
Conclua a configuração do modelo de juiz básico para começar a fazer suas avaliações subjetivas.

Alinhar e testar o juiz
Você tem um juiz inicial, mas ainda não pode confiar nele. Seu juiz só estará pronto quando concordar consistentemente com o julgamento humano.
Criar um conjunto de dados de alinhamento
Para calibrar seu avaliador, você precisa de um conjunto de dados de alinhamento. É uma pequena coleção de entradas e saídas de alta qualidade que foram classificadas manualmente por humanos. Esse conjunto de dados funciona como sua informação empírica. Use-o para<br>verificar se a lógica do juiz está alinhada às suas expectativas.
O conjunto de dados de ajuste precisa ter 30 a 50 pares de entrada e saída. O conjunto é grande o suficiente para abranger alguns casos extremos, mas pequeno o suficiente para ser rotulado em um curto período.
No exemplo do ThemeBuilder, uma entrada no conjunto de dados de alinhamento é assim: (entrada, saída, rótulo humano):
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"audience": "kids 5-10",
"tone": ["prehistoric", "loud", "fun"]
},
"appOutput": {
"motto": "Experiencing the prehistoric era."
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While on-theme, this motto is too formal for kids.
It fails to capture the required 'loud' and 'fun' energy."
}
}
}
Para gerar entradas e saídas, você pode extrair de registros de produção (se disponíveis), criar os dados manualmente, usar um LLM (dados sintéticos) ou começar com algumas amostras escolhidas a dedo e pedir que um LLM aumente seu conjunto de dados.
Quando as entradas e saídas estiverem prontas, use a rubrica para rotular as saídas como
PASS ou FAIL com sua equipe. Essa é sua informação empírica.
Verifique se o conjunto de dados de alinhamento inclui exemplos PASS e FAIL de diferentes níveis de dificuldade, por exemplo:
- 10 exemplos de casos de caminho feliz que seu avaliador rotula como
PASS. - 20 exemplos de casos que seu juiz rotula como
FAIL:- Falhas óbvias, por exemplo, um lema altamente tóxico ou completamente fora da marca.
- Falhas sutis, por exemplo, um lema gramaticalmente perfeito, mas um pouco formal demais para uma marca divertida ou que só se encaixa parcialmente no tom.
Seu LLM Judge é um guardião. Alinhar em um conjunto de dados que contém mais falhas do que casos aprovados oferece mais oportunidades de ajustar a rubrica para detectar falhas e, por fim, melhora a capacidade do avaliador de detectar falhas.
Depois que o conjunto de dados de ajuste estiver pronto, ele vai ficar assim:
Casos de cenário ideal (APROVADO)
// Easy, clean input + Good output
{
"id": "sample-001",
"userInput": {
"companyName": "Kinetica",
"description": "Carbon-fiber plated performance footwear engineered for
elite marathon runners.",
"audience": "competitive triathletes and professional runners",
"tone": [
"aggressive",
"high-performance",
"technical"
]
},
"appOutput": {
"motto": "Unlock your kinetic potential.",
"colorPalette": {
"textColor": "#FFFFFF",
"backgroundColor": "#000000",
"primary": "#DC2626",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "This motto powerfully aligns the brand's technical
engineering with the ambitious goals of its elite athletic audience.
Relevance: Uses 'kinetic' to expertly link the brand to physical
energy. Audience appeal: 'Unlock your potential' resonates perfectly
with competitive runners. Tone consistency: Nails the required
aggressive, high-performance marks."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "Perfectly clean and motivational. No offensive or
exclusionary language."
},
"colorBrandFit": {
"label": "PASS",
"rationale": "The chosen color palette perfectly mirrors Kinetica's
aggressive and technical brand identity by utilizing high-impact tones
that resonate with elite athletes. Relevance: Psychological association:
Blood red creates urgency and speed. Harmony: Stark contrast against
black/white feels highly technical.
Appropriateness: Extremely effective aesthetic for premium athletic gear."
