Suggerimenti di ingegneria applicata per creare la pipeline di test dell'AI.

Hai progettato le rubriche, scritto le valutazioni basate su regole e allineato il modello di giudice. Ora è il momento di collegare tutto in una pipeline di test automatizzata e continua.
Ogni progetto è diverso. Questo modulo descrive un approccio efficace e stratificato per creare la pipeline di valutazione.
Per creare la pipeline di valutazione, devi disporre di quanto segue:
- Un orchestratore per i tuoi valutatori
- Una strategia per gestire più chiamate API e risolvere potenziali errori
- Un formato di output standardizzato
- Un'interfaccia di reporting
Orchestrare le chiamate API

Crea una funzione principale per orchestrare i valutatori basati su regole e LLM.
Controlla evalAll() nel
codice di esempio.
Centralizza la configurazione della valutazione LLM (istruzioni di sistema, logica di output strutturato e tentativi) in un'unica funzione di utilità riutilizzabile in tutti i valutatori. Controlla evalWithLLM() nel
codice di esempio.
Gestire sovraccarichi ed errori dell'API Model
A volte le API del modello si sovraccaricano o scadono. Se la chiamata API non va a buon fine, attiva un
nuovo tentativo automatico. Una volta esauriti i tentativi, segnala un ERROR. La segnalazione di un
'eval FAIL distorce i risultati.
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
Quando esegui le valutazioni, scegli tra le seguenti opzioni:
- Esegui le chiamate API in parallelo in modo che un timeout su una valutazione non causi l'arresto anomalo delle altre. A seconda del caso d'uso e del modello di valutazione, questo può ridurre le allucinazioni perché il giudice si concentra su un'attività.
- Effettua una singola chiamata batch. In questo modo viene creato un unico punto di errore, ad esempio se il modello supera il limite di token.
Prepararsi a più iterazioni
Poiché i modelli LLM non sono deterministici, l'output dell'applicazione varia.
Per testare questo aspetto in modo accurato e avere la certezza che l'output soddisfi i tuoi standard di qualità:
- Genera più output (in genere da 5 a 10) per ogni input di test case.
- Valuta ogni output separatamente.
- Esamina i risultati complessivi nelle varie iterazioni.
Trova un equilibrio pragmatico: un maggior numero di iterazioni aumenta la certezza della regressione, ma un numero inferiore di iterazioni mantiene l'esecuzione abbastanza veloce da integrarsi perfettamente nella tua pipeline di test continui.
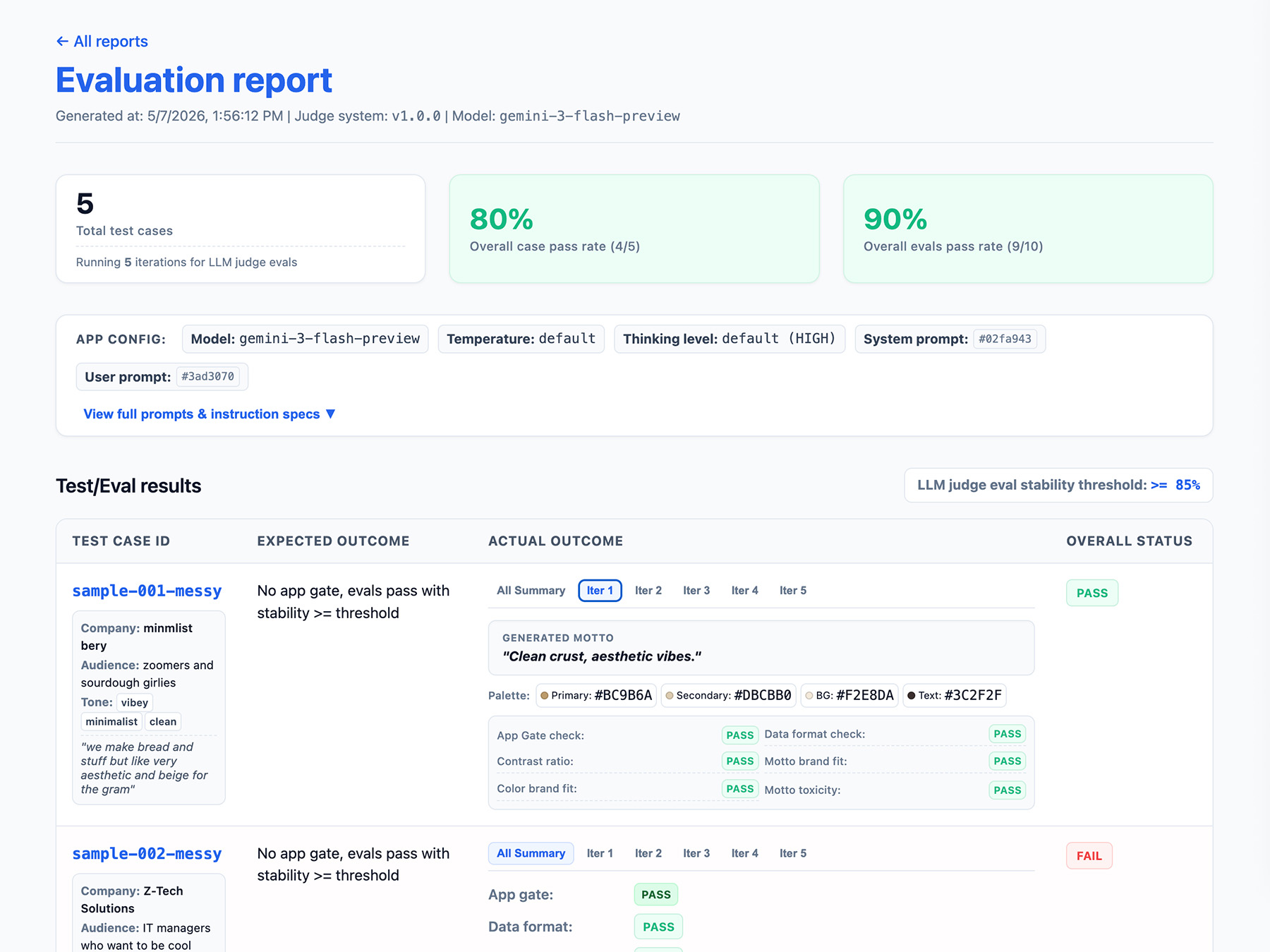
Definisci l'output della pipeline di valutazione
Includi quanto segue nei risultati della valutazione:
- Un tasso di stabilità, ad esempio Superato 8/10 volte → 80% di stabilità. Imposta una soglia per misurare quando una funzionalità è pronta per la produzione.
- La configurazione dell'applicazione. Ciò include le istruzioni di sistema, il prompt dell'utente e i parametri LLM, come la temperatura o il livello di pensiero. Hai bisogno di queste informazioni per risolvere i problemi di regressione del punteggio delle valutazioni. I prompt possono essere stringhe lunghe con leggere variazioni, quindi aggiungi un numero di versione ai prompt e memorizza un hash per tenerne traccia.
- La tua configurazione del giudice o un numero di versione. Ti servirà nel caso in cui il tuo punteggio vari in modo significativo dopo un aggiornamento del giudice.
Ecco un esempio di oggetto JSON EvalResponse per le valutazioni di ThemeBuilder:
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
Implementare un'interfaccia per i report
Visualizza i risultati in un report HTML o in un'interfaccia utente web pulita per analizzarli, condividerli, confrontarli ed eseguirne il debug nel tempo.