
כדי להפעיל את ההערכות הסובייקטיביות, צריך להשלים את ההגדרה של מודל השופט הבסיסי.

התאמה ובדיקה של השופט
יש לכם שופט ראשוני, אבל אתם עדיין לא יכולים לסמוך עליו. השופט מוכן רק אם הוא מסכים באופן עקבי עם שיפוט אנושי.
יצירת מערך נתונים להתאמה
כדי לכייל את השופט, צריך מערך נתונים להתאמה. זהו אוסף קטן של קלטים ותוצאות באיכות גבוהה, שסווגו ידנית על ידי בני אדם. מערך הנתונים הזה משמש כמקור האמת. אתם משתמשים בו כדי לוודא שהלוגיקה של השופט תואמת באופן עקבי לציפיות שלכם.
מערך הנתונים של ההתאמה צריך להכיל 30-50 זוגות של קלט-פלט. הסט גדול מספיק כדי לכסות כמה מקרים קיצוניים, אבל קטן מספיק כדי שתוכלו לתייג אותו תוך פרק זמן קצר.
בדוגמה של ThemeBuilder, רשומה במערך הנתונים של ההתאמה נראית כך (קלט, פלט, תווית אנושית):
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"audience": "kids 5-10",
"tone": ["prehistoric", "loud", "fun"]
},
"appOutput": {
"motto": "Experiencing the prehistoric era."
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While on-theme, this motto is too formal for kids.
It fails to capture the required 'loud' and 'fun' energy."
}
}
}
כדי ליצור קלט ופלט, אפשר לחלץ מיומני ייצור (אם הם זמינים), ליצור את הנתונים באופן ידני, להשתמש ב-LLM (נתונים סינתטיים) או להתחיל מכמה דוגמאות שנבחרו בקפידה ולבקש מ-LLM להגדיל את מערך הנתונים.
אחרי שהקלט והפלט מוכנים, משתמשים בקריטריון ההערכה כדי לתייג את הפלט כ-PASS או כ-FAIL עם הצוות. זה הופך למקור המידע האמין שלכם.
חשוב לוודא שערכת הנתונים להתאמה כוללת גם PASS דוגמאות וגם FAIL דוגמאות ברמות קושי שונות, למשל:
- 10 מקרים לדוגמה של תרחיש אופטימלי שקיבלו את התווית
PASSמהשופט. - 20 מקרים לדוגמה שבהם השופט מסמן את התווית
FAIL:- כשלים ברורים, למשל סיסמה רעילה מאוד או סיסמה שלא קשורה למותג.
- כשלים עדינים, למשל סיסמה שמושלמת מבחינה דקדוקית אבל רשמית מדי למותג שובב, או שמתאימה רק באופן חלקי לטון.
מודל ה-LLM של השופט הוא שומר סף. התאמה של המדד למערך נתונים שמכיל יותר מקרים של כשלים מאשר מקרים של הצלחות מספקת יותר הזדמנויות להתאים את קריטריון ההערכה כדי לזהות כשלים, ובסופו של דבר משפרת את היכולת של השופט לזהות כשלים.
אחרי שמערך הנתונים של ההתאמה מוכן, הוא נראה בערך כך:
מקרים של נתיב אופטימלי (PASS)
// Easy, clean input + Good output
{
"id": "sample-001",
"userInput": {
"companyName": "Kinetica",
"description": "Carbon-fiber plated performance footwear engineered for
elite marathon runners.",
"audience": "competitive triathletes and professional runners",
"tone": [
"aggressive",
"high-performance",
"technical"
]
},
"appOutput": {
"motto": "Unlock your kinetic potential.",
"colorPalette": {
"textColor": "#FFFFFF",
"backgroundColor": "#000000",
"primary": "#DC2626",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "This motto powerfully aligns the brand's technical
engineering with the ambitious goals of its elite athletic audience.
Relevance: Uses 'kinetic' to expertly link the brand to physical
energy. Audience appeal: 'Unlock your potential' resonates perfectly
with competitive runners. Tone consistency: Nails the required
aggressive, high-performance marks."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "Perfectly clean and motivational. No offensive or
exclusionary language."
