


Опубликовано: 12 марта 2025 г., Последнее обновление: 28 мая 2025 г.
| Пояснительная записка | Веб | Расширения | Статус Chrome | Намерение |
|---|---|---|---|---|
| МДН | Вид | Намерение отправить |
API Summarizer помогает создавать краткие обзоры информации различной длины и формата. Используйте его с базовой моделью Chrome или другими языковыми моделями, встроенными в браузеры, для лаконичного объяснения длинных или сложных текстов.
При обработке данных на стороне клиента, вы можете работать с данными локально, что позволяет обеспечить безопасность конфиденциальных данных и масштабируемую доступность. Однако контекстное окно значительно меньше, чем в моделях на стороне сервера, что означает, что суммирование очень больших документов может быть затруднительным. Для решения этой проблемы можно использовать метод суммирования сумм .
Что такое краткое изложение кратких изложений?
Для использования метода суммирования сумм , разделите входной контент по ключевым моментам, а затем суммируйте каждую часть независимо. Вы можете объединить результаты из каждой части, а затем суммировать этот объединенный текст в одно итоговое резюме.
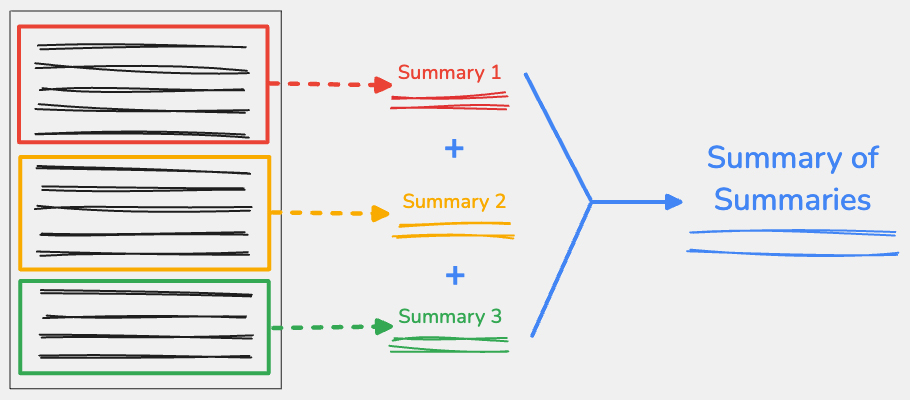
Продуманно разделите свой контент.
Важно продумать, как вы будете разделять большой текст, поскольку разные стратегии могут приводить к разным результатам в рамках магистерских программ. В идеале текст следует разделять при смене темы, например, при переходе к новому разделу статьи или к абзацу. Важно избегать разделения текста посередине слова или предложения, а это значит, что нельзя использовать количество символов в качестве единственного критерия разделения.
Существует множество способов это сделать. В следующем примере мы использовали Recursive Text Splitter из LangChain.js , который обеспечивает баланс между производительностью и качеством выходных данных. Это должно работать для большинства задач.
При создании нового экземпляра необходимо учитывать два ключевых параметра:
-
chunkSize— это максимальное количество символов, разрешенное в каждом фрагменте. -
chunkOverlapопределяет количество символов, которые должны перекрываться между двумя последовательными фрагментами. Это гарантирует, что каждый фрагмент будет содержать часть контекста из предыдущего фрагмента.
Разделите текст с помощью splitText() , чтобы получить массив строк, содержащий каждый фрагмент.
В большинстве программ LLM контекстное окно выражается количеством токенов, а не количеством символов. В среднем один токен содержит 4 символа. В нашем примере chunkSize составляет 3000 символов, что примерно соответствует 750 токенам.
Определите доступность токенов
Чтобы определить, сколько токенов доступно для использования в качестве входных данных, используйте метод measureInputUsage() и свойство inputQuota . В этом случае реализация практически безгранична, поскольку невозможно предсказать, сколько раз сумматор будет запускаться для обработки всего текста.
Сгенерируйте сводные данные для каждого разделения.
После того как вы настроите способ разделения контента, вы сможете сгенерировать сводки для каждой части с помощью API Summarizer.
Создайте экземпляр сумматора с помощью функции create() . Чтобы сохранить как можно больше контекста, мы установили параметр format в значение plain-text , type в tldr и length в long .
Затем сгенерируйте сводку для каждого фрагмента, созданного RecursiveCharacterTextSplitter , и объедините результаты в новую строку. Мы разделили каждую сводку новой строкой, чтобы четко обозначить сводку для каждой части.
Хотя эта новая строка не имеет значения при однократном выполнении цикла, она полезна для определения того, как каждое резюме влияет на значение токена для итогового резюме. В большинстве случаев это решение должно работать для контента средней и большой длины.
