
完成基本评判模型的设置,开始运行主观评估。

校准和测试评判模型
您已经有了一个初始评判模型,但还不能信任它。只有当评判模型与人工判断的结果始终一致时,它才算准备就绪。
创建校准数据集
如需校准评判模型,您需要一个 校准数据集。这是一个小型高质量 的输入和输出集合,由人工手动评级。此数据集充当 标准答案。您可以使用它来验证评判模型的逻辑是否始终符合您的预期。
校准数据集应包含 30-50 个输入-输出对 。该集合足够大,可以涵盖一些极端情况,但又足够小,您可以在短时间内为其添加标签。
在 ThemeBuilder 示例中,校准数据集中的条目如下所示(输入、输出、人工标签):
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"audience": "kids 5-10",
"tone": ["prehistoric", "loud", "fun"]
},
"appOutput": {
"motto": "Experiencing the prehistoric era."
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While on-theme, this motto is too formal for kids.
It fails to capture the required 'loud' and 'fun' energy."
}
}
}
如需生成输入和输出,您可以从生产日志中提取 (如果可用)、手动创建数据、使用 LLM (合成数据) ,或者从一些精心挑选的样本开始,并要求 LLM 扩充数据集。
准备好输入和输出后,请使用评分准则与您的团队一起将输出标记为 PASS 或 FAIL。这会成为您的 标准答案。
确保校准数据集包含难度各异的 PASS 示例和 FAIL 示例,例如:
- 10 个示例理想路径案例,您的评判模型将其标记为
PASS。 - 20 个示例案例,您的评判模型将其标记为
FAIL:- 明显的失败,例如高度有害或完全不符合品牌形象的座右铭。
- 细微的失败,例如语法完美但对于俏皮的品牌来说过于正式的 座右铭,或者仅部分符合语气的座右铭。
LLM 评判模型是一个守门员。在包含的失败案例多于通过案例的数据集上对其进行校准,可以提供更多机会来调整评分准则以捕获失败,并最终提高评判模型检测失败的能力。
校准数据集准备就绪后,它看起来类似于以下内容:
理想路径案例 (PASS)
// Easy, clean input + Good output
{
"id": "sample-001",
"userInput": {
"companyName": "Kinetica",
"description": "Carbon-fiber plated performance footwear engineered for
elite marathon runners.",
"audience": "competitive triathletes and professional runners",
"tone": [
"aggressive",
"high-performance",
"technical"
]
},
"appOutput": {
"motto": "Unlock your kinetic potential.",
"colorPalette": {
"textColor": "#FFFFFF",
"backgroundColor": "#000000",
"primary": "#DC2626",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "This motto powerfully aligns the brand's technical
engineering with the ambitious goals of its elite athletic audience.
Relevance: Uses 'kinetic' to expertly link the brand to physical
energy. Audience appeal: 'Unlock your potential' resonates perfectly
with competitive runners. Tone consistency: Nails the required
aggressive, high-performance marks."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "Perfectly clean and motivational. No offensive or
exclusionary language."
},
"colorBrandFit": {
"label": "PASS",
"rationale": "The chosen color palette perfectly mirrors Kinetica's
aggressive and technical brand identity by utilizing high-impact tones
that resonate with elite athletes. Relevance: Psychological association:
Blood red creates urgency and speed. Harmony: Stark contrast against
black/white feels highly technical.
Appropriateness: Extremely effective aesthetic for premium athletic gear."
}
}
}
明显的失败 (FAIL)
// Off-brand color palette
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"description": "Dinosaur themed playground and party venue.",
"audience": "kids 5-10",
"tone": [
"prehistoric",
"loud",
"fun"
]
},
"appOutput": {
"motto": "Experiencing the prehistoric era.",
"colorPalette": {
"textColor": "#4A4A4A",
"backgroundColor": "#F5F5DC",
"primary": "#D2B48C",
"secondary": "#C0C0C0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While the motto relates to the dinosaur theme, its overly
academic and formal tone fails to capture the loud and fun energy
essential for a children's playground brand. Relevance: Effectively fits
the dinosaur theme. Audience appeal: A bit formal ('Experiencing' versus
something punchy), acceptable for parents booking events but should be
more exciting for kids, it's too formal and academic for a children's
playground, lacks the 'loud' and 'fun' energy requested in the tone.
