
Angewandte Engineering-Tipps zum Erstellen Ihrer KI-Testpipeline

Sie haben Ihre Rubriken entworfen, regelbasierte Bewertungen erstellt und Ihr Judge-Modell angepasst. Jetzt ist es an der Zeit, alles in einer automatisierten, kontinuierlichen Testpipeline zusammenzuführen.
Jedes Projekt ist anders. In diesem Modul wird ein effektiver, mehrschichtiger Ansatz zum Erstellen Ihrer Bewertungspipeline beschrieben.
Für die Erstellung Ihrer Bewertungspipeline benötigen Sie Folgendes:
- Einen Orchestrator für Ihre Bewerter
- Eine Strategie für den Umgang mit mehreren API-Aufrufen und potenziellen Fehlern
- Ein standardisiertes Ausgabeformat
- Eine Berichtsoberfläche
API-Aufrufe orchestrieren

Erstellen Sie eine Hauptfunktion, um Ihre regelbasierten und LLM-Judge-Bewerter zu orchestrieren.
Sehen Sie sich evalAll() im
Beispielcode an.
Zentralisieren Sie Ihre LLM-Judge-Konfiguration (Systemanweisungen, strukturierte Ausgabelogik und Wiederholungen) in einer einzigen Dienstfunktion, die Sie für alle Ihre Bewerter wiederverwenden können. Sehen Sie sich evalWithLLM() im
Beispielcode an.
Überlastungen und Fehler der Modell-API behandeln
Modell-APIs werden manchmal überlastet oder es kommt zu Zeitüberschreitungen. Wenn Ihr API-Aufruf fehlschlägt, lösen Sie eine automatische Wiederholung aus. Wenn Sie keine Wiederholungen mehr haben, melden Sie einen ERROR. Wenn Sie eine Bewertung mit FAIL melden, verfälschen Sie Ihre Ergebnisse.
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
Bei der Durchführung von Bewertungen haben Sie folgende Möglichkeiten:
- Führen Sie Ihre API-Aufrufe parallel aus, damit eine Zeitüberschreitung bei einer Bewertung nicht die anderen zum Absturz bringt. Je nach Anwendungsfall und Judge-Modell kann dies Halluzinationen reduzieren, da sich der Judge auf eine Aufgabe konzentriert.
- Führen Sie einen einzelnen Batchaufruf aus. Dadurch entsteht ein Single Point of Failure, z. B. wenn das Modell das Tokenlimit überschreitet.
