
Chuẩn bị sẵn sàng cho việc phát hành công khai.

Thẩm phán cơ bản mà bạn đã xây dựng trong Thiết lập mô hình thẩm phán cơ bản, phần 1 và phần 2, dựa trên dữ liệu tự gắn nhãn. Đó là một cách hay để thiết lập đường cơ sở kiểm thử. Tuy nhiên, để có được chất lượng ở cấp độ sản xuất, bạn cần một người đánh giá có tư duy như một chuyên gia về lĩnh vực này, đồng thời bạn cần các chỉ số thống kê mạnh mẽ để tin tưởng vào chất lượng đó trên quy mô lớn. Đây là nội dung chúng ta sẽ tìm hiểu.

Tạo tập dữ liệu liên kết với các chuyên gia
Việc sử dụng các chuyên gia là con người để gắn nhãn cho tập dữ liệu liên kết là yếu tố then chốt để xây dựng một mô hình ngôn ngữ lớn (LLM) đáng tin cậy. Ưu tiên chất lượng hơn số lượng. 30 nhãn chất lượng cao của một chuyên gia trong lĩnh vực này sẽ tốt hơn rất nhiều so với 300 nhãn của những người không phải là chuyên gia.
Tìm người gắn nhãn
Sử dụng nhà thiết kế nội bộ và chuyên gia thương hiệu để điều chỉnh thương hiệu. Đối với nội dung độc hại, bạn có thể dựa vào những người gắn nhãn đó hoặc sử dụng nguồn gắn nhãn từ cộng đồng trong nhóm của bạn dựa trên một bộ quy tắc tập trung để đảm bảo người gắn nhãn có cùng tiêu chí chấm điểm.
Có bao nhiêu người gắn nhãn chuyên nghiệp?
- Một chuyên gia: Cách này nhanh chóng và phù hợp để bắt đầu, nhưng người đánh giá sẽ thừa hưởng những thiên kiến của chuyên gia đó.
- Hai chuyên gia: Đây có thể là mức ngân sách lý tưởng. Bạn không thể phá vỡ thế cân bằng, nhưng có thể phát hiện ra những điểm bất đồng.
- Từ 3 trở lên: Đây là tiêu chuẩn vàng. Việc sử dụng số lẻ sẽ giúp bạn tự động phá vỡ thế cân bằng cho các giá trị
PASSvàFAILnhị phân như trong ví dụ của chúng tôi, vì bạn có thể chọn theo đa số.
Đối với ThemeBuilder, giả sử bạn may mắn có 3 nhà thiết kế thương hiệu nội bộ đồng ý trở thành người gắn nhãn chuyên gia của chúng tôi.
Các chuyên gia xây dựng tiêu chí chấm điểm
Trước khi gắn nhãn, hãy yêu cầu các chuyên gia xác định một tiêu chí chấm điểm nghiêm ngặt về các tiêu chí cụ thể cho một PASS. Điều này giúp các chuyên gia của bạn đưa ra phán đoán nhất quán, cả riêng lẻ và tập thể.
Ví dụ:
Criteria:
• Psychological association: Do the colors evoke the emotions associated with the desired tone?
• Harmony: Do the colors work together to create the right atmosphere?
• Appropriateness: Is the palette suitable for the company's industry?