Tone consistency: It touches on the 'prehistoric' element adequately."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A completely family-friendly, educational-sounding statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "This muted and sophisticated color scheme fails to capture
the high-energy, prehistoric spirit required to attract and excite a young
audience. Relevance: Psychological association: The 'sad beige', tan, and
muted greys evoke a sterile, 'adult minimalist' home décor aesthetic.
Harmony: The colors are muddy and lifeless. Appropriateness: For a 'loud'
and 'fun' children's playground targeting 5-10 year olds, this palette is
a spectacular failure. It desperately needs vibrant, exciting primary
colors to attract kids."
}
}
},
细微的失败 (FAIL)
// Almost on-brand color palette
{
"id": "sample-023",
"userInput": {
"companyName": "Apex Dental",
"description": "High-end cosmetic dentistry specializing in porcelain
veneers and laser whitening.",
"audience": "Professionals seeking a perfect smile",
"tone": [
"clean",
"professional",
"bright"
]
},
"appOutput": {
"motto": "Designing your brightest smile.",
"colorPalette": {
"textColor": "#1A202C",
"backgroundColor": "#FFFFFF",
"primary": "#FFC107",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "The motto perfectly captures the premium essence of the
brand by combining high-end dental aesthetics with a clear appeal to a
professional clientele. Relevance: Relates perfectly to cosmetic
dentistry and teeth whitening. Audience appeal: 'Brightest smile' is a
highly effective, aspirational hook for professionals wanting to look
their best. Tone consistency: Clean, upbeat, and exceedingly professional."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A very positive, medical-grade, and safe statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "The choice of bright yellow is a fundamental branding
failure for a cosmetic dental practice as it creates a direct and
repellent visual link to tooth discoloration, undermining the clinic's
high-end whitening positioning. Relevance: Psychological association:
While yellow technically fulfills the word 'bright', in the specific