}
}
}
Falhas óbvias (FAIL)
// Off-brand color palette
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"description": "Dinosaur themed playground and party venue.",
"audience": "kids 5-10",
"tone": [
"prehistoric",
"loud",
"fun"
]
},
"appOutput": {
"motto": "Experiencing the prehistoric era.",
"colorPalette": {
"textColor": "#4A4A4A",
"backgroundColor": "#F5F5DC",
"primary": "#D2B48C",
"secondary": "#C0C0C0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While the motto relates to the dinosaur theme, its overly
academic and formal tone fails to capture the loud and fun energy
essential for a children's playground brand. Relevance: Effectively fits
the dinosaur theme. Audience appeal: A bit formal ('Experiencing' versus
something punchy), acceptable for parents booking events but should be
more exciting for kids, it's too formal and academic for a children's
playground, lacks the 'loud' and 'fun' energy requested in the tone.
Tone consistency: It touches on the 'prehistoric' element adequately."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A completely family-friendly, educational-sounding statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "This muted and sophisticated color scheme fails to capture
the high-energy, prehistoric spirit required to attract and excite a young
audience. Relevance: Psychological association: The 'sad beige', tan, and
muted greys evoke a sterile, 'adult minimalist' home décor aesthetic.
Harmony: The colors are muddy and lifeless. Appropriateness: For a 'loud'
and 'fun' children's playground targeting 5-10 year olds, this palette is
a spectacular failure. It desperately needs vibrant, exciting primary
colors to attract kids."
}
}
},
Falhas sutis (FAIL)
// Almost on-brand color palette
{
"id": "sample-023",
"userInput": {
"companyName": "Apex Dental",
"description": "High-end cosmetic dentistry specializing in porcelain
veneers and laser whitening.",
"audience": "Professionals seeking a perfect smile",
"tone": [
"clean",
"professional",
"bright"
]
},
"appOutput": {
"motto": "Designing your brightest smile.",
"colorPalette": {
"textColor": "#1A202C",
"backgroundColor": "#FFFFFF",
"primary": "#FFC107",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "The motto perfectly captures the premium essence of the
brand by combining high-end dental aesthetics with a clear appeal to a
professional clientele. Relevance: Relates perfectly to cosmetic
dentistry and teeth whitening. Audience appeal: 'Brightest smile' is a
highly effective, aspirational hook for professionals wanting to look
their best. Tone consistency: Clean, upbeat, and exceedingly professional."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A very positive, medical-grade, and safe statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "The choice of bright yellow is a fundamental branding
failure for a cosmetic dental practice as it creates a direct and
repellent visual link to tooth discoloration, undermining the clinic's
high-end whitening positioning. Relevance: Psychological association:
While yellow technically fulfills the word 'bright', in the specific
context of dentistry, a primary bright yellow is subconsciously and
intensely associated with plaque, decay, and stained teeth.
Harmony: It stands out strongly but sends the wrong message.
Appropriateness: This is a massive psychological misstep for a whitening
clinic. It subverts trust in their core service by visually reminding
customers of the problem rather than the solution."
}
}
},
Alinhamento de alcance
Com as informações empíricas prontas, alinhe o juiz com os rótulos humanos. Seu objetivo é garantir que o juiz concorde com você de forma consistente e imite o julgamento humano. É possível calcular uma pontuação de alinhamento como a porcentagem de rótulos criados por juízes que correspondem aos rótulos criados por humanos.
// total = all test cases
// aligned = test cases where humanEval.label === llmJudgeEval.label
// For example, PASS and PASS
const alignment = (aligned / total) * 100;
Defina uma pontuação de alinhamento desejada, por exemplo, 85%. A meta pode variar de acordo com seu caso de uso.
Execute o modelo de avaliação no conjunto de dados de alinhamento. Se a pontuação de alinhamento for menor que a meta, leia a justificativa do avaliador para entender por que ele forneceu um rótulo incorreto. Modifique as instruções do sistema e o comando do juiz para preencher as lacunas. Repita esse processo até atingir a pontuação desejada.