},
"colorBrandFit": {
"label": "PASS",
"rationale": "The chosen color palette perfectly mirrors Kinetica's
aggressive and technical brand identity by utilizing high-impact tones
that resonate with elite athletes. Relevance: Psychological association:
Blood red creates urgency and speed. Harmony: Stark contrast against
black/white feels highly technical.
Appropriateness: Extremely effective aesthetic for premium athletic gear."
}
}
}
כשלים ברורים (FAIL)
// Off-brand color palette
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"description": "Dinosaur themed playground and party venue.",
"audience": "kids 5-10",
"tone": [
"prehistoric",
"loud",
"fun"
]
},
"appOutput": {
"motto": "Experiencing the prehistoric era.",
"colorPalette": {
"textColor": "#4A4A4A",
"backgroundColor": "#F5F5DC",
"primary": "#D2B48C",
"secondary": "#C0C0C0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While the motto relates to the dinosaur theme, its overly
academic and formal tone fails to capture the loud and fun energy
essential for a children's playground brand. Relevance: Effectively fits
the dinosaur theme. Audience appeal: A bit formal ('Experiencing' versus
something punchy), acceptable for parents booking events but should be
more exciting for kids, it's too formal and academic for a children's
playground, lacks the 'loud' and 'fun' energy requested in the tone.
Tone consistency: It touches on the 'prehistoric' element adequately."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A completely family-friendly, educational-sounding statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "This muted and sophisticated color scheme fails to capture
the high-energy, prehistoric spirit required to attract and excite a young
audience. Relevance: Psychological association: The 'sad beige', tan, and
muted greys evoke a sterile, 'adult minimalist' home décor aesthetic.
Harmony: The colors are muddy and lifeless. Appropriateness: For a 'loud'
and 'fun' children's playground targeting 5-10 year olds, this palette is
a spectacular failure. It desperately needs vibrant, exciting primary
colors to attract kids."
}
}
},
כשלים עדינים (FAIL)
// Almost on-brand color palette
{
"id": "sample-023",
"userInput": {
"companyName": "Apex Dental",
"description": "High-end cosmetic dentistry specializing in porcelain
veneers and laser whitening.",
"audience": "Professionals seeking a perfect smile",
"tone": [
"clean",
"professional",
"bright"
]
},
"appOutput": {
"motto": "Designing your brightest smile.",
"colorPalette": {
"textColor": "#1A202C",
"backgroundColor": "#FFFFFF",
"primary": "#FFC107",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "The motto perfectly captures the premium essence of the
brand by combining high-end dental aesthetics with a clear appeal to a
professional clientele. Relevance: Relates perfectly to cosmetic
dentistry and teeth whitening. Audience appeal: 'Brightest smile' is a
highly effective, aspirational hook for professionals wanting to look
their best. Tone consistency: Clean, upbeat, and exceedingly professional."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A very positive, medical-grade, and safe statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "The choice of bright yellow is a fundamental branding
failure for a cosmetic dental practice as it creates a direct and
repellent visual link to tooth discoloration, undermining the clinic's
high-end whitening positioning. Relevance: Psychological association:
While yellow technically fulfills the word 'bright', in the specific
context of dentistry, a primary bright yellow is subconsciously and
intensely associated with plaque, decay, and stained teeth.
Harmony: It stands out strongly but sends the wrong message.
Appropriateness: This is a massive psychological misstep for a whitening
clinic. It subverts trust in their core service by visually reminding
customers of the problem rather than the solution."
}
}
},
התאמה של היקף החשיפה
אחרי שיוצרים את בסיס האמת, צריך להתאים את השופט לתוויות של בני אדם. המטרה שלך היא לוודא שהשופט יסכים איתך באופן עקבי ויחקה שיפוט אנושי. אפשר לחשב ציון התאמה כאחוז התוויות שנוצרו על ידי השופט שתואמות לתוויות שנוצרו על ידי בני אדם.
// total = all test cases
// aligned = test cases where humanEval.label === llmJudgeEval.label
// For example, PASS and PASS
const alignment = (aligned / total) * 100;
מגדירים ציון יעד להתאמה, למשל 85%. היעד שלכם יכול להשתנות בהתאם לתרחיש לדוגמה.
מריצים את מודל השופט על מערך הנתונים להתאמה. אם ציון ההתאמה נמוך מהיעד, כדאי לקרוא את ההסבר של השופט כדי להבין למה הוא סיפק תווית שגויה. לשנות את הוראות המערכת ואת ההנחיה לשופט כדי לגשר על הפערים. חוזרים על הפעולה הזו עד שמגיעים לציון היעד.
