
Áp dụng các mẹo kỹ thuật để xây dựng quy trình kiểm thử AI.

Bạn đã thiết kế thang điểm, viết các bản đánh giá dựa trên quy tắc và điều chỉnh mô hình đánh giá. Giờ là lúc bạn kết hợp tất cả những điều này vào một quy trình kiểm thử tự động, liên tục.
Mỗi dự án đều khác nhau. Mô-đun này trình bày một phương pháp hiệu quả, theo từng lớp để xây dựng quy trình đánh giá của bạn.
Để tạo pipeline đánh giá, bạn cần có những thông tin sau:
- Một trình điều phối cho nhân viên đánh giá
- Một chiến lược để xử lý nhiều lệnh gọi API và giải quyết các lỗi tiềm ẩn
- Một định dạng đầu ra được chuẩn hoá
- Giao diện báo cáo
Điều phối lệnh gọi API

Tạo một hàm chính để điều phối các trình đánh giá dựa trên quy tắc và trình đánh giá LLM.
Xem lại evalAll() trong mã ví dụ.
Tập trung cấu hình của LLM judge (hướng dẫn hệ thống, logic đầu ra có cấu trúc và số lần thử lại) vào một hàm hiệu dụng duy nhất mà bạn có thể dùng lại trên các trình đánh giá. Xem lại evalWithLLM() trong mã ví dụ.
Xử lý các trường hợp quá tải và lỗi API mô hình
Đôi khi, các API mô hình bị quá tải hoặc hết thời gian chờ. Nếu lệnh gọi API của bạn không thành công, hãy kích hoạt tính năng tự động thử lại. Sau khi hết số lần thử lại, hãy báo cáo ERROR. Việc báo cáo một eval FAIL sẽ làm sai lệch kết quả của bạn.
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
Khi chạy quy trình đánh giá, hãy chọn một trong các lựa chọn sau:
- Thực hiện các lệnh gọi API ở chế độ song song để một lệnh eval bị hết thời gian chờ không làm hỏng các lệnh khác. Tuỳ thuộc vào trường hợp sử dụng và mô hình đánh giá, điều này có thể giảm hiện tượng ảo giác vì mô hình đánh giá tập trung vào một nhiệm vụ.
- Thực hiện một lệnh gọi theo lô duy nhất. Điều này tạo ra một điểm lỗi duy nhất, chẳng hạn như nếu mô hình vượt quá giới hạn mã thông báo.