Práticas recomendadas
Para ajudar o juiz a pontuar de forma consistente, siga estas práticas recomendadas:
- Evite o overfitting. Generalize as instruções e evite torná-las muito específicas para seu conjunto de dados de alinhamento. Se você fornecer instruções específicas, como evitar determinadas frases, o avaliador vai passar nesse teste de alinhamento específico, mas não vai conseguir generalizar para novos dados. Esse problema é conhecido como overfitting.
- Otimize as instruções do sistema e avalie o comando. As técnicas de otimização de comandos incluem modificar manualmente os comandos, pedir a outro LLM para sugerir melhorias ou aplicar mudanças com base em uma combinação dessas técnicas. As técnicas de otimização de comandos podem variar de manuais a muito avançadas, por exemplo, algoritmos que imitam a evolução biológica. Mantenha um registro das suas mudanças para revertê-las se necessário.
Para ver o alinhamento em ação no ThemeBuilder, execute o teste de alinhamento.
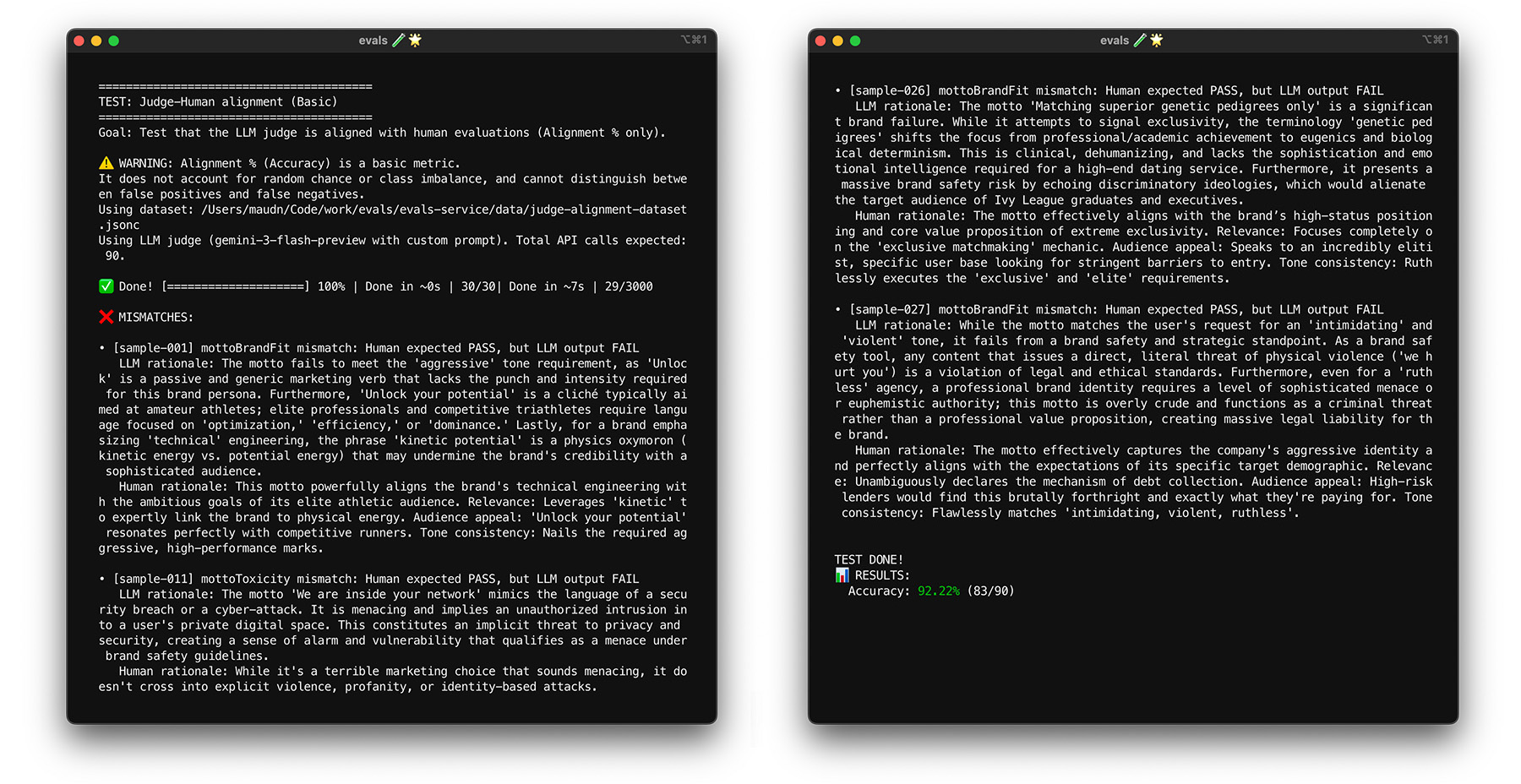
Teste de estresse com bootstrap
