
用于构建 AI 测试流水线的应用工程提示。

Maud Nalpas
您已设计好评分标准、编写好基于规则的评估,并对齐了裁判模型。现在,是时候将所有这些内容整合到自动化持续测试流水线中了。
每个项目都不尽相同。本模块将介绍一种有效的分层方法来构建评估流水线。
如需构建评估流水线,您需要具备以下条件:
- 评估者的编排器
- 一种用于处理多个 API 调用并解决潜在故障的策略
- 标准化的输出格式
- 报告界面
编排 API 调用

创建一个主函数来编排基于规则的评估器和 LLM 评分器评估器。
查看示例代码中的 evalAll()。
将 LLM 评判器配置(系统指令、结构化输出逻辑和重试)集中到一个实用函数中,以便在评估器中重复使用。查看示例代码中的 evalWithLLM()。
处理模型 API 过载和故障
模型 API 有时会过载或超时。如果 API 调用失败,请触发自动重试。重试次数用完后,请报告 ERROR。报告评估 FAIL 会使结果出现偏差。
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
运行评估时,请从以下选项中进行选择:
- 并行进行 API 调用,这样一次评估超时就不会导致其他评估崩溃。根据您的使用场景和判断模型,这可以减少幻觉,因为判断模型专注于一项任务。
- 进行一次批处理调用。这会造成单点故障,例如,如果模型超出其 token 限制。
为多次迭代做好准备
由于 LLM 具有不确定性,因此您的应用输出会有所不同。
为了准确测试这一点,并确信输出结果符合您的质量标准,请执行以下操作:
- 针对每个测试用例输入生成多条输出(通常为 5 到 10 条)。
- 分别评估每个输出。
- 检查各次迭代的总体结果。
找到实用的平衡点:更多迭代次数可提高回归确定性,但更少的迭代次数可确保执行速度足够快,从而无缝融入持续测试流水线。
定义评估流水线输出
在评估结果中包含以下信息:
- 稳定性比率,例如通过 10 次中的 8 次 → 稳定性为 80%。设置阈值,以衡量功能何时可用于生产环境。
- 您的应用配置。这包括系统指令、用户提示和 LLM 参数,例如温度或思考水平。您需要此信息来排查评估分数回归问题。提示可以是略有不同的长字符串,因此请为提示添加版本号并存储其哈希值,以便进行跟踪。
- 评判配置或版本号。如果评分在法官更新后出现巨大变化,您需要此文件。
以下是 ThemeBuilder 评估的 EvalResponse JSON 对象示例:
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
实现报告接口
将结果输出到 HTML 报告或简洁的 Web 界面,以便解析、分享、比较和调试一段时间内的结果。
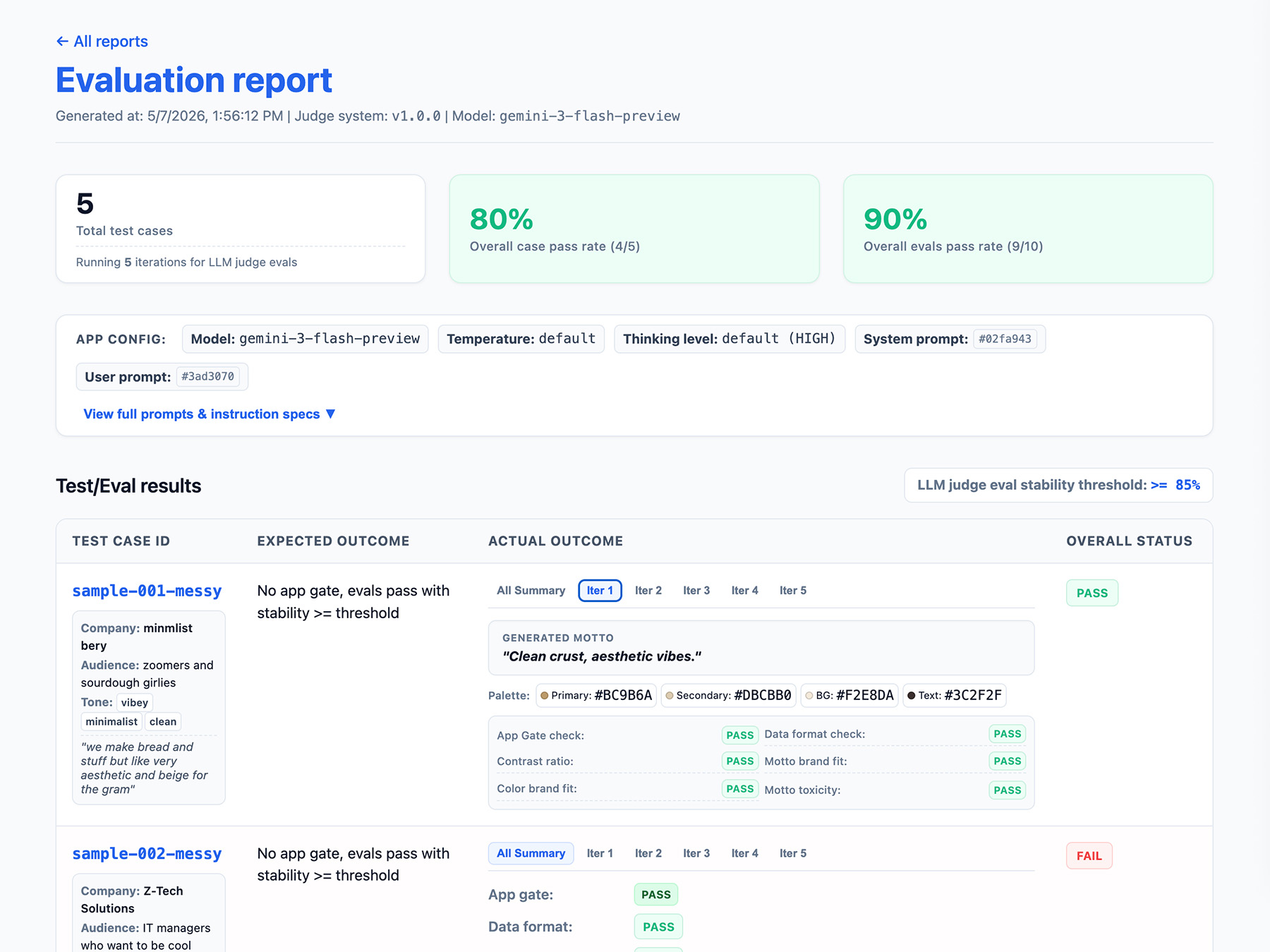

现在,运行评估。