
نکات مهندسی کاربردی برای ساخت خط تولید تست هوش مصنوعی شما.

شما روبریکهای خود را طراحی کردهاید، ارزیابیهای مبتنی بر قانون خود را نوشتهاید و مدل قضاوت خود را همسو کردهاید. اکنون زمان آن رسیده است که همه اینها را در یک خط لوله آزمایش خودکار و مداوم قرار دهید.
هر پروژه متفاوت است. این ماژول یک رویکرد مؤثر و لایهای برای ساخت خط ارزیابی شما را تشریح میکند.
برای ساخت خط لوله ارزیابی خود، به موارد زیر نیاز دارید:
- یک هماهنگکننده برای ارزیابان شما
- یک استراتژی برای مدیریت چندین فراخوانی API و رفع خطاهای احتمالی
- فرمت خروجی استاندارد
- رابط گزارشدهی
هماهنگسازی فراخوانیهای API

یک تابع اصلی برای هماهنگ کردن ارزیابهای مبتنی بر قانون و LLM خود ایجاد کنید. evalAll() در کد مثال مرور کنید.
پیکربندی داور LLM خود (دستورالعملهای سیستم، منطق خروجی ساختاریافته و تلاشهای مجدد) را در یک تابع کاربردی واحد که میتوانید در بین ارزیابهای خود از آن استفاده مجدد کنید، متمرکز کنید. تابع evalWithLLM() را در کد مثال مرور کنید.
مدیریت اضافه بار و خرابیهای API مدل
گاهی اوقات APIهای مدل دچار اضافه بار یا timeout میشوند. اگر فراخوانی API شما با شکست مواجه شد، یک تلاش مجدد خودکار را فعال کنید. به محض اینکه تعداد تلاشها تمام شد، یک ERROR گزارش دهید. گزارش eval FAIL نتایج شما را منحرف میکند.
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
هنگام اجرای ارزیابیها، از بین گزینههای زیر یکی را انتخاب کنید:
- فراخوانیهای API خود را به صورت موازی انجام دهید تا وقفه در یک ارزیابی، بقیه را از کار نیندازد. بسته به مورد استفاده و مدل قاضی شما، این میتواند توهمات را کاهش دهد زیرا قاضی روی یک کار تمرکز میکند.
- یک فراخوانی دستهای و واحد انجام دهید. این کار یک نقطه شکست واحد ایجاد میکند، برای مثال اگر مدل از حد توکن خود فراتر رود.
