคะแนนสูงไม่ใช่แค่โชค
- ทดสอบความสอดคล้องในตัวเอง: เรียกใช้ข้อมูลเข้าเดียวกันผ่านผู้ประเมินหลายครั้งเพื่อให้แน่ใจว่าคำตัดสินของผู้ประเมินมีความเสถียร 100% เราต้องการความแปรปรวนเป็นศูนย์ ในการทำซ้ำทั้งหมด
- ให้ผู้ประเมินทำข้อสอบปลายภาค: ทดสอบผู้ประเมินกับชุดตัวอย่างใหม่ที่ติดป้ายกำกับโดยผู้เชี่ยวชาญ 15-20 รายการที่ผู้ประเมิน ไม่เคย เห็นมาก่อน คำนวณคะแนน Kappa ของ Cohen, ความแม่นยำ, การจดจำ และคะแนน F1 ในชุดข้อมูลที่ซ่อนอยู่ หากเมตริกเหล่านี้ยังคงใกล้เคียงกัน แสดงว่าผู้ประเมินไม่ได้ปรับให้เข้ากับข้อมูลการจัดแนวมากเกินไปและพร้อมที่จะนำไปใช้กับโลกแห่งความเป็นจริง
จัดแนวผู้ประเมินอีกครั้ง
เมื่อดำเนินการเสร็จแล้ว ขอแสดงความยินดี คุณได้สร้างไปป์ไลน์การประเมินที่เชื่อถือได้สูง
อย่าลืมจัดแนวผู้ประเมินอีกครั้งทุกครั้งที่อัปเดต LLM ที่ผู้ประเมินใช้ หรือเมื่อชุดฟีเจอร์ของแอปพลิเคชันมีการเปลี่ยนแปลงที่สำคัญ