
טיפים להנדסה יישומית לבניית פייפליין לבדיקת AI.

עיצבתם את הקריטריונים להערכה, כתבתם את ההערכות מבוססות הכללים והתאמתם את מודל השופט. עכשיו הגיע הזמן לחבר את כל זה לצינור אוטומטי של בדיקות רציפות.
כל פרויקט הוא שונה. במודול הזה נסביר על גישה יעילה ורב-שכבתית לבניית צינור עיבוד נתונים להערכה.
כדי ליצור את פייפליין ההערכות, צריך:
- כלי לניהול הבודקים
- אסטרטגיה לטיפול בכמה קריאות ל-API ולפתרון של כשלים פוטנציאליים
- פורמט פלט סטנדרטי
- ממשק דיווח
תיאום של קריאות ל-API

יוצרים פונקציה ראשית לניהול של כלים להערכה שמבוססים על כללים ועל מודלים גדולים של שפה.
בודקים את evalAll() בקוד לדוגמה.
מרכזים את ההגדרה של שופט ה-LLM (הוראות המערכת, לוגיקת הפלט המובנה וניסיונות חוזרים) בפונקציית כלי אחת שאפשר לעשות בה שימוש חוזר בכל כלי ההערכה. בודקים את evalWithLLM() בקוד לדוגמה.
טיפול בעומסי יתר ובכשלים של ממשקי API של מודלים
לפעמים יש עומס יתר על ממשקי API של מודלים או שהם מפסיקים לפעול בגלל חוסר פעילות. אם הקריאה ל-API נכשלת, מפעילים ניסיון חוזר אוטומטי. אחרי שמסיימים את כל הניסיונות, מדווחים על ERROR. דיווח על
הערכה FAIL משפיע על התוצאות.
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
כשמריצים הערכות, אפשר לבחור בין האפשרויות הבאות:
- כדאי לבצע את קריאות ה-API במקביל כדי שפסק זמן בהערכה אחת לא יגרום לקריסה של האחרות. בהתאם לתרחיש השימוש ולמודל השופט, השיטה הזו יכולה לצמצם את ההזיות כי השופט מתמקד במשימה אחת.
- מבצעים קריאה אחת באצווה. כך נוצרת נקודת כשל בודדת, למשל אם המודל חורג ממגבלת הטוקנים שלו.
