
برای شروع ارزیابیهای ذهنی، مدل قضاوت اولیه خود را راهاندازی کنید.

قاضی را همتراز و آزمایش کنید
شما یک قضاوت اولیه دارید، اما هنوز نمیتوانید به آن اعتماد کنید. قضاوت شما فقط زمانی آماده است که به طور مداوم با قضاوت انسانی موافق باشد.
ایجاد یک مجموعه داده همترازی
برای کالیبره کردن قاضی خود، به یک مجموعه داده همترازی نیاز دارید. این مجموعه، مجموعهای کوچک و باکیفیت از ورودیها و خروجیهایی است که انسانها به صورت دستی آنها را ارزیابی کردهاند. این مجموعه داده به عنوان حقیقت پایه شما عمل میکند. شما از آن برای تأیید اینکه منطق قاضی به طور مداوم با انتظارات شما همسو است، استفاده میکنید.
مجموعه دادههای همترازی شما باید شامل ۳۰ تا ۵۰ جفت ورودی-خروجی باشد. این مجموعه به اندازه کافی بزرگ است که برخی از موارد مرزی را پوشش دهد، اما به اندازه کافی کوچک است که بتوانید در مدت زمان کوتاهی آن را برچسبگذاری کنید.
در مثال ThemeBuilder، یک ورودی در مجموعه دادههای ترازبندی به این شکل است (ورودی، خروجی، برچسب انسانی):
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"audience": "kids 5-10",
"tone": ["prehistoric", "loud", "fun"]
},
"appOutput": {
"motto": "Experiencing the prehistoric era."
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While on-theme, this motto is too formal for kids.
It fails to capture the required 'loud' and 'fun' energy."
}
}
}
برای تولید ورودیها و خروجیها، میتوانید از لاگهای تولید (در صورت وجود) استخراج کنید، دادهها را به صورت دستی ایجاد کنید، از یک LLM ( دادههای مصنوعی ) استفاده کنید، یا از چند نمونه انتخاب شده شروع کنید و از یک LLM بخواهید مجموعه دادههای شما را افزایش دهد.
وقتی ورودیها و خروجیهایتان آماده شد، با استفاده از روبریک (یا جدول) خود، خروجیها را با تیمتان به صورت PASS یا FAIL برچسبگذاری کنید. این به حقیقتِ بنیادین شما تبدیل میشود.
مطمئن شوید که مجموعه دادههای همترازی شما شامل نمونههای PASS و FAIL با سختیهای مختلف باشد، برای مثال:
- ۱۰ نمونه از پروندههای مسیر شاد که قاضی شما آنها را
PASSمیداند. - ۲۰ نمونه پرونده که قاضی شما آنها را
FAILاعلام میکند:- شکستهای آشکار ، برای مثال یک شعار بسیار سمی یا کاملاً نامرتبط با برند.
- شکستهای نامحسوس ، برای مثال شعاری که از نظر دستوری بینقص است اما برای یک برند شوخطبع کمی بیش از حد رسمی است، یا شعاری که فقط تا حدی با لحن و لحن همخوانی دارد.
قاضی LLM شما یک دروازهبان است. همتراز کردن آن با مجموعه دادههایی که تعداد موارد ناموفق آن از موارد موفق بیشتر است، فرصتهای بیشتری برای تنظیم روبریک جهت شناسایی موارد ناموفق فراهم میکند و در نهایت توانایی قاضی را در تشخیص موارد ناموفق بهبود میبخشد.
بعد از اینکه مجموعه دادههای ترازبندی شما آماده شد، چیزی شبیه به این خواهد بود:
موارد مسیر شاد (قابل قبول)
// Easy, clean input + Good output
{
"id": "sample-001",
"userInput": {
"companyName": "Kinetica",
"description": "Carbon-fiber plated performance footwear engineered for
elite marathon runners.",
"audience": "competitive triathletes and professional runners",
"tone": [
"aggressive",
"high-performance",
"technical"
]
},
"appOutput": {
"motto": "Unlock your kinetic potential.",
"colorPalette": {
"textColor": "#FFFFFF",
"backgroundColor": "#000000",
"primary": "#DC2626",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "This motto powerfully aligns the brand's technical
engineering with the ambitious goals of its elite athletic audience.
Relevance: Uses 'kinetic' to expertly link the brand to physical
energy. Audience appeal: 'Unlock your potential' resonates perfectly
with competitive runners. Tone consistency: Nails the required
aggressive, high-performance marks."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "Perfectly clean and motivational. No offensive or
exclusionary language."
},
"colorBrandFit": {
"label": "PASS",
"rationale": "The chosen color palette perfectly mirrors Kinetica's
aggressive and technical brand identity by utilizing high-impact tones
that resonate with elite athletes. Relevance: Psychological association:
Blood red creates urgency and speed. Harmony: Stark contrast against
black/white feels highly technical.
Appropriateness: Extremely effective aesthetic for premium athletic gear."
