
Wskazówki dotyczące inżynierii stosowanej, które pomogą Ci zbudować potok testowania AI.

Zaprojektowano rubryki, napisano oceny oparte na regułach i dostosowano model oceniający. Teraz połączmy to wszystko w automatyczny potok testów ciągłych.
Każdy projekt jest inny. W tym module przedstawiamy skuteczne, warstwowe podejście do tworzenia potoku oceny.
Aby utworzyć potok oceny, potrzebujesz:
- Orchestrator dla oceniających
- Strategia obsługi wielu wywołań interfejsu API i rozwiązywania potencjalnych problemów.
- standardowy format wyjściowy,
- interfejs raportowania,
Orkiestracja wywołań interfejsu API

Utwórz funkcję główną, która będzie koordynować działania oceniających opartych na regułach i oceniających modeli LLM.
Przyjrzyj się evalAll() w przykładowym kodzie.
Scentralizuj konfigurację oceniającego modelu LLM (instrukcje systemowe, logikę strukturalnych danych wyjściowych i ponowne próby) w jednej funkcji użytkowej, której możesz używać w różnych oceniających. Przyjrzyj się evalWithLLM() w przykładowym kodzie.
Obsługa przeciążeń i awarii interfejsu API modelu
Interfejsy API modeli czasami są przeciążone lub przekraczają limit czasu. Jeśli wywołanie interfejsu API się nie powiedzie, automatycznie ponów próbę. Gdy wyczerpiesz liczbę ponownych prób, zgłoś ERROR. Zgłaszanie oceny FAIL zniekształca wyniki.
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
Podczas przeprowadzania ocen możesz wybrać jedną z tych opcji:
- Wykonuj wywołania interfejsu API równolegle, aby przekroczenie limitu czasu w przypadku jednego wywołania nie powodowało awarii pozostałych. W zależności od przypadku użycia i modelu oceniającego może to ograniczyć halucynacje, ponieważ model oceniający skupia się na jednym zadaniu.
