
Dicas de engenharia aplicada para criar seu pipeline de testes de IA.

Você já criou suas rubricas, escreveu suas avaliações baseadas em regras e alinhou seu modelo de juiz. Agora é hora de juntar tudo isso em um pipeline de testes automatizado e contínuo.
Cada projeto é diferente. Este módulo descreve uma abordagem eficaz e em camadas para criar seu pipeline de avaliação.
Para criar seu pipeline de avaliações, você precisa do seguinte:
- Um orquestrador para seus avaliadores
- Uma estratégia para lidar com várias chamadas de API e resolver possíveis falhas
- Um formato de saída padronizado
- Uma interface de relatórios
Orquestrar chamadas de API

Crie uma função principal para orquestrar seus avaliadores de juízes baseados em regras e LLM.
Analise evalAll() no
código de exemplo.
Centralize a configuração do juiz do LLM (instruções do sistema, lógica de saída estruturada e novas tentativas) em uma única função utilitária que pode ser reutilizada em seus avaliadores. Analise evalWithLLM() no
código de exemplo.
Como lidar com sobrecargas e falhas da API do modelo
Às vezes, as APIs do modelo ficam sobrecarregadas ou atingem o tempo limite. Se a chamada de API falhar, acione uma nova tentativa automática. Quando você ficar sem novas tentativas, informe um ERROR. Informar uma avaliação FAIL distorce seus resultados.
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
Ao executar avaliações, escolha entre as seguintes opções:
- Faça chamadas de API em paralelo para que um tempo limite em uma avaliação não falhe nas outras. Dependendo do seu caso de uso e do modelo de juiz, isso pode reduzir as alucinações porque o juiz se concentra em uma tarefa.
- Faça uma única chamada em lote. Isso cria um único ponto de falha, por exemplo, se o modelo exceder o limite de tokens.
Preparar para várias iterações
Como os LLMs não são determinísticos, a saída do aplicativo varia.
Para testar isso com precisão e criar confiança de que a saída atende à sua barra de qualidade:
- Gere várias saídas (normalmente de 5 a 10) para cada entrada de caso de teste.
- Avalie cada saída separadamente.
- Examine os resultados gerais em todas as iterações.
Encontre um equilíbrio pragmático: mais iterações aumentam a certeza de regressão, mas menos iterações mantêm a execução rápida o suficiente para se ajustar perfeitamente ao pipeline de testes contínuos.
Definir a saída do pipeline de avaliação
Inclua o seguinte nos resultados da avaliação:
- Uma taxa de estabilidade, por exemplo, aprovada 8/10 vezes → 80% estável. Defina um limite para medir quando um recurso está pronto para produção.
- A configuração do aplicativo. Isso inclui instruções do sistema, comandos do usuário e parâmetros de LLM, como a temperatura ou o nível de pensamento. Você precisa dessas informações para solucionar problemas de regressões de pontuação de avaliações. Os comandos podem ser strings longas com pequenas variações. Por isso, adicione um número de versão aos comandos e armazene um hash deles para acompanhar.
- A configuração do juiz ou um número de versão. Você precisa disso caso sua pontuação varie muito após uma atualização do juiz.
Confira um exemplo de objeto JSON EvalResponse para as avaliações do ThemeBuilder:
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
Implementar uma interface de relatórios
Produza seus resultados em um relatório HTML ou em uma interface da Web limpa para analisar, compartilhar, comparar e depurar os resultados ao longo do tempo.
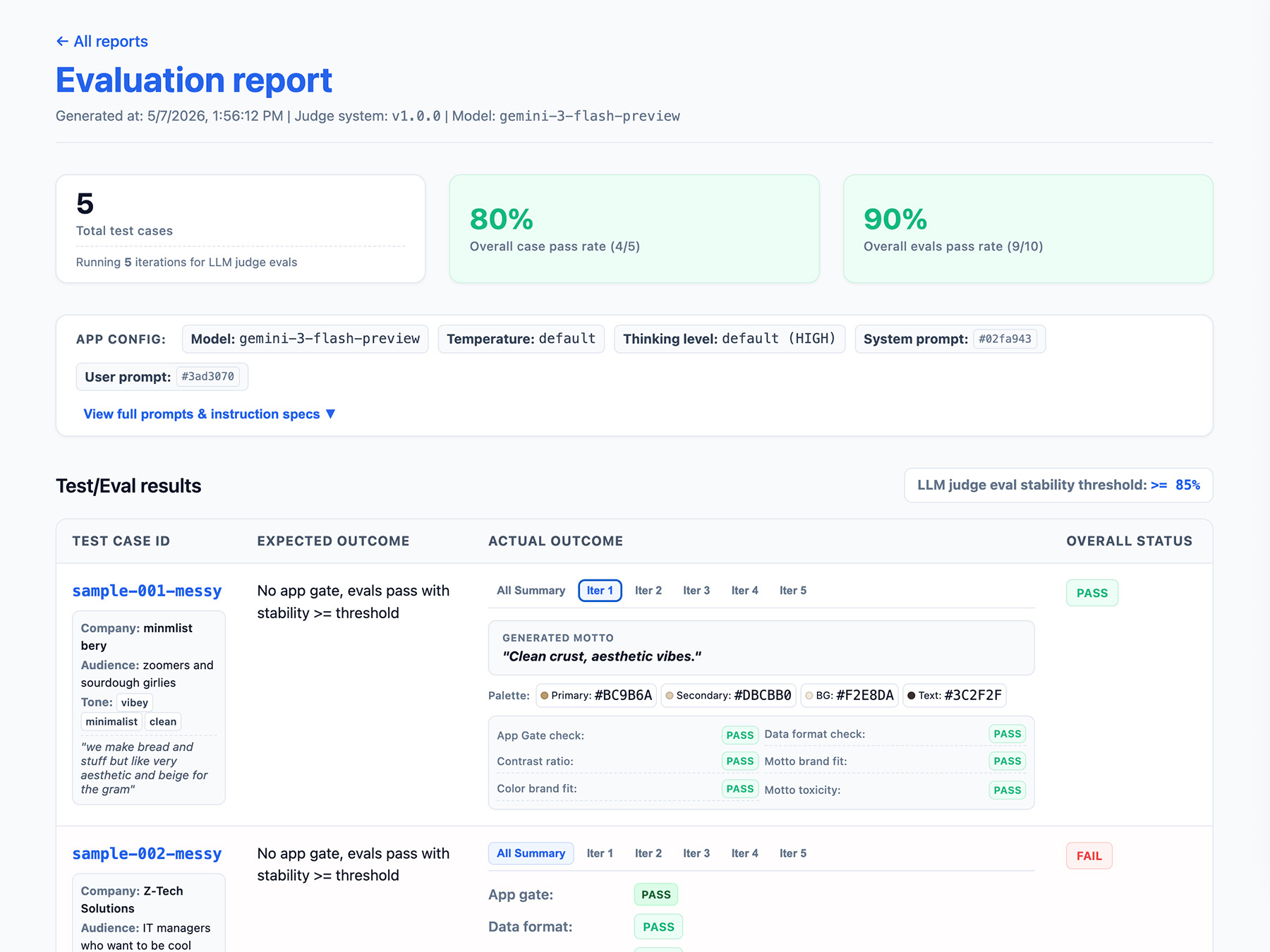

Agora, execute suas avaliações.