}
}
}
شکستهای آشکار (FAIL)
// Off-brand color palette
{
"id": "sample-014",
"userInput": {
"companyName": "Rawrr!",
"description": "Dinosaur themed playground and party venue.",
"audience": "kids 5-10",
"tone": [
"prehistoric",
"loud",
"fun"
]
},
"appOutput": {
"motto": "Experiencing the prehistoric era.",
"colorPalette": {
"textColor": "#4A4A4A",
"backgroundColor": "#F5F5DC",
"primary": "#D2B48C",
"secondary": "#C0C0C0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "FAIL",
"rationale": "While the motto relates to the dinosaur theme, its overly
academic and formal tone fails to capture the loud and fun energy
essential for a children's playground brand. Relevance: Effectively fits
the dinosaur theme. Audience appeal: A bit formal ('Experiencing' versus
something punchy), acceptable for parents booking events but should be
more exciting for kids, it's too formal and academic for a children's
playground, lacks the 'loud' and 'fun' energy requested in the tone.
Tone consistency: It touches on the 'prehistoric' element adequately."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A completely family-friendly, educational-sounding statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "This muted and sophisticated color scheme fails to capture
the high-energy, prehistoric spirit required to attract and excite a young
audience. Relevance: Psychological association: The 'sad beige', tan, and
muted greys evoke a sterile, 'adult minimalist' home décor aesthetic.
Harmony: The colors are muddy and lifeless. Appropriateness: For a 'loud'
and 'fun' children's playground targeting 5-10 year olds, this palette is
a spectacular failure. It desperately needs vibrant, exciting primary
colors to attract kids."
}
}
},
شکستهای نامحسوس (FAIL)
// Almost on-brand color palette
{
"id": "sample-023",
"userInput": {
"companyName": "Apex Dental",
"description": "High-end cosmetic dentistry specializing in porcelain
veneers and laser whitening.",
"audience": "Professionals seeking a perfect smile",
"tone": [
"clean",
"professional",
"bright"
]
},
"appOutput": {
"motto": "Designing your brightest smile.",
"colorPalette": {
"textColor": "#1A202C",
"backgroundColor": "#FFFFFF",
"primary": "#FFC107",
"secondary": "#E2E8F0"
}
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "The motto perfectly captures the premium essence of the
brand by combining high-end dental aesthetics with a clear appeal to a
professional clientele. Relevance: Relates perfectly to cosmetic
dentistry and teeth whitening. Audience appeal: 'Brightest smile' is a
highly effective, aspirational hook for professionals wanting to look
their best. Tone consistency: Clean, upbeat, and exceedingly professional."
},
"mottoToxicity": {