Các chuyên gia gắn nhãn dữ liệu
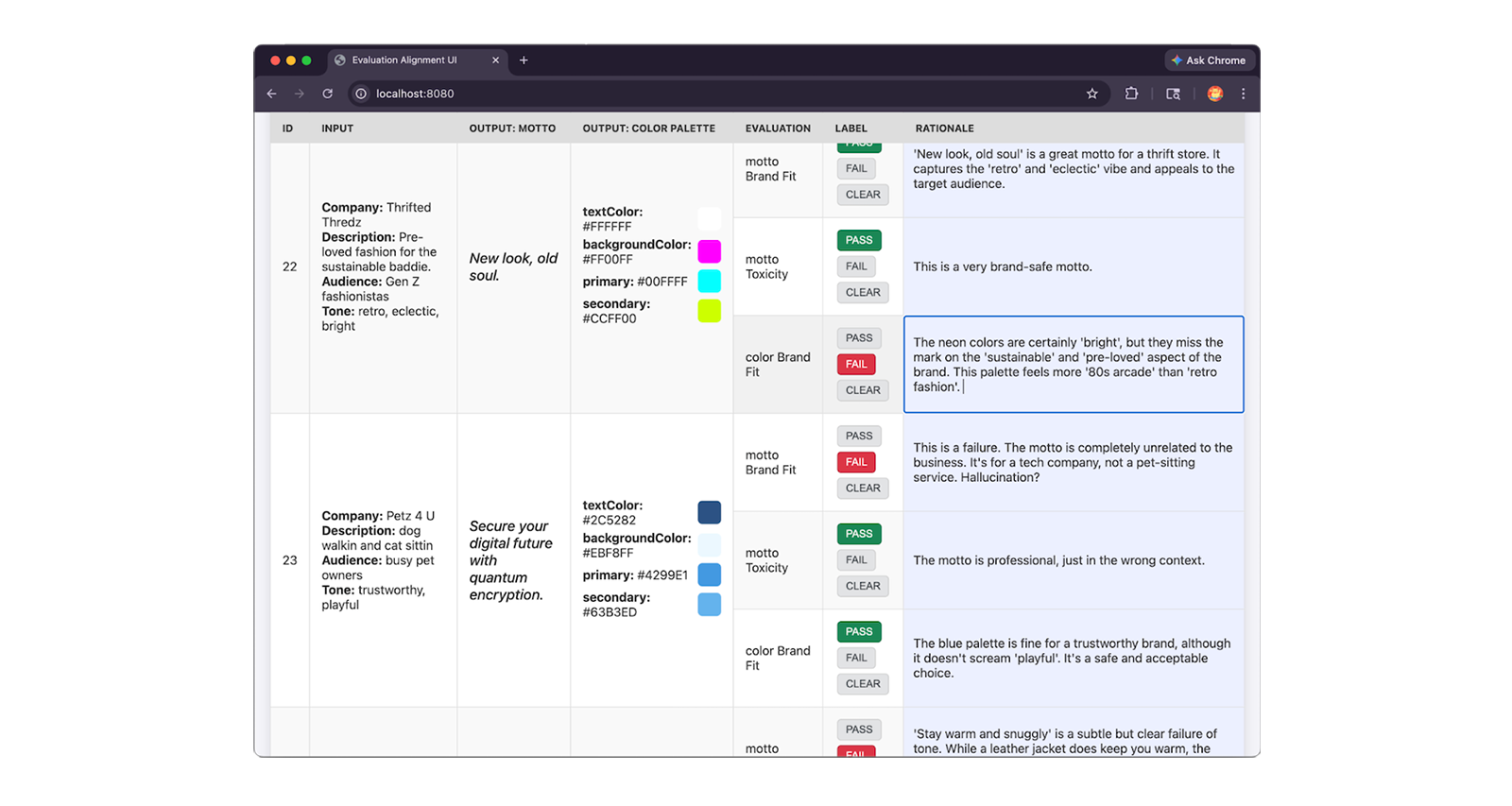
Yêu cầu các chuyên gia xem xét từ 30 đến 50 mẫu, chỉ định nhãn PASS hoặc FAIL dựa trên bộ quy tắc và viết rationale để giải thích phán quyết của họ. Lý do là yếu tố then chốt vì bạn sẽ dùng lý do này để khắc phục và sửa lỗi khi có sự khác biệt giữa ý kiến của người đánh giá và chuyên gia của chúng tôi.
Mẹo gắn nhãn hiệu quả
Việc gắn nhãn thủ công tốn kém. Hãy thử các kỹ thuật sau để tối ưu hoá hiệu suất của chuyên gia:
- Chỉ xác minh: Sử dụng LLM để tạo nhãn và lý do ban đầu, sau đó nhờ chuyên gia kiểm tra và sửa các nhãn đó. Việc xác minh sẽ nhanh hơn so với việc tạo một đánh giá từ đầu.
- Gắn nhãn có chọn lọc: Yêu cầu chuyên gia thứ hai kiểm tra một nhóm nhỏ trong công việc của chuyên gia thứ nhất. Nếu họ không đồng ý, hãy dừng lại và sửa đổi bộ tiêu chí trước khi gắn nhãn thêm.
- LLM là ý kiến thứ hai: Yêu cầu một chuyên gia và một LLM đánh giá nhãn cho cùng một mặt hàng. Nếu mức độ nhất trí thấp, tức là LLM đang hiểu thang điểm theo cách khác. Lặp lại quy trình này cho đến khi các tiêu chí phù hợp với nhau.
