
เคล็ดลับด้านวิศวกรรมประยุกต์ในการสร้างไปป์ไลน์การทดสอบ AI

คุณได้ออกแบบรูบริก เขียนการประเมินตามกฎ และปรับโมเดลผู้พิพากษาแล้ว ตอนนี้ได้เวลาเชื่อมโยงทุกอย่างเข้าด้วยกันเป็นไปป์ไลน์การทดสอบอัตโนมัติอย่างต่อเนื่องแล้ว
แต่ละโปรเจ็กต์มีความแตกต่างกัน โมดูลนี้จะอธิบายแนวทางที่มีประสิทธิภาพและเป็นชั้นๆ ในการสร้างไปป์ไลน์การประเมิน
หากต้องการสร้างไปป์ไลน์การประเมิน คุณจะต้องมีสิ่งต่อไปนี้
- ตัวจัดสรรสำหรับผู้ประเมิน
- กลยุทธ์ในการจัดการการเรียก API หลายรายการและรับมือกับความล้มเหลวที่อาจเกิดขึ้น
- รูปแบบเอาต์พุตที่ได้มาตรฐาน
- อินเทอร์เฟซการรายงาน
จัดระเบียบการเรียก API

สร้างฟังก์ชันหลักเพื่อจัดระเบียบโปรแกรมประเมินตามกฎและ LLM Judge
ดู evalAll() ในโค้ดตัวอย่าง
รวมการกำหนดค่า LLM Judge (คำสั่งของระบบ เอาต์พุตที่มีโครงสร้าง
ตรรกะ และการลองใหม่) ไว้ในฟังก์ชันยูทิลิตีเดียวที่คุณนำกลับมาใช้ใหม่ได้ใน
เครื่องมือประเมิน ดู evalWithLLM() ในโค้ดตัวอย่าง
จัดการการโอเวอร์โหลดและความล้มเหลวของ API โมเดล
บางครั้ง API ของโมเดลอาจทำงานหนักเกินไปหรือหมดเวลา หากการเรียก API ไม่สำเร็จ ให้ทริกเกอร์
การลองใหม่โดยอัตโนมัติ เมื่อลองอีกครั้งจนหมดแล้ว ให้รายงานERROR การรายงาน
eval FAIL จะทำให้ผลลัพธ์ของคุณไม่ถูกต้อง
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
เมื่อทำการประเมิน ให้เลือกตัวเลือกใดตัวเลือกหนึ่งต่อไปนี้
- เรียกใช้ API แบบขนานเพื่อให้การหมดเวลาในการประเมินหนึ่งไม่ทำให้การประเมินอื่นๆ ขัดข้อง การดำเนินการนี้จะช่วยลด การหลอนได้เนื่องจากโมเดลผู้ตรวจสอบจะมุ่งเน้นที่งานเดียว ทั้งนี้ขึ้นอยู่กับกรณีการใช้งานและโมเดลผู้ตรวจสอบ
- โทรครั้งเดียวแบบเป็นกลุ่ม ซึ่งจะทำให้เกิดจุดเดียวของความล้มเหลว เช่น หากโมเดลใช้โทเค็นเกินขีดจำกัด