הכנה לכמה איטרציות
מכיוון שמודלים גדולים של שפה הם לא דטרמיניסטיים, הפלט של האפליקציה משתנה.
כדי לבדוק את זה בצורה מדויקת ולוודא שהפלט עומד ברף האיכות שלכם:
- ליצור כמה פלטים (בדרך כלל 5 עד 10) לכל קלט של תרחיש בדיקה.
- צריך להעריך כל פלט בנפרד.
- בודקים את התוצאות הכוללות בכל האיטרציות.
חשוב למצוא איזון פרגמטי: ככל שמבצעים יותר איטרציות, כך גדלה הוודאות לגבי הרגרסיה, אבל ככל שמבצעים פחות איטרציות, כך הביצוע מהיר יותר ומשתלב בצורה חלקה בצינור הבדיקות הרציף.
הגדרת הפלט של צינור עיבוד הנתונים להערכה
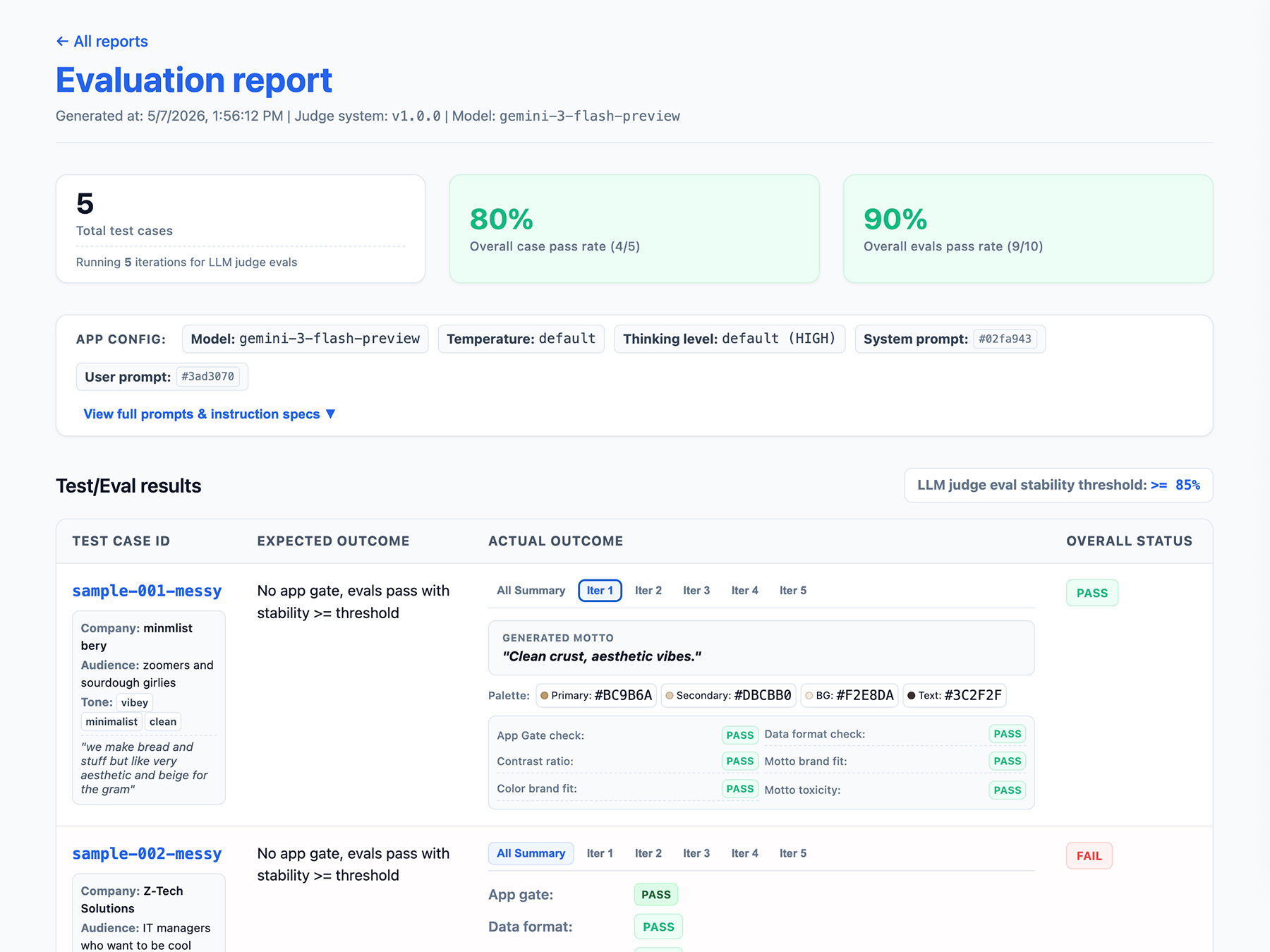
תוצאות הבדיקה צריכות לכלול את הפרטים הבאים:
- שיעור היציבות, לדוגמה: עבר 8 מתוך 10 פעמים ← 80% יציבות. הגדרת סף למדידה של מוכנות תכונה להפקה.
- הגדרת האפליקציה. זה כולל הוראות למערכת, הנחיה למשתמש ופרמטרים של מודל LLM כמו רמת אקראיות או רמת חשיבה. המידע הזה נחוץ לפתרון בעיות שקשורות לירידה בציון של הערכות. ההנחיות יכולות להיות מחרוזות ארוכות עם שינויים קלים, ולכן כדאי להוסיף מספר גרסה להנחיות ולשמור את הגיבוב שלהן כדי לעקוב אחריהן.
- ההגדרה של השופט או מספר הגרסה. הנתון הזה נחוץ למקרה שהניקוד משתנה באופן משמעותי אחרי עדכון של שופט.
דוגמה לאובייקט JSON של EvalResponse ל-ThemeBuilder evals:
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
הטמעה של ממשק דיווח
אפשר להפיק את התוצאות כדוח HTML או כממשק משתמש נקי באינטרנט כדי לנתח, לשתף, להשוות ולנפות באגים בתוצאות לאורך זמן.

עכשיו מריצים את ההערכות.