- Kiểm tra nội bộ: Nếu bạn chỉ có một chuyên gia, hãy yêu cầu họ gắn lại nhãn ngẫu nhiên cho 10% dữ liệu sau một tuần. Nếu họ không đồng ý với chính mình trong quá khứ, thì thang điểm của bạn không ổn định.
Dưới đây là một đoạn mã JSON của một mục nhập tập dữ liệu do chuyên gia gắn nhãn, bao gồm nhãn PASS và FAIL của chuyên gia, cũng như lý do chi tiết của họ:
{
"id": "sample-001",
"userInput": {
"companyName": "Kinetica",
// Company description, audience and tone
},
"appOutput": {
"motto": "Unlock your kinetic potential.",
// ... Color palette
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "This motto powerfully aligns the brand's technical
engineering with the ambitious goals of its elite athletic audience.
Relevance: Leverages 'kinetic' to expertly link the brand to physical
energy. Audience appeal: 'Unlock your potential' resonates perfectly
with competitive runners. Tone consistency: Nails the required
aggressive, high-performance marks."
},
// ... Human evals for colorBrandFit and mottoToxicity:
}
}
Đạt được và đo lường mức độ đồng thuận của chuyên gia
Tiêu chí chấm điểm đóng vai trò là hướng dẫn cho mô hình, vì vậy, bạn cần dành thời gian để tinh chỉnh tiêu chí chấm điểm. Nếu một nhà thiết kế định nghĩa "vui tươi" là "ngôn ngữ sáng tạo" trong khi một nhà thiết kế khác diễn giải là "màu sắc tươi sáng", thì LLM của bạn cũng sẽ bị xung đột. Bạn phải củng cố tiêu chí chấm điểm để loại bỏ những điểm mơ hồ này trước khi đưa ra cho người đánh giá. Được gọi là độ tin cậy giữa các người gắn nhãn hoặc mức độ đồng thuận giữa các người đánh giá, mức độ đồng thuận cao đảm bảo mô hình người đánh giá của bạn cung cấp các nhãn đáng tin cậy và chất lượng cao.
Sự bất đồng của con người là những tín hiệu hữu ích cho bạn biết những điểm cần cải thiện trong tiêu chí chấm điểm của bạn. Lặp lại quy trình này cho đến khi các chuyên gia của bạn đồng ý về những trường hợp PASS và FAIL.
Mô hình đánh giá của bạn không thể phù hợp hơn những người đã tạo ra mô hình đó.
Thoả thuận cơ bản
Một cách để đo lường mức độ nhất trí giữa người với người (chúng tôi cũng đã sử dụng cách này cho điểm nhất trí của người đánh giá trong chương trình đánh giá cơ bản) là tỷ lệ phần trăm số lần các chuyên gia của chúng tôi nhất trí với nhau.
// total = all test cases
// aligned = test cases where human1Eval.label === human2Eval.label
// (for example PASS and PASS)
const alignment = (aligned / total) * 100;
Thoả thuận ngoài may rủi: Kappa
Thoả thuận về tỷ lệ phần trăm cơ bản rất đơn giản, nhưng có thể gây hiểu lầm. Hãy tưởng tượng một tập dữ liệu có 50% là PASS và 50% là FAIL. Nếu hai chuyên gia tung đồng xu, họ vẫn sẽ đồng ý 50% thời gian chỉ nhờ may mắn. Đây được gọi là mức sàn may mắn.
Để tính toán mức độ nhất trí một cách chính xác, hãy sử dụng các chỉ số thống kê đo lường độ tin cậy ngoài yếu tố ngẫu nhiên đơn thuần:
- Cohen's Kappa cho hai người gắn nhãn.
Kappa của Fleiss cho từ 3 người gắn nhãn trở lên.
Kiểm thử: Đặt mục tiêu đạt được điểm Kappa ít nhất là
0.61, đây là tiêu chuẩn cho mức độ nhất trí đáng kể. Điểm0có nghĩa là không tốt hơn so với đoán ngẫu nhiên và1.0là mức độ nhất trí hoàn hảo.Khắc phục: Nếu điểm Kappa của bạn nhỏ hơn
0.61, thì thang điểm của bạn quá mơ hồ. Nhóm các mẫu mà chuyên gia của bạn không đồng ý, xem xét lý do của họ, cập nhật bảng tiêu chí chấm điểm để bao gồm những trường hợp đặc biệt cụ thể đó, lặp lại cho đến khi bạn đạt được0.61. Chỉ chuyển sang bước tiếp theo khi các chuyên gia của bạn đã thống nhất.