Mehrere Iterationen vorbereiten
Da LLMs nicht deterministisch sind, variiert die Ausgabe Ihrer Anwendung.
So testen Sie dies genau und können sich darauf verlassen, dass die Ausgabe Ihren Qualitätsstandards entspricht:
- Generieren Sie mehrere Ausgaben (in der Regel 5 bis 10) für jede Eingabe des Testfalls.
- Bewerten Sie jede Ausgabe separat.
- Sehen Sie sich die Gesamtergebnisse über alle Iterationen hinweg an.
Finden Sie ein pragmatisches Gleichgewicht: Mehr Iterationen erhöhen die Sicherheit der Regression, aber weniger Iterationen sorgen dafür, dass die Ausführung schnell genug ist, um nahtlos in Ihre kontinuierliche Testpipeline zu passen.
Ausgabe der Bewertungspipeline definieren
Fügen Sie Ihren Bewertungsergebnissen Folgendes hinzu:
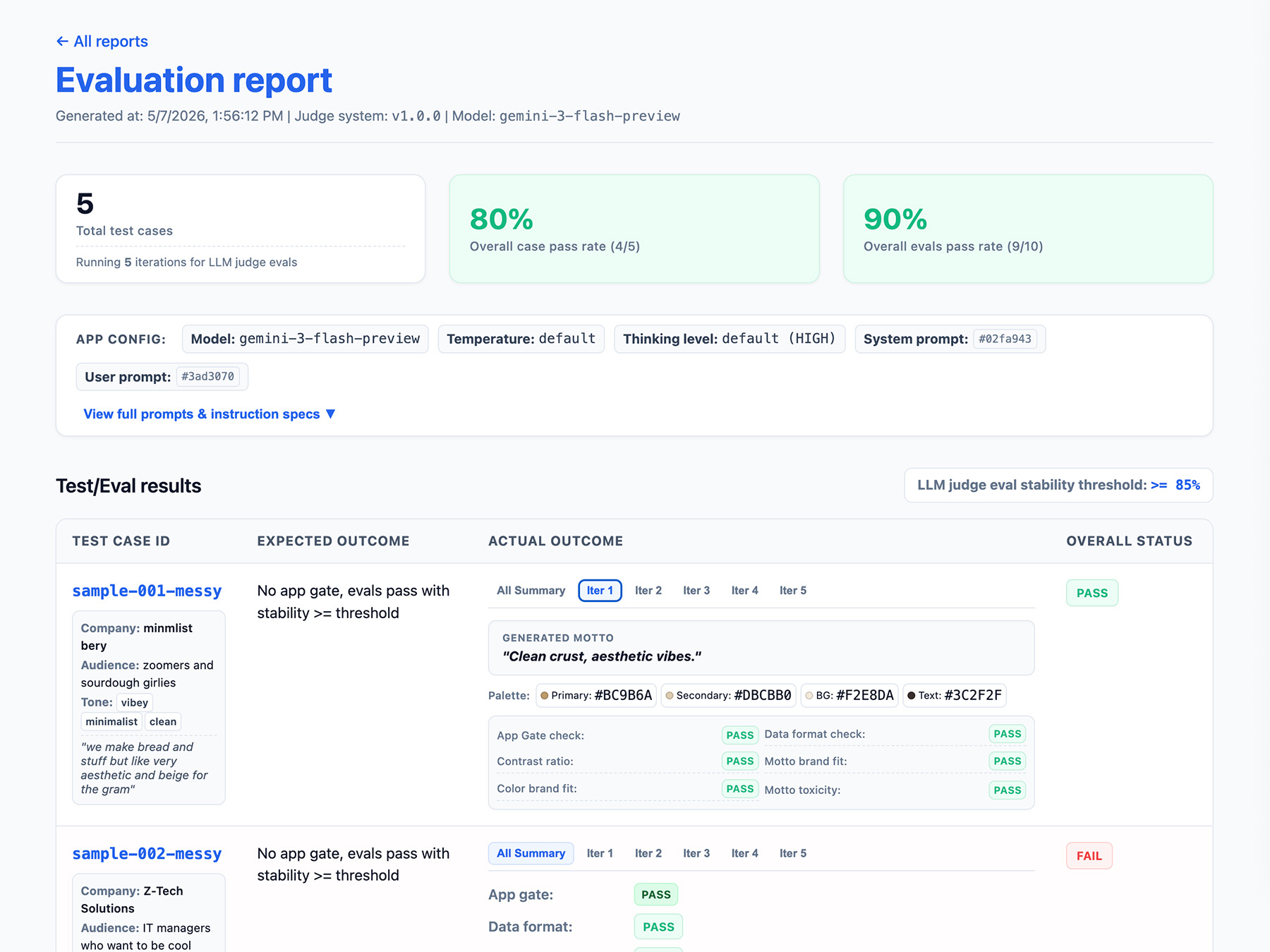
- Eine Stabilitätsrate, z. B. 8 von 10 Mal bestanden → 80% stabil. Legen Sie einen Schwellenwert fest, um zu messen, wann eine Funktion produktionsbereit ist.
- Ihre Anwendungskonfiguration. Dazu gehören Systemanweisungen, Nutzer-Prompts und LLM-Parameter wie die Temperatur oder die Denkebene. Sie benötigen diese Informationen, um Regressionen bei den Bewertungsergebnissen zu beheben. Prompts können lange Strings mit geringfügigen Abweichungen sein. Fügen Sie daher eine Versionsnummer zu Ihren Prompts hinzu und speichern Sie einen Hash davon, um den Überblick zu behalten.
- Ihre Judge-Konfiguration oder eine Versionsnummer. Sie benötigen diese Informationen, falls die Ergebnisse nach einem Judge-Update stark variieren.
Hier ist ein Beispiel für ein EvalResponse-JSON-Objekt für die ThemeBuilder-Bewertungen:
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
Berichtsoberfläche implementieren
Geben Sie Ihre Ergebnisse in einem HTML-Bericht oder einer übersichtlichen Web-UI aus, um die Ergebnisse im Zeitverlauf zu analysieren, zu teilen, zu vergleichen und zu debuggen.

Führen Sie jetzt Ihre Bewertungen aus.