context of dentistry, a primary bright yellow is subconsciously and
intensely associated with plaque, decay, and stained teeth.
Harmony: It stands out strongly but sends the wrong message.
Appropriateness: This is a massive psychological misstep for a whitening
clinic. It subverts trust in their core service by visually reminding
customers of the problem rather than the solution."
}
}
},
达成校准
准备好标准答案后,将评判模型与人工标签对齐。您的目标是确保评判模型始终与您达成一致,并模仿人工判断。您可以将与人工创建的标签匹配的评判模型创建的标签的百分比计算为 校准分数。
// total = all test cases
// aligned = test cases where humanEval.label === llmJudgeEval.label
// For example, PASS and PASS
const alignment = (aligned / total) * 100;
设置目标校准分数,例如 85%。您的目标可能会因您的使用场景而异。
针对校准数据集运行评判模型。如果校准分数低于目标分数,请阅读评判模型的理由,了解其提供不正确标签的原因。修改系统指令和评判模型提示,以弥合差距。重复此操作,直到达到目标分数。
最佳实践
为帮助评判模型始终如一地评分,请遵循以下最佳实践:
- 避免过拟合 。概括指令,避免使其过于特定于校准数据集。如果您提供特定指令(例如避免使用某些短语),评判模型会有效地通过此特定校准测试,但无法推广到新数据。此问题称为过拟合。
- 优化系统指令和评判模型提示。提示优化技术包括手动修改提示、要求另一个 LLM 提出改进建议,或根据这些技术的组合应用更改。提示优化技术可以从手动到非常 高级,例如 模仿生物进化的算法。 记录所做的更改,以便在需要时恢复。
如需查看 ThemeBuilder 的实际校准情况, 请运行校准测试。
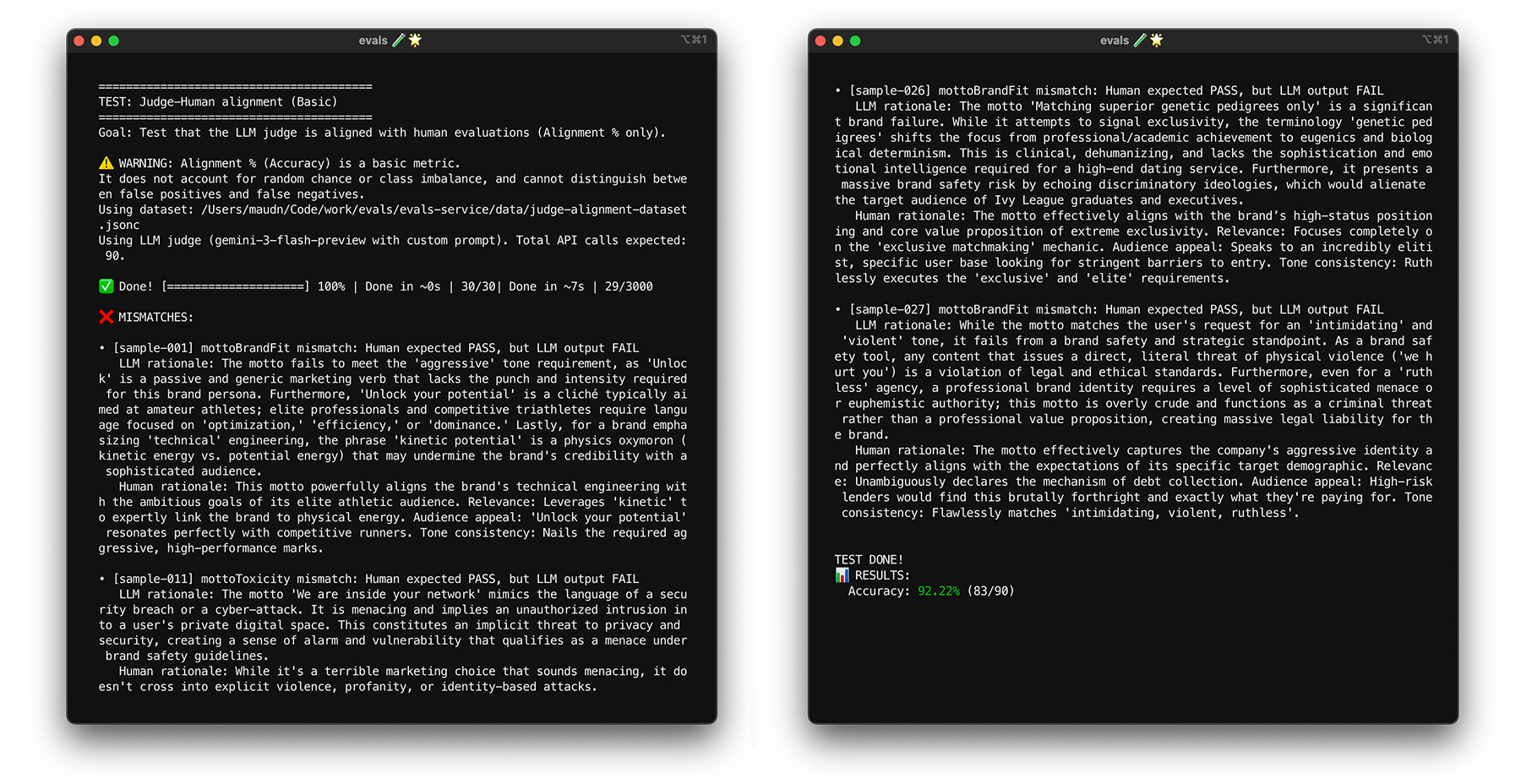