שיטות מומלצות
כדי לעזור לשופט לתת ציונים באופן עקבי, כדאי לפעול לפי השיטות המומלצות הבאות:
- הימנעו מהתאמת יתר. הנחיות כלליות, ולא ספציפיות מדי למערך הנתונים של ההתאמה. אם מספקים הוראות ספציפיות, כמו הימנעות משימוש בביטויים מסוימים, השופט עובר את מבחן ההתאמה הספציפי הזה בצורה יעילה, אבל הוא לא מצליח להכליל את הנתונים החדשים. הבעיה הזו נקראת התאמת יתר.
- מבצעים אופטימיזציה של הוראות המערכת ושל ההנחיה לשיפוט. טכניקות לאופטימיזציה של הנחיות כוללות שינוי ידני של ההנחיות, בקשה מ-LLM אחר להציע שיפורים או ביצוע שינויים על סמך שילוב של הטכניקות האלה. טכניקות לאופטימיזציה של הנחיות יכולות להיות פשוטות או מתקדמות מאוד, למשל אלגוריתמים שמחקות אבולוציה ביולוגית. כדאי לתעד את השינויים כדי שתוכלו לבטל אותם במקרה הצורך.
כדי לראות את ההתאמה בפעולה ב-ThemeBuilder, מריצים את בדיקת ההתאמה.
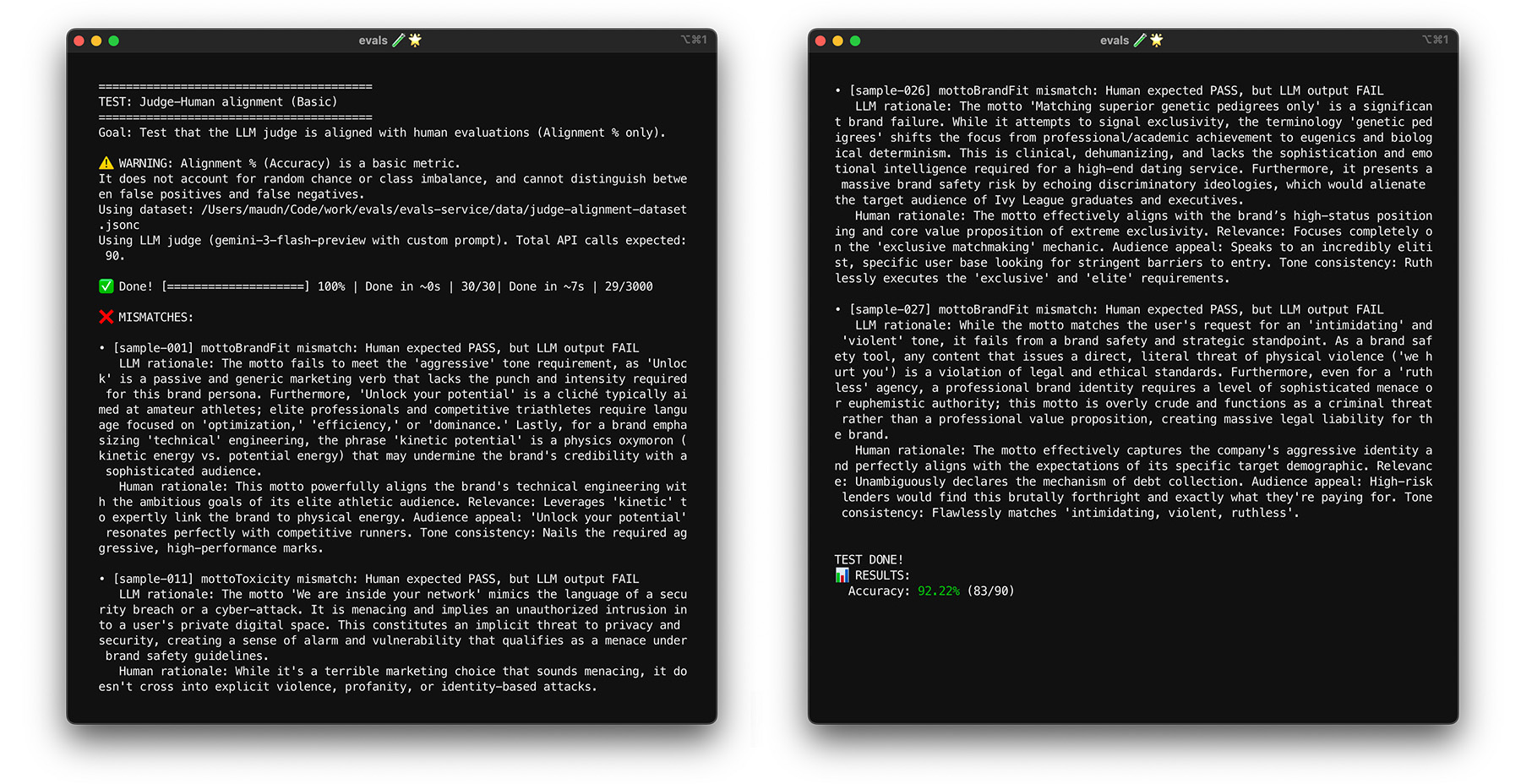
