


Veröffentlicht: 12. März 2025, zuletzt aktualisiert: 28. Mai 2025
| Erklärvideo | Web | Erweiterungen | Chrome-Status | Absicht |
|---|---|---|---|---|
| MDN | Ansicht | Versandabsicht |
Mit der Summarizer API können Sie Zusammenfassungen von Informationen in verschiedenen Längen und Formaten erstellen. Verwenden Sie sie mit dem Foundation Model in Chrome oder anderen in Browsern integrierten Sprachmodellen, um lange oder komplizierte Texte prägnant zu erklären.
Wenn Sie die API clientseitig verwenden, können Sie Daten lokal verarbeiten. So können Sie sensible Daten schützen und die Verfügbarkeit im großen Maßstab gewährleisten. Das Kontextfenster ist jedoch viel kleiner als bei serverseitigen Modellen. Daher kann es schwierig sein, sehr lange Dokumente zusammenzufassen. Um dieses Problem zu beheben, können Sie die Technik Zusammenfassung von Zusammenfassungen verwenden.
Was ist eine Zusammenfassung von Zusammenfassungen?
Um die Technik Zusammenfassung von Zusammenfassungen zu verwenden, teilen Sie die Eingabeinhalte an wichtigen Stellen auf und fassen Sie dann jeden Teil unabhängig zusammen. Sie können die Ausgaben aus den einzelnen Teilen verketten und diesen verketteten Text dann zu einer endgültigen Zusammenfassung zusammenfassen.

Inhalte sorgfältig aufteilen
Es ist wichtig, zu überlegen, wie Sie einen langen Text aufteilen, da verschiedene Strategien zu unterschiedlichen Ausgaben bei verschiedenen LLMs führen können. Im Idealfall sollte der Text aufgeteilt werden, wenn sich das Thema ändert, z. B. in einem neuen Abschnitt eines Artikels oder in einem neuen Absatz. Es ist wichtig, den Text nicht mitten in einem Wort oder Satz aufzuteilen. Daher können Sie die Anzahl der Zeichen nicht als einzige Richtlinie für die Aufteilung verwenden.
Es gibt viele Möglichkeiten, dies zu tun. Im folgenden Beispiel haben wir den rekursiven Textsplitter von LangChain.jsverwendet, der Leistung und Ausgabequalität ausbalanciert. Das sollte für die meisten Arbeitslasten funktionieren.
Beim Erstellen einer neuen Instanz gibt es zwei wichtige Parameter:
chunkSizeist die maximale Anzahl von Zeichen, die in jeder Aufteilung zulässig sind.chunkOverlapist die Anzahl der Zeichen, die sich zwischen zwei aufeinanderfolgenden Aufteilungen überlappen. Dadurch wird sichergestellt, dass jeder Teil etwas Kontext aus dem vorherigen Teil enthält.
Teilen Sie den Text mit splitText() auf, um ein Array von Strings mit den einzelnen Teilen zurückzugeben.
Bei den meisten LLMs wird das Kontextfenster als Anzahl von Tokens und nicht als Anzahl von Zeichen angegeben. Im Durchschnitt enthält ein Token 4 Zeichen. In unserem Beispiel ist chunkSize 3.000 Zeichen lang, was ungefähr 750 Tokens entspricht.
Tokenverfügbarkeit ermitteln
Verwenden Sie die
measureInputUsage()
Methode und die inputQuota
Eigenschaft, um zu ermitteln, wie viele Tokens für eine Eingabe verfügbar sind. In diesem Fall ist die Implementierung unbegrenzt, da Sie nicht wissen können, wie oft die Zusammenfassung ausgeführt wird, um den gesamten Text zu verarbeiten.
Zusammenfassungen für jede Aufteilung erstellen
Nachdem Sie festgelegt haben, wie die Inhalte aufgeteilt werden, können Sie mit der Summarizer API Zusammenfassungen für die einzelnen Teile erstellen.
Erstellen Sie mit der
create() Funktion eine Instanz der Zusammenfassung. Um so viel
Kontext wie möglich beizubehalten, haben wir den Parameter format auf plain-text, type
auf tldr,
und length auf long gesetzt.
Erstellen Sie dann die Zusammenfassung für jede Aufteilung, die von RecursiveCharacterTextSplitter erstellt wurde, und verketten Sie die Ergebnisse zu einem neuen String.
Wir haben jede Zusammenfassung durch eine neue Zeile getrennt, um die Zusammenfassung für jeden Teil klar zu kennzeichnen.
Diese neue Zeile ist zwar nicht wichtig, wenn diese Schleife nur einmal ausgeführt wird, aber sie ist nützlich, um zu ermitteln, wie jede Zusammenfassung zum Tokenwert für die endgültige Zusammenfassung beiträgt. In den meisten Fällen sollte diese Lösung für mittellange und lange Inhalte funktionieren.
Rekursive Zusammenfassung von Zusammenfassungen
Wenn Sie eine sehr lange Textmenge haben, kann die Länge der verketteten Zusammenfassung größer als das verfügbare Kontextfenster sein. In diesem Fall schlägt die Zusammenfassung fehl. Um dieses Problem zu beheben, können Sie die Zusammenfassungen rekursiv zusammenfassen.