Chuẩn bị cho nhiều lần lặp lại
Vì LLM không xác định được nên đầu ra của ứng dụng sẽ khác nhau.
Để kiểm thử chính xác và tin tưởng rằng kết quả đáp ứng tiêu chuẩn chất lượng của bạn:
- Tạo nhiều đầu ra (thường từ 5 đến 10) cho mỗi đầu vào trường hợp kiểm thử.
- Đánh giá riêng từng kết quả.
- Kiểm tra kết quả tổng thể qua các lần lặp lại.
Tìm ra sự cân bằng thực tế: nhiều lần lặp lại sẽ làm tăng độ chắc chắn của hồi quy, nhưng ít lần lặp lại sẽ giúp quá trình thực thi đủ nhanh để phù hợp một cách liền mạch với quy trình kiểm thử liên tục của bạn.
Xác định đầu ra của quy trình đánh giá
Hãy thêm những thông tin sau vào kết quả đánh giá:
- Tỷ lệ ổn định, ví dụ: Đạt 8/10 lần → 80% ổn định. Đặt ngưỡng để đo lường thời điểm một tính năng đã sẵn sàng cho bản phát hành công khai.
- Cấu hình ứng dụng của bạn. Điều này bao gồm chỉ dẫn của hệ thống, lời nhắc của người dùng và các tham số của LLM, chẳng hạn như nhiệt độ hoặc mức độ suy nghĩ. Bạn cần thông tin này để khắc phục các vấn đề về điểm số đánh giá giảm. Câu lệnh có thể là chuỗi dài với một số biến thể nhỏ, vì vậy, hãy thêm số phiên bản vào câu lệnh và lưu trữ hàm băm của câu lệnh để theo dõi.
- Cấu hình của giám khảo hoặc số phiên bản. Bạn cần có thông tin này trong trường hợp điểm số của bạn thay đổi đáng kể sau khi có bản cập nhật của trọng tài.
Sau đây là ví dụ về đối tượng JSON EvalResponse cho các lượt đánh giá ThemeBuilder:
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
Triển khai giao diện báo cáo
Xuất kết quả sang báo cáo HTML hoặc giao diện người dùng web rõ ràng để phân tích cú pháp, chia sẻ, so sánh và gỡ lỗi kết quả theo thời gian.
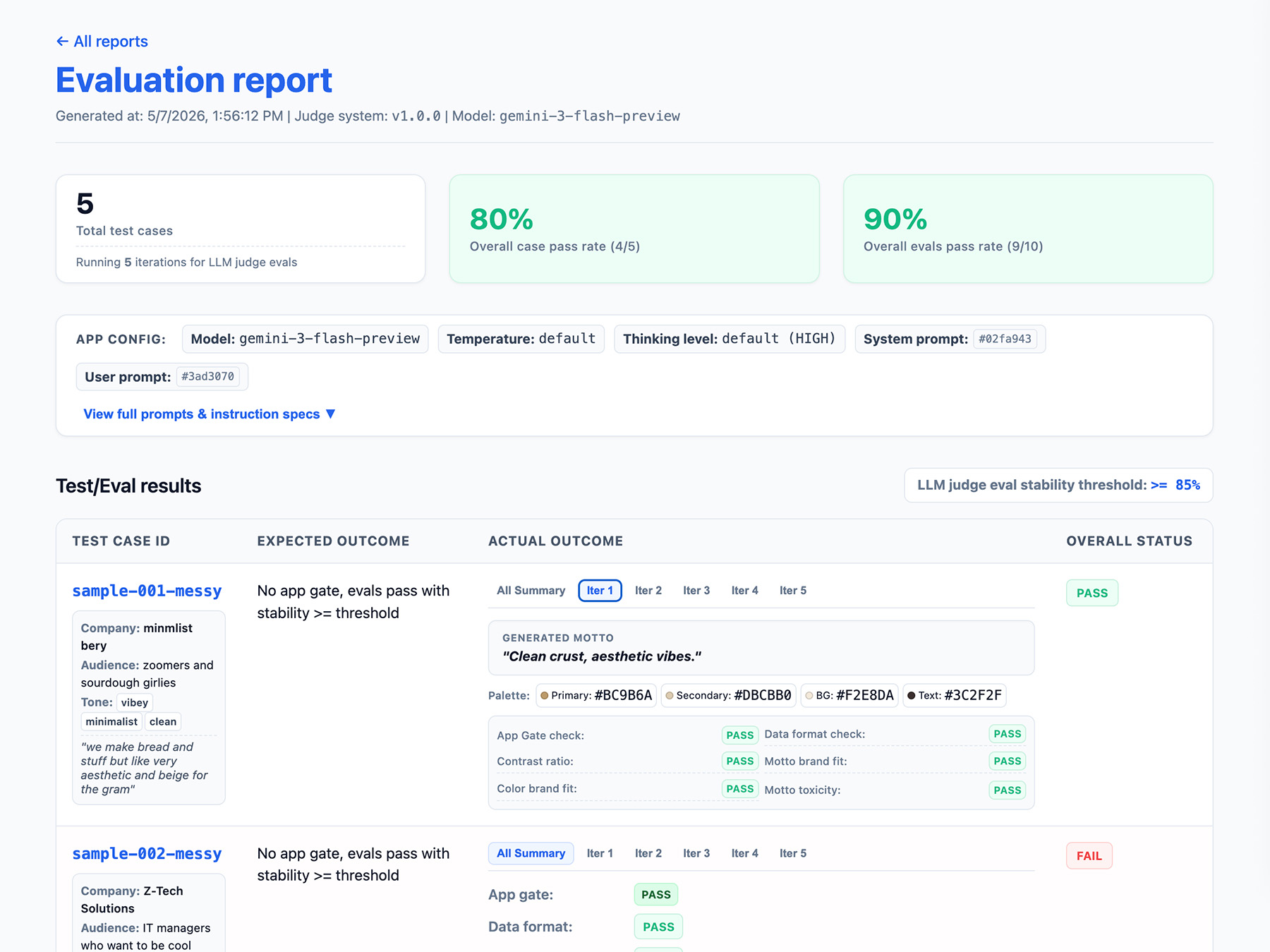

Bây giờ, hãy chạy các quy trình đánh giá.