
نصائح هندسية تطبيقية لإنشاء مسار اختبار الذكاء الاصطناعي

لقد صمّمت مقاييس التقييم، وكتبت التقييمات المستندة إلى القواعد، وربطت نموذج التقييم الخاص بك. حان الوقت الآن لربط كل ذلك معًا في مسار اختبار آلي ومستمر.
يختلف كل مشروع عن الآخر. توضّح هذه الوحدة طريقة فعّالة ومتعدّدة الطبقات لإنشاء مسار تقييم.
لإنشاء مسار تقييم، يجب توفُّر ما يلي:
- منسّق للمقيّمين
- استراتيجية للتعامل مع طلبات بيانات متعددة من واجهة برمجة التطبيقات ومعالجة حالات الأعطال المحتملة
- تنسيق إخراج موحّد
- واجهة إعداد التقارير
تنظيم طلبات البيانات من واجهة برمجة التطبيقات

أنشئ دالة رئيسية لتنظيم أدوات التقييم المستندة إلى القواعد وأدوات التقييم المستندة إلى نماذج اللغات الكبيرة.
راجِع evalAll() في
نموذج الرمز.
يمكنك توسيط إعدادات الحكم في النماذج اللغوية الكبيرة (تعليمات النظام، ومنطق الإخراج المنظَّم، وعمليات إعادة المحاولة) في دالة مساعدة واحدة يمكنك إعادة استخدامها في جميع أدوات التقييم. راجِع evalWithLLM() في
نموذج الرمز.
التعامل مع حالات التحميل الزائد والأخطاء في واجهة برمجة التطبيقات الخاصة بالنماذج
قد يتم تحميل واجهات برمجة التطبيقات الخاصة بالنماذج بشكل زائد أو تنتهي مهلتها في بعض الأحيان. إذا تعذّر تنفيذ طلب البيانات من واجهة برمجة التطبيقات، ابدأ تلقائيًا في إعادة المحاولة. بعد استنفاد عدد محاولات إعادة التشغيل، يُرجى الإبلاغ عن ERROR. سيؤدي الإبلاغ عن تقييم FAIL إلى تشويه نتائجك.
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
عند إجراء عمليات التقييم، يمكنك الاختيار من بين الخيارات التالية:
- يمكنك إجراء طلبات البيانات من واجهة برمجة التطبيقات بالتوازي كي لا يؤدي انتهاء المهلة المحدّدة لأحد التقييمات إلى تعطيل التقييمات الأخرى. واعتمادًا على حالة الاستخدام ونموذج التقييم، يمكن أن يؤدي ذلك إلى تقليل الهلوسات لأنّ نموذج التقييم يركّز على مهمة واحدة.