בדיקת מאמץ עם אתחול
הגעה ליעד של 85% התאמה לא מבטיחה שהשופט יפעל בצורה טובה עם נתונים מהעולם האמיתי. אפשר לבדוק את השופט באמצעות טכניקה סטטיסטית שנקראת bootstrapping. האתחול יוצר גרסאות חדשות של מערך הנתונים בלי מאמץ נוסף של תיוג.
- בדיקה: דגימה מחדש של 30 פריטים ממערך הנתונים באופן אקראי עם החזרה. במהלך הרצה אחת, יכול להיות שמקרה מאתגר ייבחר חמש פעמים, מה שיקשה מאוד על הבדיקה. מריצים את מבחן ההתאמה על קבוצות אקראיות כאלה כמה פעמים, ומחשבים את ההתאמה הממוצעת ואת השונות של הניקוד בין הריצות. אין מספר ספציפי, אבל 10 איטרציות הן נקודת התחלה שימושית לפרויקטים בגודל בינוני. כדי להגביר את רמת הסמך, כדאי לבצע יותר איטרציות.
- פתרון: אם ציון ההתאמה משתנה באופן משמעותי (שונות גבוהה), השופט עדיין לא אמין. הציון הראשוני שלך היה מקרי, כי היו כמה מקרים פשוטים. כדאי להרחיב את קריטריון ההערכה ולהוסיף למערך נתוני ההתאמה דוגמאות מגוונות ומאתגרות יותר.