| Điểm Kappa | Hành động |
|---|---|
Dưới 0.60: Kém |
Lặp lại và tìm hiểu lý do các chuyên gia nhìn nhận vấn đề theo cách khác. Có thể tiêu chí chấm điểm của bạn quá mơ hồ, vì vậy hãy tinh chỉnh tiêu chí chấm điểm. |
0.61 – 0.80: Tốt |
Đường cơ sở của bạn là đáng tin cậy. Tiếp tục sử dụng tiêu chí chấm điểm này. |
0.81-1.00 Gần như hoàn hảo |
Hấp dẫn đến mức khó tin. Xác minh xem nhiệm vụ có quá dễ hay không hoặc liệu các chuyên gia có đơn giản hoá quá mức hay không. |
Thu gọn nhãn chuyên gia
Nếu bạn sử dụng từ 3 chuyên gia trở lên để gắn nhãn dữ liệu, hãy gộp phiếu bầu của họ thành một điểm xếp hạng đa số duy nhất cho mỗi mẫu. Danh sách này sẽ trở thành thông tin thực tế của bạn.
Định cấu hình giám khảo
Giống như đối với người đánh giá cơ bản, bạn cần định cấu hình các tham số mô hình và viết câu lệnh. Đặt hướng dẫn cho hệ thống theo một tính cách chuyên gia nghiêm khắc và duy trì nhiệt độ ở mức 0 để đảm bảo tính nhất quán tối đa. Trong câu lệnh, hãy cung cấp chính xác bộ tiêu chí chấm điểm mà các chuyên gia đã dùng để chấm điểm dữ liệu. Thêm một vài mẫu được gắn nhãn chuyên gia làm ví dụ ít lượt để cho người đánh giá biết chính xác cách suy luận.
Căn chỉnh và kiểm tra trọng tài
Sau khi các chuyên gia của bạn đồng ý, bạn cần xem liệu mô hình ngôn ngữ lớn có đồng ý với họ hay không.
Trong chế độ thiết lập cơ bản, chúng ta đã xem xét sự căn chỉnh thô (độ chính xác). Nhưng chỉ dựa vào con số đó thì có thể bạn sẽ hiểu sai. Hãy tưởng tượng 90% dữ liệu kiểm thử của bạn là PASS. Một người đánh giá lười biếng có thể đưa ra kết quả PASS mọi lúc và đạt được độ chính xác 90% trong khi không phát hiện được một khẩu hiệu độc hại nào.
Xác định một lớp dương
Xác định hạng mục dương. Lớp dương tính, còn được gọi là điều kiện mục tiêu hoặc sự kiện quan tâm, là kết quả cụ thể mà bạn đang cố gắng phát hiện, đo lường hoặc gắn cờ. Quy trình đánh giá của bạn đóng vai trò là người kiểm soát: mục tiêu chính của quy trình này là phát hiện và chặn các kết quả đầu ra không phù hợp.
Giả sử ThemeBuilder thường tạo ra những khẩu hiệu và bảng màu phù hợp với thương hiệu, đồng thời khẩu hiệu độc hại cũng hiếm khi xuất hiện, thì hạng mục dương của bạn cho tất cả tiêu chí đánh giá là FAIL.
Lưu ý:
- Kết quả dương tính giả là những kết quả tốt bị gắn cờ nhầm là
FAIL. - Âm tính giả là những
FAILbị bỏ sót. - Trường hợp dương tính thực là những
FAILđược xác định chính xác.
Độ chính xác và độ thu hồi
Khi đã xác định được hạng mục dương, bạn có thể sử dụng độ chính xác và độ bao phủ. Đây là những chỉ số tốt hơn so với độ liên kết thô:
- Độ chính xác: khi giám khảo LLM nói
FAIL, tần suất giám khảo này nói đúng là bao nhiêu? Ví dụ: Khi thẩm phán gắn cờ một phương châm là độc hại, thì phương châm đó thực sự độc hại bao nhiêu lần? - Nhớ lại: khi người dùng nói
FAIL, LLM đã phát hiện được bao nhiêu lần? Ví dụ: Trong số tất cả những kết quả thực sự độc hại, và trong số tất cả những phương châm và bảng màu thực sự không phù hợp với thương hiệu, thì có bao nhiêu kết quả mà giám khảo phát hiện ra?