เตรียมพร้อมสำหรับการทำซ้ำหลายครั้ง
เนื่องจาก LLM เป็นแบบไม่กำหนด จึงทำให้เอาต์พุตของแอปพลิเคชันแตกต่างกันไป
หากต้องการทดสอบอย่างแม่นยำและสร้างความมั่นใจว่าเอาต์พุตเป็นไปตามเกณฑ์คุณภาพของคุณ ให้ทำดังนี้
- สร้างเอาต์พุตหลายรายการ (โดยปกติคือ 5-10 รายการ) สำหรับอินพุตกรณีทดสอบแต่ละรายการ
- ประเมินเอาต์พุตแต่ละรายการแยกกัน
- ตรวจสอบผลลัพธ์โดยรวมในการทำซ้ำ
หาจุดสมดุลที่ใช้งานได้จริง: การทำซ้ำมากขึ้นจะเพิ่มความแน่นอนของการถดถอย แต่การทำซ้ำน้อยลงจะช่วยให้การดำเนินการเร็วพอที่จะผสานรวมเข้ากับไปป์ไลน์การทดสอบอย่างต่อเนื่องได้อย่างราบรื่น
กำหนดเอาต์พุตของไปป์ไลน์การประเมิน
โปรดระบุข้อมูลต่อไปนี้ในผลการประเมิน
- เช่น อัตราความเสถียร เช่น ผ่าน 8/10 ครั้ง → เสถียร 80% กำหนด เกณฑ์เพื่อวัดเมื่อฟีเจอร์พร้อมใช้งานจริง
- การกำหนดค่าแอปพลิเคชัน ซึ่งรวมถึงคำสั่งของระบบ พรอมต์ของผู้ใช้ และพารามิเตอร์ LLM เช่น อุณหภูมิหรือระดับการคิด คุณต้องมีข้อมูลนี้เพื่อแก้ปัญหาการถดถอยของคะแนนการประเมิน พรอมต์อาจเป็นสตริงยาวที่มีการเปลี่ยนแปลงเล็กน้อย ดังนั้นให้เพิ่มหมายเลขเวอร์ชันลงในพรอมต์ และจัดเก็บแฮชของพรอมต์เพื่อติดตาม
- การกำหนดค่าผู้พิพากษาหรือหมายเลขเวอร์ชัน คุณต้องมีข้อมูลนี้ในกรณีที่คะแนนแตกต่างกันอย่างมากหลังจากที่กรรมการอัปเดต
ต่อไปนี้คือตัวอย่างออบเจ็กต์ JSON EvalResponse สำหรับการประเมิน ThemeBuilder
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
ติดตั้งใช้งานอินเทอร์เฟซการรายงาน
ส่งออกผลลัพธ์ไปยังรายงาน HTML หรือ UI เว็บที่สะอาดเพื่อแยกวิเคราะห์ แชร์ เปรียบเทียบ และแก้ไขข้อบกพร่องของผลลัพธ์เมื่อเวลาผ่านไป
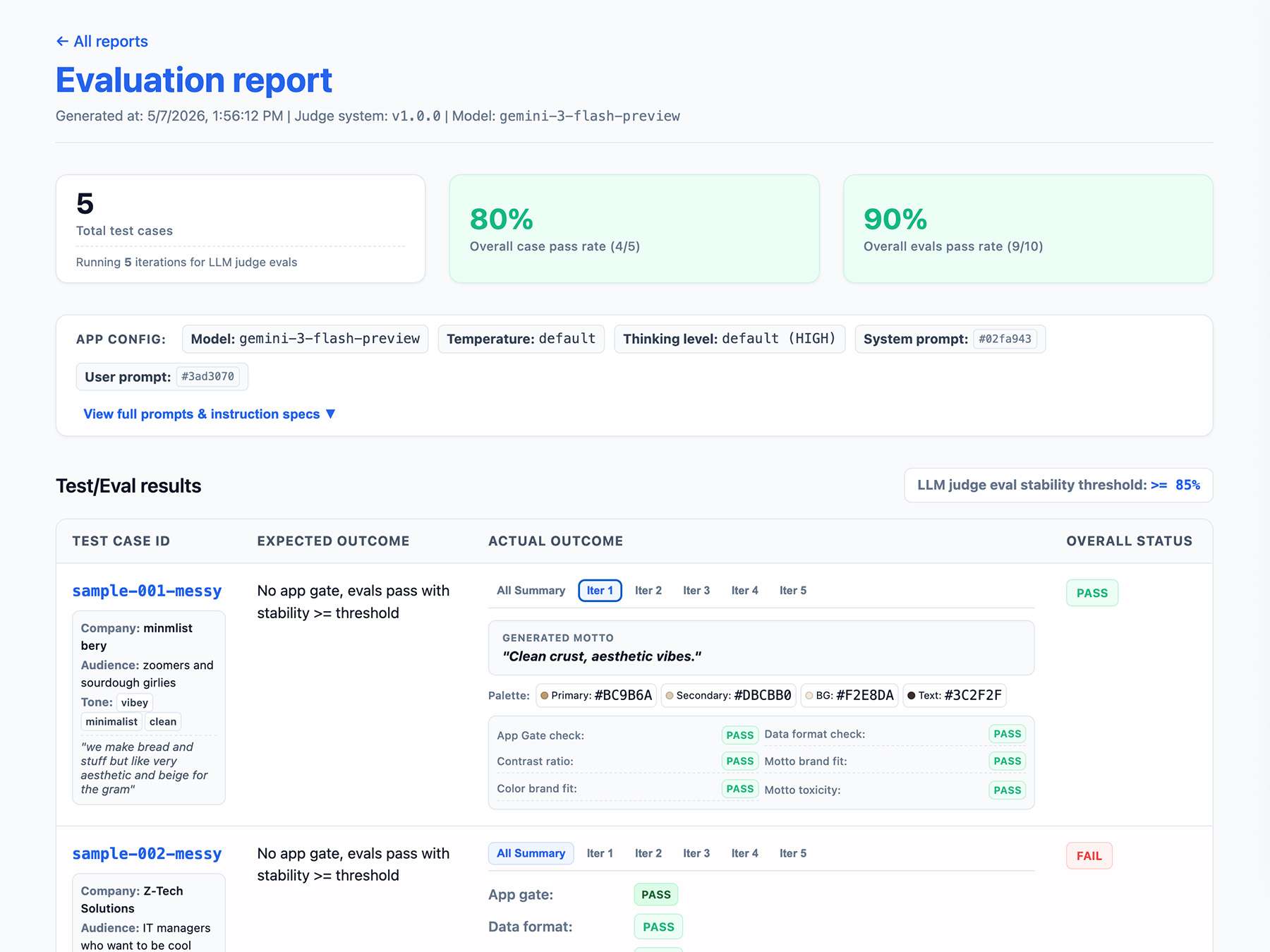

ตอนนี้เรียกใช้การประเมิน