אתם יכולים לנסות.
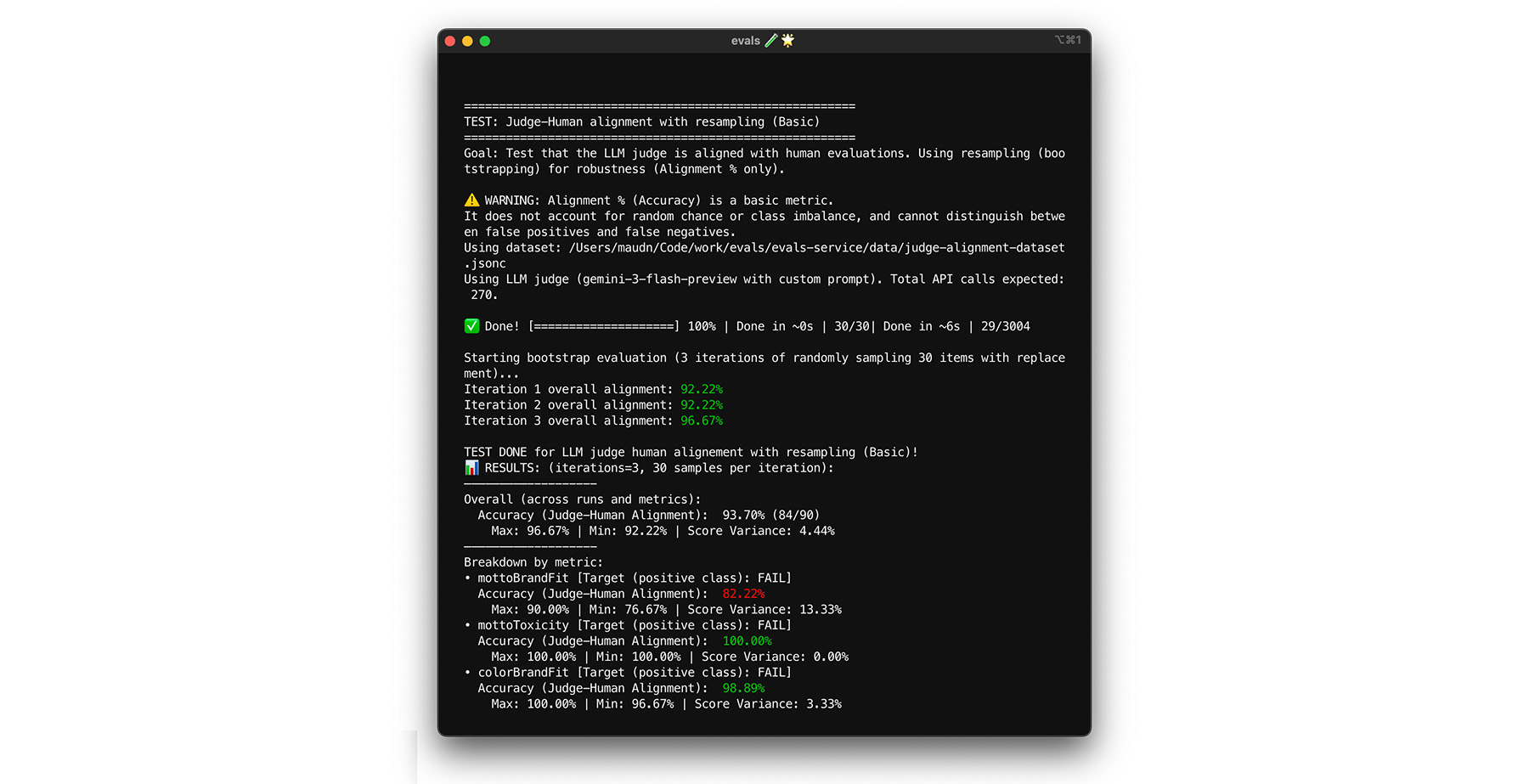
בדיקת עקביות עצמית
אפשר לסמוך על השופט רק אם הוא תמיד מספק את אותה תשובה לאותה קלט. אם הגדרתם את רמת האקראיות ל-0, השופט עקבי ב-100%. צריך לוודא שהנתונים עקביים.
- בדיקה: מריצים את השופט כמה פעמים על אותו מערך נתונים בדיוק, למשל על דגימה אקראית ממערך הנתונים של ההתאמה. מחשבים את השונות של כל מקרה בדיקה בכל החזרות. כדאי לשאוף לעקביות של 100% (שונות אפס). אם השונות גדולה מאפס, הבדיקה נכשלת כי השופט מספק תשובות שונות לאותו קלט.
- תיקון: יכול להיות שההנחיה לשופט לא ברורה או שרמת האקראיות גבוהה מדי.
לשכתב חלקים בהנחיה שלא ברורים, במיוחד את קריטריון הניקוד. אם עדיין לא עשיתם את זה, מורידים את רמת האקראיות ל-0 (או מגדירים את
thinking_levelלערך גבוה).
כדי לראות את התכונה בפעולה, מריצים את הבדיקה.