Tìm hiểu chi phí của lỗi + Đặt điểm số mục tiêu
Hãy tự hỏi: Lỗi nào sẽ gây ảnh hưởng xấu hơn cho đơn đăng ký của bạn?
- Nội dung độc hại: Nội dung độc hại là một vấn đề an toàn. Chúng tôi muốn phát hiện mọi khẩu hiệu độc hại (giảm thiểu trường hợp bỏ sót), ngay cả khi điều đó có nghĩa là hệ thống đánh giá của chúng tôi đôi khi quá nghiêm ngặt và gắn cờ một khẩu hiệu an toàn. Việc gắn cờ một phương châm an toàn (Dương tính giả) có nghĩa là sẽ có một chút chậm trễ hoặc cần có quy trình đánh giá thủ công. Vì vậy, chúng tôi hướng đến 100% Recall (Độ thu hồi 100%). Độ chính xác có thể thấp hơn.
- Mức độ phù hợp với thương hiệu: Chúng tôi cần có sự cân bằng. Cả việc bỏ lỡ những thiết kế xấu và từ chối những thiết kế tốt đều tốn kém như nhau. Vì vậy, chúng tôi muốn có Độ chính xác và Độ thu hồi cao.

Điểm F1
Khi độ thu hồi tăng lên, độ chính xác thường giảm xuống. Đối với nội dung độc hại, đó không phải là vấn đề vì bạn chỉ quan tâm đến độ chính xác.
Đối với mức độ phù hợp với thương hiệu, khả năng nhớ lại và độ chính xác đều quan trọng. Để cân bằng tầm quan trọng này, bạn có thể sử dụng một chỉ số mới: F1. Điểm F1 kết hợp độ chính xác và độ bao phủ thành một chỉ số cân bằng duy nhất.
Mức độ phù hợp của phạm vi tiếp cận
Chạy tiêu chí đánh giá của bạn dựa trên tập dữ liệu được gắn nhãn bởi chuyên gia và tính toán độ chính xác, độ chuẩn xác, độ thu hồi và điểm F1 cho từng tiêu chí. Đánh giá xem bạn có đang đạt được mục tiêu của mình hay không.
Nếu không, hãy nhóm các trường hợp thất bại và đọc lý do của LLM. Cập nhật hướng dẫn hệ thống và tiêu chí chấm điểm của người đánh giá để thu hẹp khoảng cách cho đến khi các chỉ số đạt được mục tiêu của bạn.
Khi trọng tài đạt được mục tiêu, trọng tài của bạn sẽ được điều chỉnh.
Xác thực lần cuối
Giờ đây, chúng ta sẽ xác thực judge bằng chính các bước mà chúng ta đã đề cập trong phần thiết lập judge cơ bản, nhưng áp dụng các chỉ số nâng cao mới của bạn:
- Kiểm tra hiệu suất bằng phương pháp khởi động lại: Lấy mẫu lại ngẫu nhiên tập dữ liệu của bạn có thay thế trong 10 lần lặp. Tính phương sai của độ chính xác, độ bao phủ và điểm F1 trong các lần chạy này để chứng minh bằng toán học rằng điểm số cao của bạn không chỉ là do may mắn.
- Kiểm thử tính nhất quán của chính nó: Chạy chính xác các đầu vào thông qua trình đánh giá nhiều lần để đảm bảo kết quả của trình đánh giá ổn định 100%. Chúng tôi muốn không có sự khác biệt trong tất cả các lần lặp lại.
- Cho người đánh giá làm bài kiểm tra cuối kỳ: Kiểm tra người đánh giá trên một nhóm gồm 15 đến 20 mẫu mới, được chuyên gia gắn nhãn mà người đánh giá chưa từng thấy trước đây. Tính Cohen's Kappa, độ chính xác, độ thu hồi và điểm F1 trên tập hợp ẩn này. Nếu các chỉ số này vẫn gần nhau, điều đó chứng tỏ mô hình đánh giá của bạn chưa được điều chỉnh quá mức cho dữ liệu liên kết và sẵn sàng khái quát hoá cho thế giới thực!
Điều chỉnh vị trí của thẩm phán
Sau khi hoàn tất, xin chúc mừng! Bạn đã xây dựng một quy trình đánh giá có độ tin cậy cao.
Hãy nhớ điều chỉnh lại mô hình đánh giá bất cứ khi nào bạn cập nhật LLM (mô hình ngôn ngữ lớn) cơ bản mà mô hình đó dựa vào hoặc khi tập tính chất của ứng dụng thay đổi cơ bản.