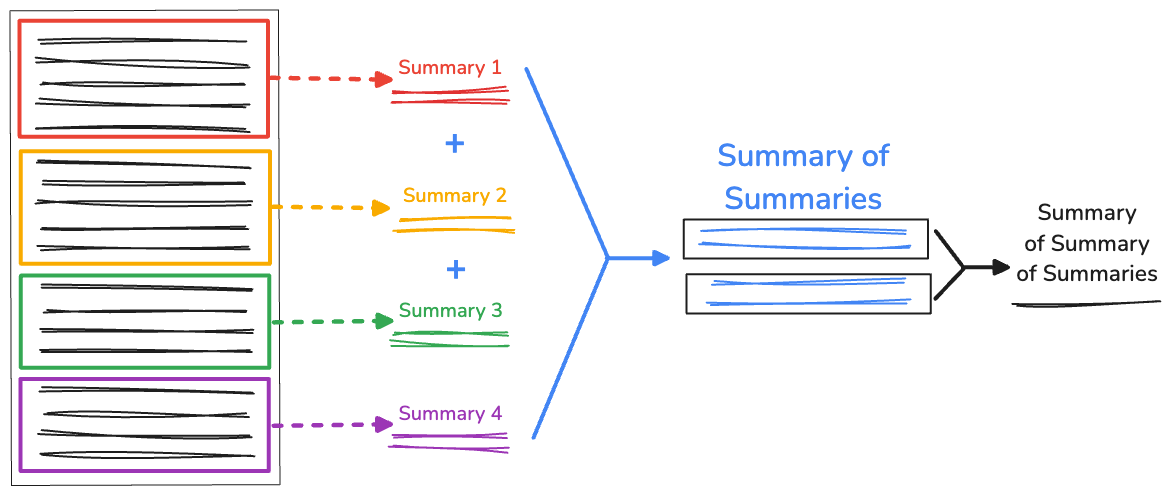
Wir erfassen weiterhin die ursprünglichen Aufteilungen, die von RecursiveCharacterTextSplitter generiert wurden. In der Funktion recursiveSummarizer() wiederholen wir dann den Zusammenfassungsvorgang basierend auf der Zeichenlänge der verketteten Aufteilungen. Wenn die Zeichenlänge der Zusammenfassungen 3000 überschreitet, werden sie in fullSummaries verkettet. Wenn das Limit nicht erreicht wird, wird die Zusammenfassung als partialSummaries gespeichert.
Sobald alle Zusammenfassungen erstellt wurden, werden die endgültigen Teilzusammenfassungen zur vollständigen Zusammenfassung hinzugefügt. Wenn in fullSummaries nur eine Zusammenfassung vorhanden ist, ist keine zusätzliche Rekursion erforderlich. Die Funktion gibt eine endgültige Zusammenfassung zurück. Wenn mehr als eine Zusammenfassung vorhanden ist, wird die Funktion wiederholt und die Teilzusammenfassungen werden weiter zusammengefasst.
Wir haben diese Lösung mit dem Internet Relay Chat (IRC) RFC, der 110.030 Zeichen und 17.560 Wörter enthält, getestet. Die Summarizer API hat die folgende Zusammenfassung erstellt:
Internet Relay Chat (IRC) ist eine Möglichkeit, in Echtzeit online über Textnachrichten zu kommunizieren. Sie können in Channels chatten oder private Nachrichten senden und Befehle verwenden, um den Chat zu steuern und mit dem Server zu interagieren. Es ist wie ein Chat room im Internet, in dem Sie Nachrichten eingeben und die Nachrichten anderer Nutzer sofort sehen können.
Das ist ziemlich effektiv. Und es sind nur 309 Zeichen.
Beschränkungen
Mit der Technik „Zusammenfassung von Zusammenfassungen“ können Sie innerhalb des Kontextfensters eines clientseitigen Modells arbeiten. Obwohl clientseitige KI viele Vorteile bietet, können die folgenden Probleme auftreten:
- Weniger genaue Zusammenfassungen: Bei der Rekursion ist die Wiederholung des Zusammenfassungsvorgangs möglicherweise unendlich und jede Zusammenfassung ist weiter vom Originaltext entfernt. Das bedeutet, dass das Modell eine endgültige Zusammenfassung erstellen kann, die zu oberflächlich ist, um nützlich zu sein.
- Langsamere Leistung: Die Erstellung jeder Zusammenfassung dauert einige Zeit. Auch hier kann es bei einer unendlichen Anzahl von Zusammenfassungen in längeren Texten mehrere Minuten dauern, bis der Vorgang abgeschlossen ist.
Wir haben eine Demo für die Zusammenfassung, und Sie können sich den vollständigen Quellcode ansehen.
Feedback geben
Testen Sie die Technik „Zusammenfassung von Zusammenfassungen“ mit unterschiedlich langen Eingabe texten, verschiedenen Aufteilungsgrößen und verschiedenen Überlappungslängen mit der Summarizer API.
- Wenn Sie Feedback zur Implementierung von Chrome haben, melden Sie einen Fehler oder senden Sie eine Funktionsanfrage.
- Dokumentation auf MDN lesen
- Chatten Sie mit dem Chrome AI-Team über den Zusammenfassungsvorgang oder andere Fragen zur integrierten KI.