- Wykonaj pojedyncze wywołanie zbiorcze. Powoduje to powstanie jednego punktu awarii, np. gdy model przekroczy limit tokenów.
Przygotuj się na wiele iteracji
Modele LLM nie są deterministyczne, więc dane wyjściowe aplikacji mogą się różnić.
Aby dokładnie przetestować tę funkcję i mieć pewność, że dane wyjściowe spełniają Twoje wymagania jakościowe:
- Generowanie wielu wyników (zwykle od 5 do 10) dla każdego pojedynczego testu.
- Oceń każdą odpowiedź osobno.
- Sprawdź ogólne wyniki w poszczególnych iteracjach.
Znajdź pragmatyczną równowagę: większa liczba iteracji zwiększa pewność regresji, ale mniejsza liczba iteracji zapewnia wystarczającą szybkość wykonania, aby bezproblemowo wpasować się w potok testów ciągłych.
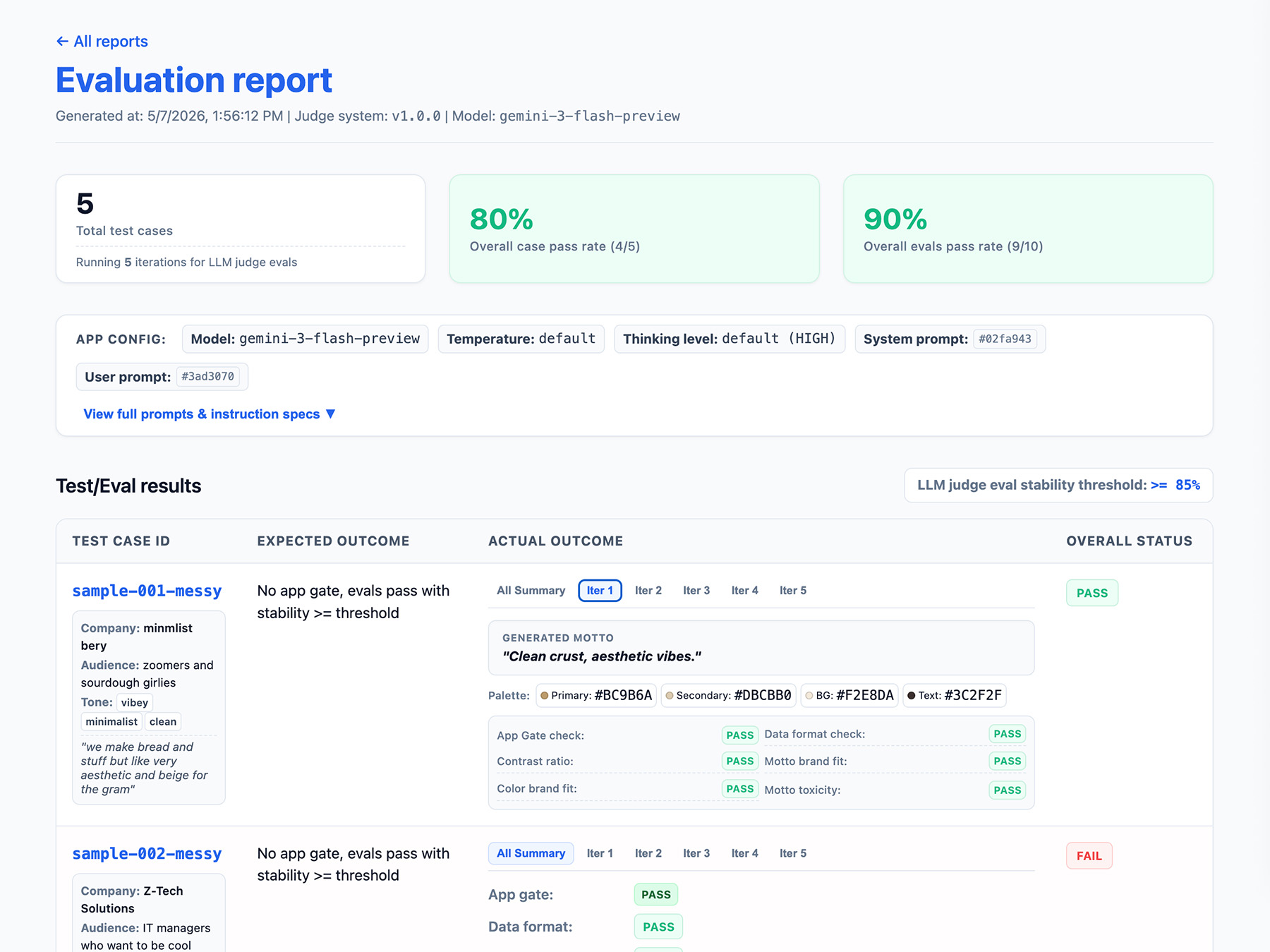
Określanie danych wyjściowych potoku oceny
W wynikach oceny uwzględnij:
- Współczynnik stabilności, np. test został zaliczony 8 razy na 10 → 80% stabilności. Ustaw próg, aby określić, kiedy funkcja jest gotowa do wdrożenia w środowisku produkcyjnym.
- Konfiguracja aplikacji. Obejmuje to instrukcje systemowe, prompt użytkownika i parametry LLM, takie jak temperatura czy poziom myślenia. Te informacje są potrzebne do rozwiązywania problemów z regresją wyników oceny. Prompty mogą być długimi ciągami znaków z niewielkimi różnicami, dlatego dodaj do nich numer wersji i zapisz ich skrót, aby je śledzić.
- Konfiguracja oceniającego lub numer wersji. Jest to potrzebne, jeśli po aktualizacji oceny przez sędziego Twój wynik znacznie się zmieni.
Oto przykład obiektu JSON EvalResponse na potrzeby ocen ThemeBuilder:
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
Wdrażanie interfejsu raportowania
Wyświetlaj wyniki w raporcie HTML lub przejrzystym interfejsie internetowym, aby je analizować, udostępniać, porównywać i debugować na przestrzeni czasu.

Teraz przeprowadź ocenę.