برای تکرارهای متعدد آماده شوید
از آنجا که LLM ها غیر قطعی هستند، خروجی برنامه شما متفاوت است.
برای آزمایش دقیق این موضوع و ایجاد اطمینان از اینکه خروجی مطابق با استاندارد کیفی شما است:
- برای هر ورودی مورد آزمون، چندین خروجی (معمولاً ۵ تا ۱۰) تولید کنید.
- هر خروجی را جداگانه ارزیابی کنید.
- نتایج کلی را در طول تکرارها بررسی کنید.
یک تعادل عملی پیدا کنید: تکرارهای بیشتر، قطعیت رگرسیون را افزایش میدهند، اما تکرارهای کمتر، سرعت اجرا را به اندازهای حفظ میکنند که به طور یکپارچه در خط لوله آزمایش مداوم شما جای گیرد.
خروجی خط لوله ارزیابی خود را تعریف کنید
موارد زیر را در نتایج ارزیابی خود لحاظ کنید:
- نرخ پایداری ، برای مثال، 8 بار از 10 بار قبول شده → 80٪ پایدار. یک آستانه برای اندازهگیری زمان آماده شدن یک ویژگی برای تولید تعیین کنید.
- پیکربندی برنامه شما. این شامل دستورالعملهای سیستم، اعلان کاربر و پارامترهای LLM مانند دما یا سطح تفکر است. شما به این اطلاعات برای عیبیابی رگرسیونهای امتیاز eval نیاز دارید. اعلانها میتوانند رشتههای طولانی با تغییرات جزئی باشند، بنابراین یک شماره نسخه به اعلانهای خود اضافه کنید و یک هش از آنها را برای پیگیری ذخیره کنید.
- پیکربندی داور شما، یا شماره نسخه. در صورتی که امتیاز شما پس از بهروزرسانی داور به شدت تغییر کند، به این مورد نیاز دارید.
در اینجا یک مثال از شیء JSON EvalResponse برای ارزیابیهای ThemeBuilder آورده شده است:
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
پیادهسازی رابط گزارشگیری
نتایج خود را به صورت یک گزارش HTML یا یک رابط کاربری وب ساده خروجی بگیرید تا بتوانید نتایج را در طول زمان تجزیه، اشتراکگذاری، مقایسه و اشکالزدایی کنید.
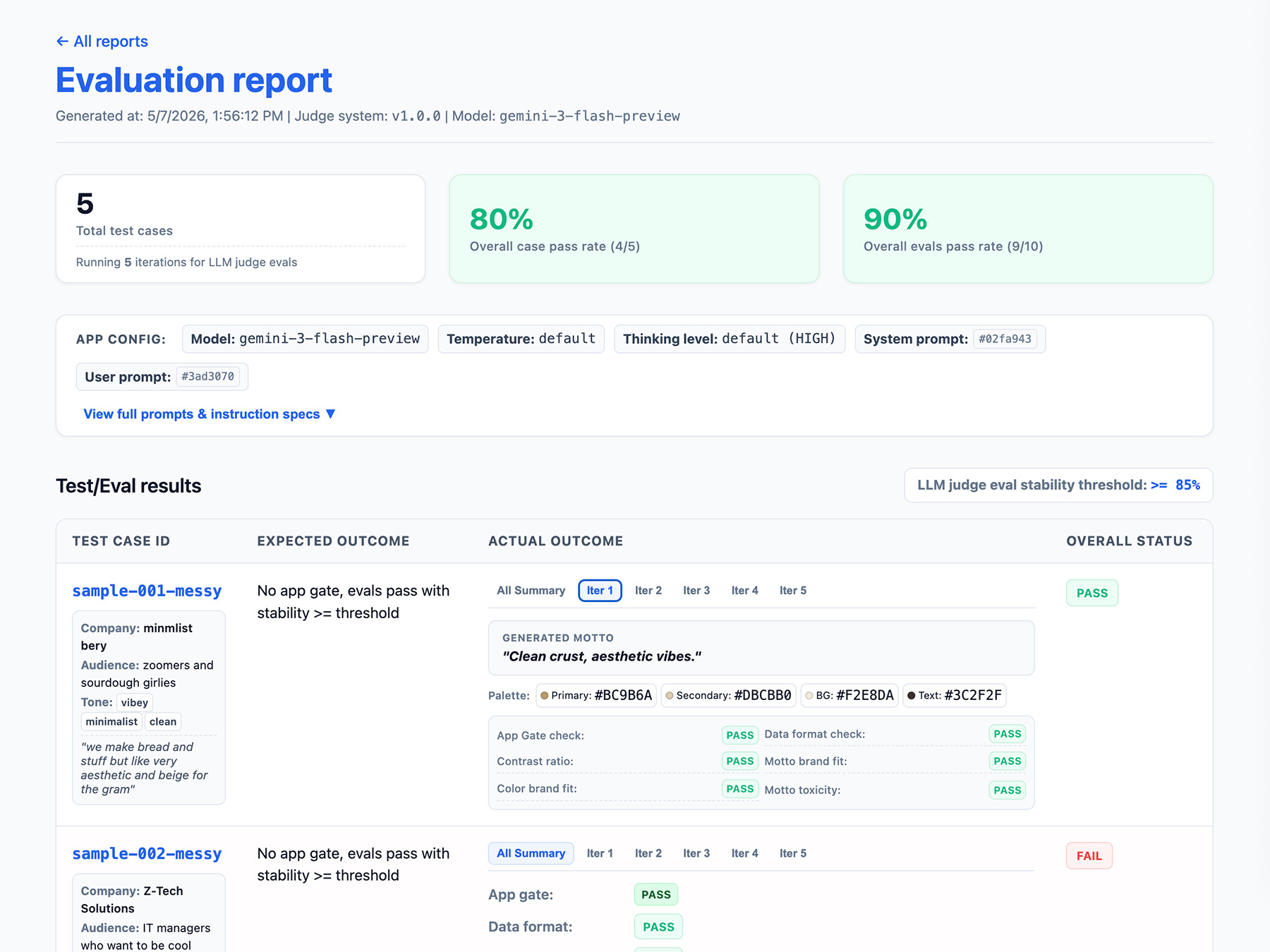

حالا، ارزیابیهای خود را اجرا کنید .