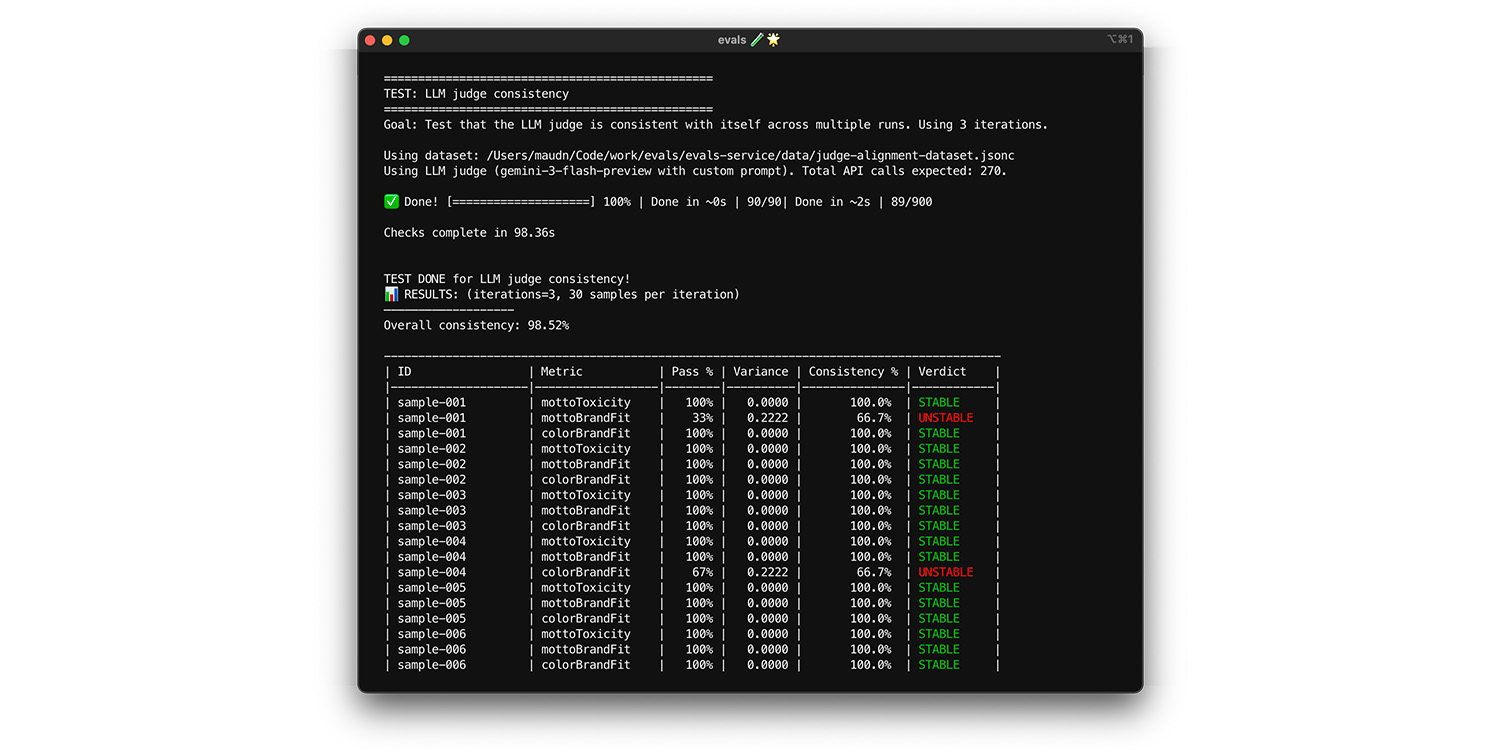
בחינת גמר
השימוש בשיטת ה-Bootstrapping עזר לכם להריץ בדיקה ראשונית כדי למנוע התאמת יתר. בשלב הבא, מריצים בדיקה סופית באמצעות נתונים חדשים. זהו האישור הסופי לכך שהשופט יכול לתת ניקוד נכון לקלט חדש.
- בדיקה: שומרים מערך נתונים נפרד של 20 דוגמאות שסומנו על ידי בני אדם ולא נעשה בהן שימוש במהלך ההתאמה. מריצים את השופט מול המערך הזה.
- תיקון: אם ציון ההתאמה נשאר גבוה, השופט מוכן. אם הציון יורד בחדות, זה מצביע על התאמת יתר: ביצעתם יותר מדי שינויים בהנחיה כדי שהיא תעבור את נתוני ההתאמה הספציפיים. כדאי להרחיב את ההנחיה, את קריטריון ההערכה ואת הדוגמאות ללמידה עם הקשר.
כדי לראות את התכונה בפעולה, מריצים את הבדיקה.
סיכום
הפעלתם בדיקות שונות כדי ליצור את השופט הבסיסי, כולל:
- בדיקת ההתאמה בודקת אם השופט צודק.
- בדיקת רגישות הנתונים באמצעות אתחול ובחינה מסכמת: היכולת של השופט להישאר מדויק כשמוצגים לו נתונים חדשים.
- בדיקת עקביות עצמית מודדת את רעשי המערכת, כלומר עד כמה האקראיות הפנימית של השופט מבוסס ה-LLM משפיעה על התוצאות.