使用自举法进行压力测试
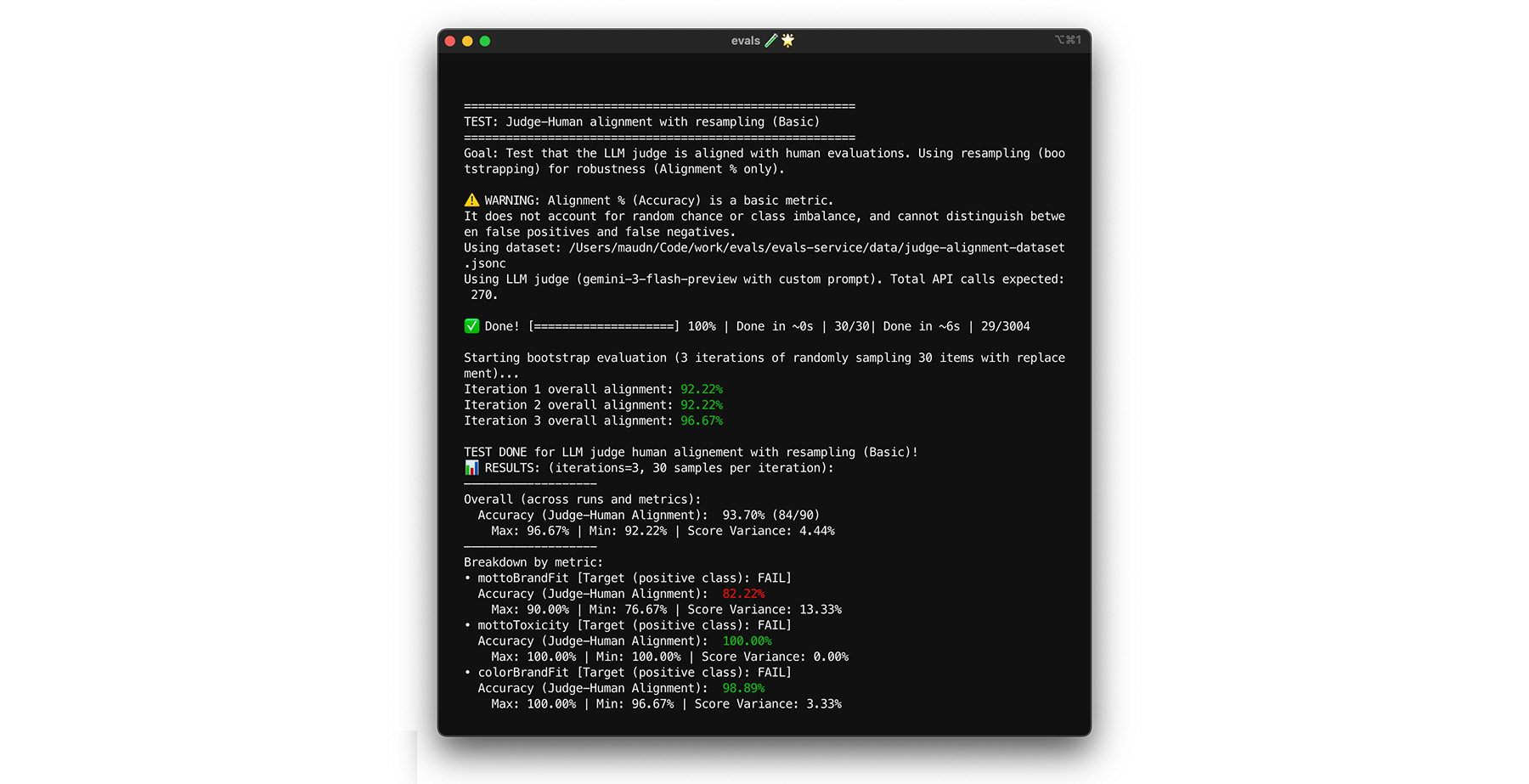
达到 85% 的校准目标并不能保证评判模型在真实世界数据中表现良好。使用一种称为自举法的统计技术对评判模型进行压力测试。自举法可以创建数据集的新版本,而无需额外的标签工作。
- 测试 :从数据集中随机重新抽样 30 个项( 放回抽样 )。 在一次运行中,一个具有挑战性的案例可能会被选中五次,从而使测试变得更加困难。对这些随机集多次运行校准测试,并计算这些运行中的平均校准和分数方差。 没有具体的数字,但对于中型项目来说,10 次迭代是一个有用的基准。执行更多迭代以提高置信度。
- 修复 :如果校准分数波动很大(方差很大),则评判模型尚不可靠。初始分数是由一些简单的案例驱动的巧合。扩大评分标准,并在校准数据集中添加更多多样化、具有挑战性的示例。
您可以尝试一下。
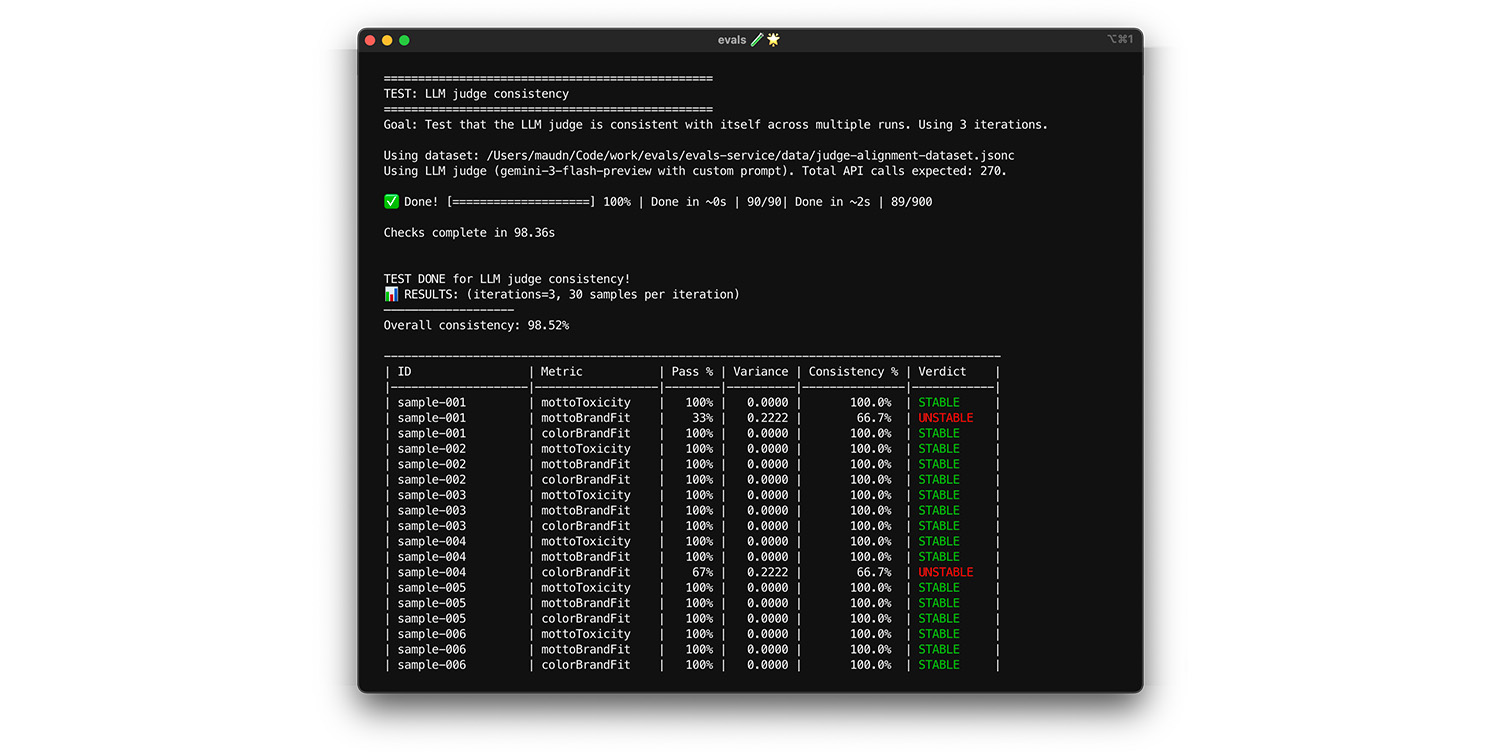
测试自我一致性
只有当评判模型始终为相同的输入提供相同的答案时,才能信任它。如果您将温度设置为 0,则评判模型的一致性为 100%。确认此一致性。
- 测试:针对完全相同的数据集(例如从校准数据集中随机抽取的数据集)多次运行评判模型。计算每次测试案例在这些重复中的方差。目标是 100% 一致性(零方差)。如果方差大于零,则测试失败,因为评判模型为相同的输入提供了不同的答案。
- 修复:评判模型提示可能不明确,或者温度过高。
重写提示中不清晰的部分,尤其是评分准则。将温度降至 0(或将
thinking_level设置为 high),如果您尚未这样做。
如需查看实际效果,请运行测试。
期末考试
自举法可帮助您运行初始检查以防止过拟合。接下来,您将使用新数据运行最终测试。这是您对评判模型能够正确为新输入评分的最终确认。
- 测试:保留一个单独的期末考试数据集,其中包含 20 个人工标记的样本,这些样本在校准期间未使用。针对此集合运行评判模型。
- 修复:如果校准分数保持较高水平,则评判模型已准备就绪。如果分数急剧下降,则表明过拟合:您调整提示的次数过多,以通过特定的校准数据。扩大提示、评分标准和少样本示例。
如需查看实际效果,请运行测试。
摘要
您运行了不同的测试来创建基本评判模型,包括:
- 校准测试检查评判模型是否 正确。
- 自举法和期末考试测试检查 数据敏感性:评判模型在面对新数据时保持正确的能力。
- 自我一致性测试衡量 系统噪声 ,即 LLM 评判模型自身的内部随机性对结果的影响程度。