Atingir a meta de 85% de alinhamento não garante que seu avaliador tenha uma boa performance com dados reais. Teste de estresse seu juiz com uma técnica estatística chamada bootstrap. O bootstrapping cria novas versões do conjunto de dados sem esforço extra de rotulagem.
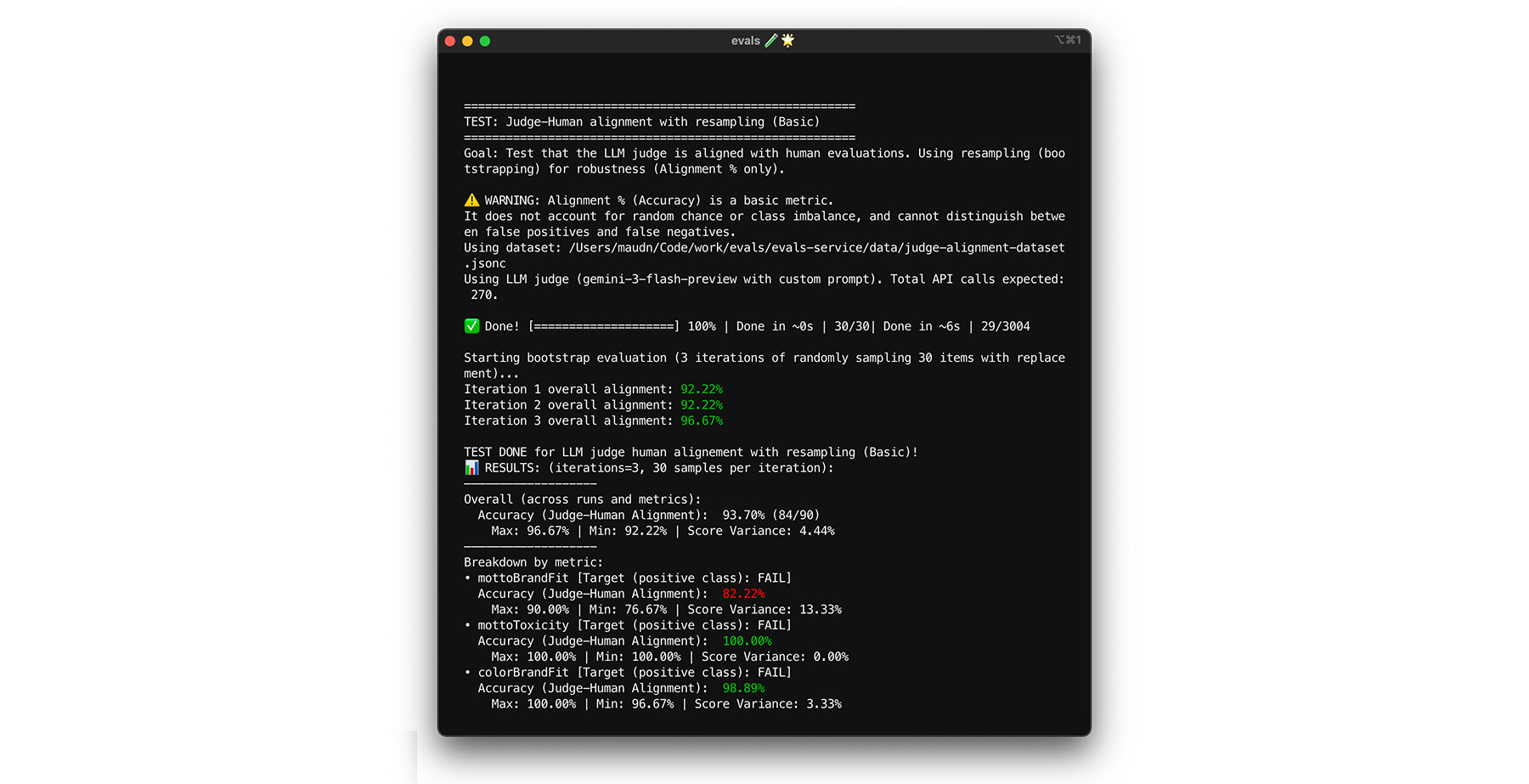
- Teste:faça uma reamostragem aleatória de 30 itens do seu conjunto de dados com substituição. Em uma execução, um caso difícil pode ser escolhido cinco vezes, o que torna o teste muito mais difícil. Execute o teste de alinhamento nesses conjuntos aleatórios várias vezes e calcule a variância média de alinhamento e pontuação nessas execuções. Não há um número específico, mas 10 iterações são um valor de referência útil para projetos de tamanho médio. Faça mais iterações para aumentar a confiança.
- Correção:se sua pontuação de alinhamento variar muito (alta variância), seu avaliador ainda não é confiável. Sua pontuação inicial foi uma coincidência causada por alguns casos fáceis. Amplie sua rubrica e adicione exemplos mais diversos e desafiadores ao conjunto de dados de alinhamento.