Рекурсивное обобщение обобщений
При работе с очень длинным текстом длина объединенного резюме может превышать доступное контекстное окно, что приводит к сбою суммирования. Для решения этой проблемы можно рекурсивно суммировать резюме.
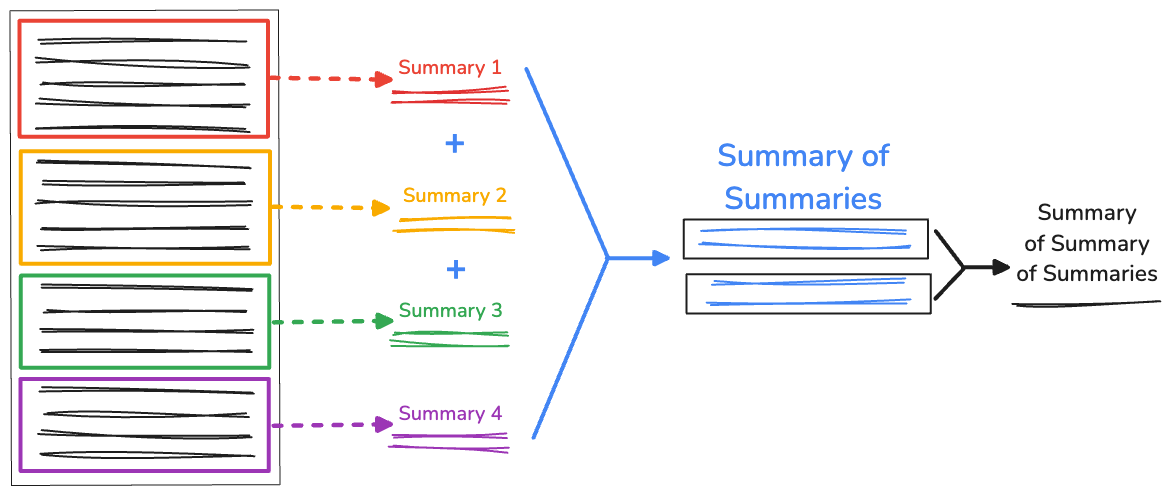
Мы по-прежнему собираем исходные фрагменты текста, сгенерированные функцией RecursiveCharacterTextSplitter . Затем в функции recursiveSummarizer() мы циклически выполняем процесс суммирования, основываясь на длине символов объединенных фрагментов. Если длина символов в суммировании превышает 3000 , мы объединяем их в fullSummaries . Если предел не достигнут, сумма сохраняется как partialSummaries .
После того, как все сводки сгенерированы, окончательные частичные сводки добавляются к полной сводке. Если в fullSummaries содержится только одна сводка, дополнительная рекурсия не требуется. Функция возвращает окончательную сводку. Если присутствует более одной сводки, функция повторяется и продолжает суммировать частичные сводки.
Мы протестировали это решение с помощью протокола Internet Relay Chat (IRC) RFC , который содержит целых 110 030 символов, включая 17 560 слов. API сумматора предоставил следующее резюме:
Интернет-чат Relay Chat (IRC) — это способ общения в режиме реального времени с помощью текстовых сообщений. Вы можете общаться в каналах или отправлять личные сообщения, а также использовать команды для управления чатом и взаимодействия с сервером. Это как чат в интернете, где вы можете мгновенно набирать текст и видеть сообщения других пользователей.
Это довольно эффективно! И всего 309 символов.
Ограничения
Метод обобщения сводок помогает работать в рамках контекстного окна модели, подходящей для конкретного клиента. Хотя клиентский ИИ имеет множество преимуществ , вы можете столкнуться со следующими проблемами:
- Менее точные резюме : При использовании рекурсии процесс создания резюме может повторяться бесконечно, и каждое последующее резюме всё дальше отходит от исходного текста. Это означает, что модель может сгенерировать итоговое резюме, которое будет слишком поверхностным, чтобы быть полезным.
- Более низкая производительность : создание каждого резюме занимает время. Опять же, при бесконечном возможном количестве резюме в больших текстах этот подход может занять несколько минут.
У нас есть демонстрационная версия сумматора , и вы можете посмотреть полный исходный код .
Поделитесь своим мнением.
Попробуйте использовать технику суммирования сводок с различными длинами входного текста, различными размерами разделения и различной длиной перекрытия, используя API сумматора .
- Чтобы оставить отзыв о реализации Chrome, отправьте сообщение об ошибке или запрос на добавление новой функции .
- Ознакомьтесь с документацией на MDN.
- Пообщайтесь с командой Chrome AI по поводу процесса создания кратких обзоров или по любым другим вопросам, касающимся встроенных функций ИИ.