- إجراء طلب واحد مجمّع يؤدي ذلك إلى إنشاء نقطة فشل واحدة، مثلاً إذا تجاوز النموذج الحد الأقصى لعدد الرموز المميّزة.
الاستعداد لتكرار العملية عدة مرات
بما أنّ النماذج اللغوية الكبيرة غير حتمية، يختلف الناتج الذي يظهر في تطبيقك.
لاختبار ذلك بدقة والتأكّد من أنّ المخرجات تستوفي معايير الجودة، اتّبِع الخطوات التالية:
- إنشاء نتائج متعددة (عادةً من 5 إلى 10) لكل إدخال من حالات الاختبار
- قيِّم كل ناتج على حدة.
- فحص النتائج الإجمالية على مستوى التكرارات
ابحث عن توازن عملي: يؤدي إجراء المزيد من التكرارات إلى زيادة دقة تحديد المشاكل، ولكن يؤدي إجراء عدد أقل من التكرارات إلى الحفاظ على سرعة التنفيذ بما يكفي ليتناسب بسلاسة مع مسار الاختبار المتواصل.
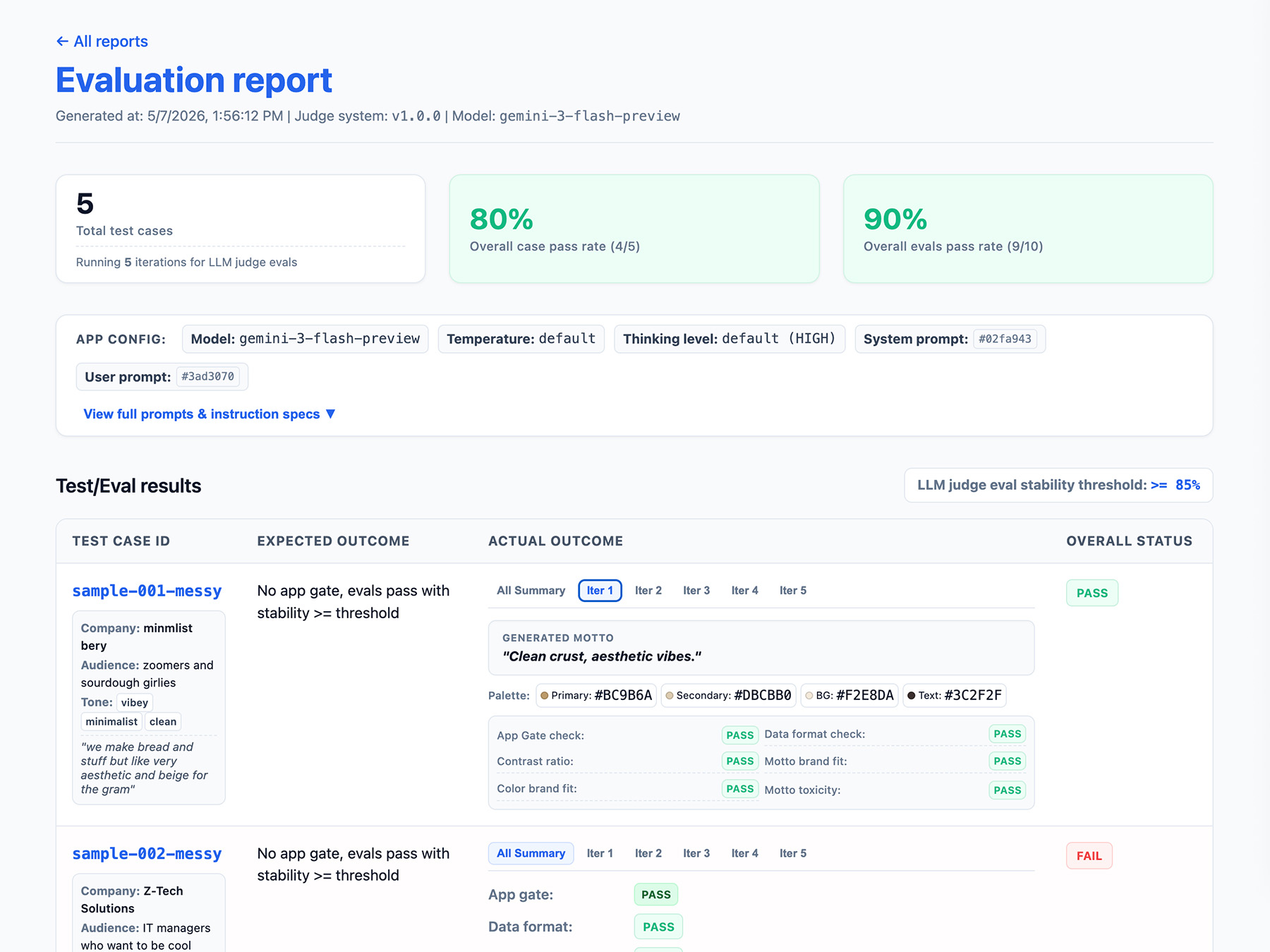
تحديد ناتج مسار التقييم
يجب تضمين ما يلي في نتائج التقييم:
- معدّل الثبات، على سبيل المثال، تم اجتياز الاختبار 8 مرات من أصل 10 مرات → معدّل الثبات 80%. ضَع حدًا أدنى لقياس الوقت الذي تصبح فيه إحدى الميزات جاهزة للإصدار العلني.
- إعدادات التطبيق ويشمل ذلك تعليمات النظام وطلب المستخدم ومَعلمات النموذج اللغوي الكبير، مثل درجة العشوائية أو مستوى التفكير. تحتاج إلى هذه المعلومات لتحديد المشاكل وحلّها في انخفاض نتائج التقييمات. يمكن أن تكون الطلبات سلاسل طويلة مع اختلافات طفيفة، لذا أضِف رقم إصدار إلى طلباتك وخزِّن تجزئة لها لتتبُّعها.
- إعدادات القاضي أو رقم الإصدار تحتاج إلى ذلك في حال تغيّرت نتيجتك بشكل كبير بعد تعديلها من قِبل أحد الحكّام.
في ما يلي مثال على عنصر JSON EvalResponse لعمليات تقييم ThemeBuilder:
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
تنفيذ واجهة إعداد تقارير
يمكنك إخراج النتائج في تقرير HTML أو واجهة مستخدم ويب نظيفة لتحليل النتائج ومشاركتها ومقارنتها وتصحيح أخطائها بمرور الوقت.

الآن، نفِّذ عمليات التقييم.