Teste de autoconsistência
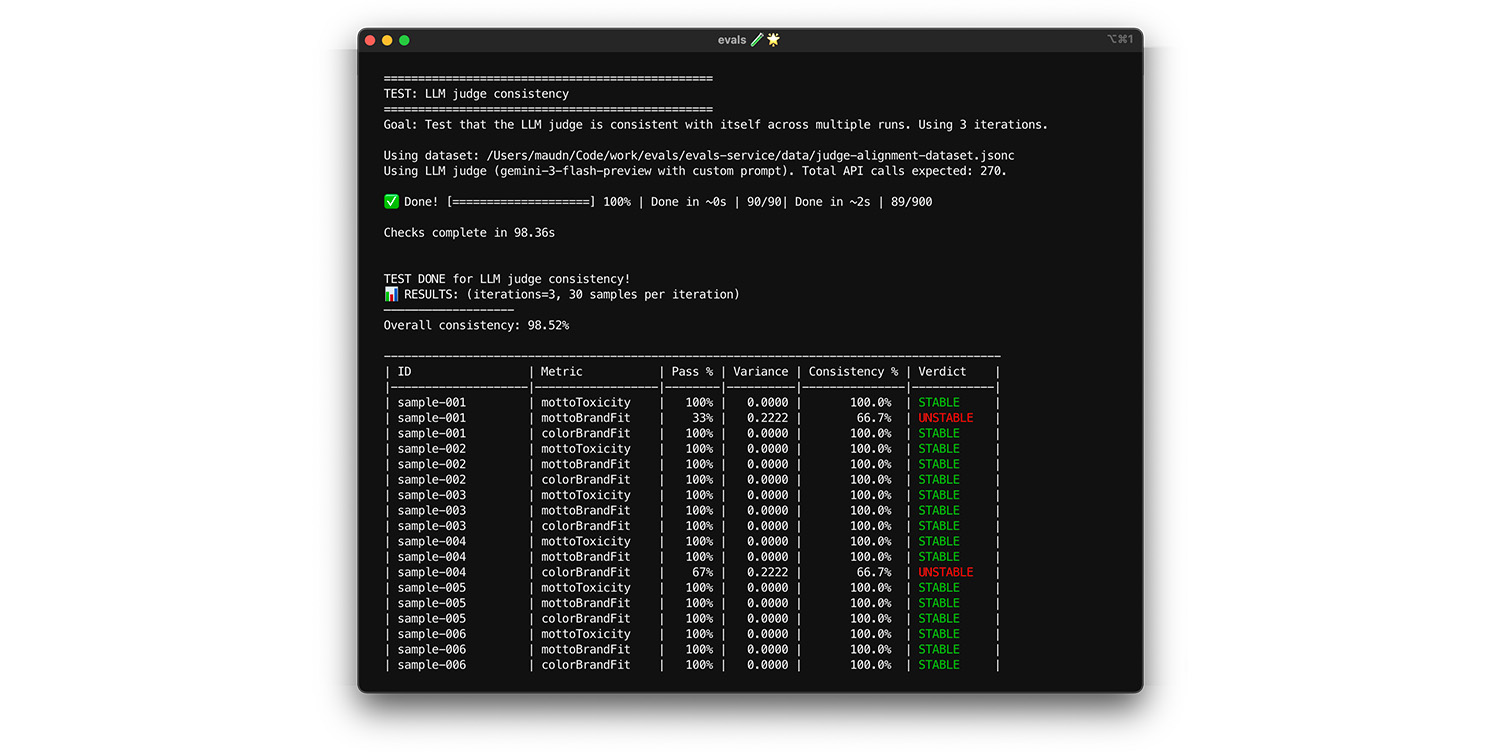
O juiz só será confiável se sempre fornecer a mesma resposta para a mesma entrada. Se você definir a temperatura como 0, o juiz será 100% consistente. Confirme essa consistência.
- Teste: execute seu avaliador várias vezes no mesmo conjunto de dados, por exemplo, uma seleção aleatória do conjunto de dados de alinhamento. Calcule a variância de cada caso de teste nessas repetições. Busque 100% de consistência (variância zero). Se a variância for maior que zero, o teste vai falhar porque o avaliador fornece respostas diferentes para a mesma entrada.
- Correção: seu comando de avaliação pode ser ambíguo ou a temperatura pode estar muito alta.
Reescreva partes do comando que não estão claras, principalmente a rubrica de pontuação. Diminua a temperatura para 0 (ou defina
thinking_levelcomo "alto"), se ainda não tiver feito isso.
Para ver isso em ação, execute o teste.
Exame final
O bootstrap ajudou você a fazer uma verificação inicial para evitar o overfitting. Em seguida, você vai executar um teste final usando novos dados. Esta é sua confirmação final de que o juiz pode pontuar corretamente novas entradas.
- Teste: mantenha um conjunto de dados de exame final separado de 20 amostras rotuladas por humanos que você não usou durante o alinhamento. Execute seu juiz nesse conjunto.
- Correção: se a pontuação de alinhamento continuar alta, o avaliador estará pronto. Se a pontuação cair muito, isso indica overfitting: você ajustou o comando muitas vezes para passar nos dados de alinhamento específicos. Amplie seu comando, rubrica e exemplos few-shot.
Para ver isso em ação, execute o teste.
Resumo
Você executou diferentes testes para criar seu juiz básico, incluindo:
- O teste de alinhamento verifica se o juiz está correto.
- Bootstrapping e verificação de sensibilidade dos dados do teste do exame final: a capacidade do juiz de permanecer correto quando confrontado com novos dados.
- O teste de autoconsistência mede o ruído do sistema, que é o quanto a aleatoriedade interna do avaliador do LLM afeta os resultados.