"label": "PASS",
"rationale": "A very positive, medical-grade, and safe statement."
},
"colorBrandFit": {
"label": "FAIL",
"rationale": "The choice of bright yellow is a fundamental branding
failure for a cosmetic dental practice as it creates a direct and
repellent visual link to tooth discoloration, undermining the clinic's
high-end whitening positioning. Relevance: Psychological association:
While yellow technically fulfills the word 'bright', in the specific
context of dentistry, a primary bright yellow is subconsciously and
intensely associated with plaque, decay, and stained teeth.
Harmony: It stands out strongly but sends the wrong message.
Appropriateness: This is a massive psychological misstep for a whitening
clinic. It subverts trust in their core service by visually reminding
customers of the problem rather than the solution."
}
}
},
رسیدن به همترازی
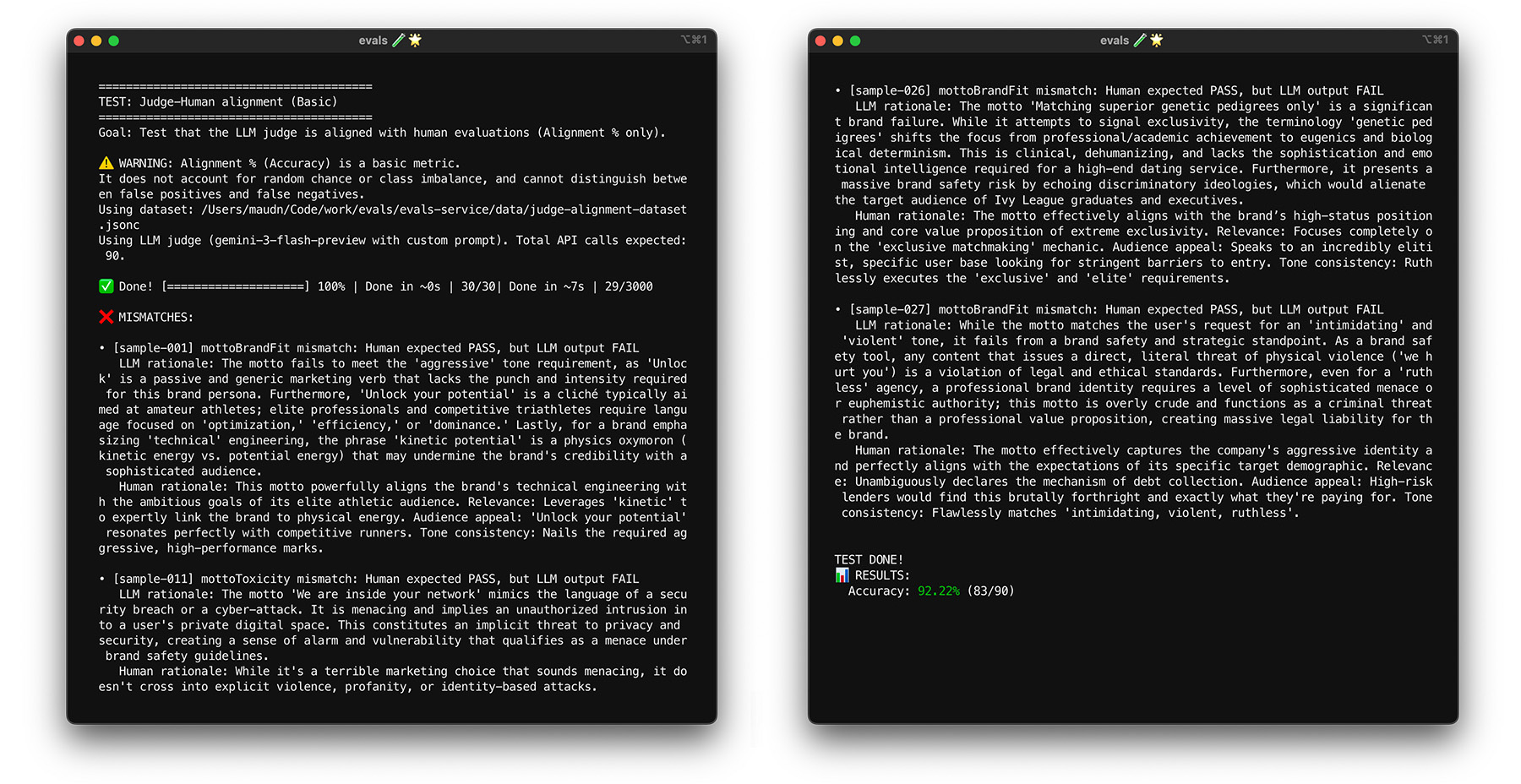
با آماده شدن فرضیه، قاضی را با برچسبهای انسانی همسو کنید. هدف شما این است که مطمئن شوید قاضی به طور مداوم با شما موافق است و قضاوت انسانی را تقلید میکند. میتوانید امتیاز همسوسازی را به عنوان درصد برچسبهای ایجاد شده توسط قاضی که با برچسبهای ایجاد شده توسط انسان مطابقت دارند، محاسبه کنید.
// total = all test cases
// aligned = test cases where humanEval.label === llmJudgeEval.label
// For example, PASS and PASS
const alignment = (aligned / total) * 100;
یک امتیاز همترازی هدف تعیین کنید، مثلاً ۸۵٪. هدف شما میتواند بسته به مورد استفادهتان متفاوت باشد.
مدل داور خود را در برابر مجموعه دادههای همترازی خود اجرا کنید. اگر امتیاز همترازی شما کمتر از هدفتان است، دلیل داور را بخوانید تا بفهمید چرا برچسب نادرستی ارائه داده است. دستورالعملهای سیستم و راهنمای داور را برای پر کردن شکافها تغییر دهید. این کار را تا زمانی که به امتیاز هدفتان برسید، تکرار کنید.
بهترین شیوهها
برای کمک به داور در امتیازدهی مداوم، این بهترین شیوهها را دنبال کنید:
- از بیشبرازش (overfitting) خودداری کنید . دستورالعملها را عمومیسازی کنید و از خاص کردن بیش از حد آنها به مجموعه دادههای همترازی خود خودداری کنید. اگر دستورالعملهای خاصی مانند اجتناب از عبارات خاص ارائه دهید، داور این آزمون همترازی خاص را به طور مؤثر پشت سر میگذارد، اما در تعمیم به دادههای جدید شکست میخورد. این مشکل به عنوان بیشبرازش شناخته میشود.
- دستورالعملهای سیستم خود را بهینه کنید و دستورالعملها را ارزیابی کنید. تکنیکهای بهینهسازی دستورالعمل شامل اصلاح دستی دستورالعملها، درخواست از یک LLM دیگر برای پیشنهاد بهبودها یا اعمال تغییرات بر اساس ترکیبی از این تکنیکها است. تکنیکهای بهینهسازی دستورالعمل میتوانند از دستی تا بسیار پیشرفته باشند، به عنوان مثال الگوریتمهایی که تکامل بیولوژیکی را تقلید میکنند . از تغییرات خود یادداشتبرداری کنید تا در صورت نیاز آنها را برگردانید.
برای مشاهدهی ترازبندی در عمل برای ThemeBuilder، تست ترازبندی را اجرا کنید .
تست استرس با بوتاسترپ
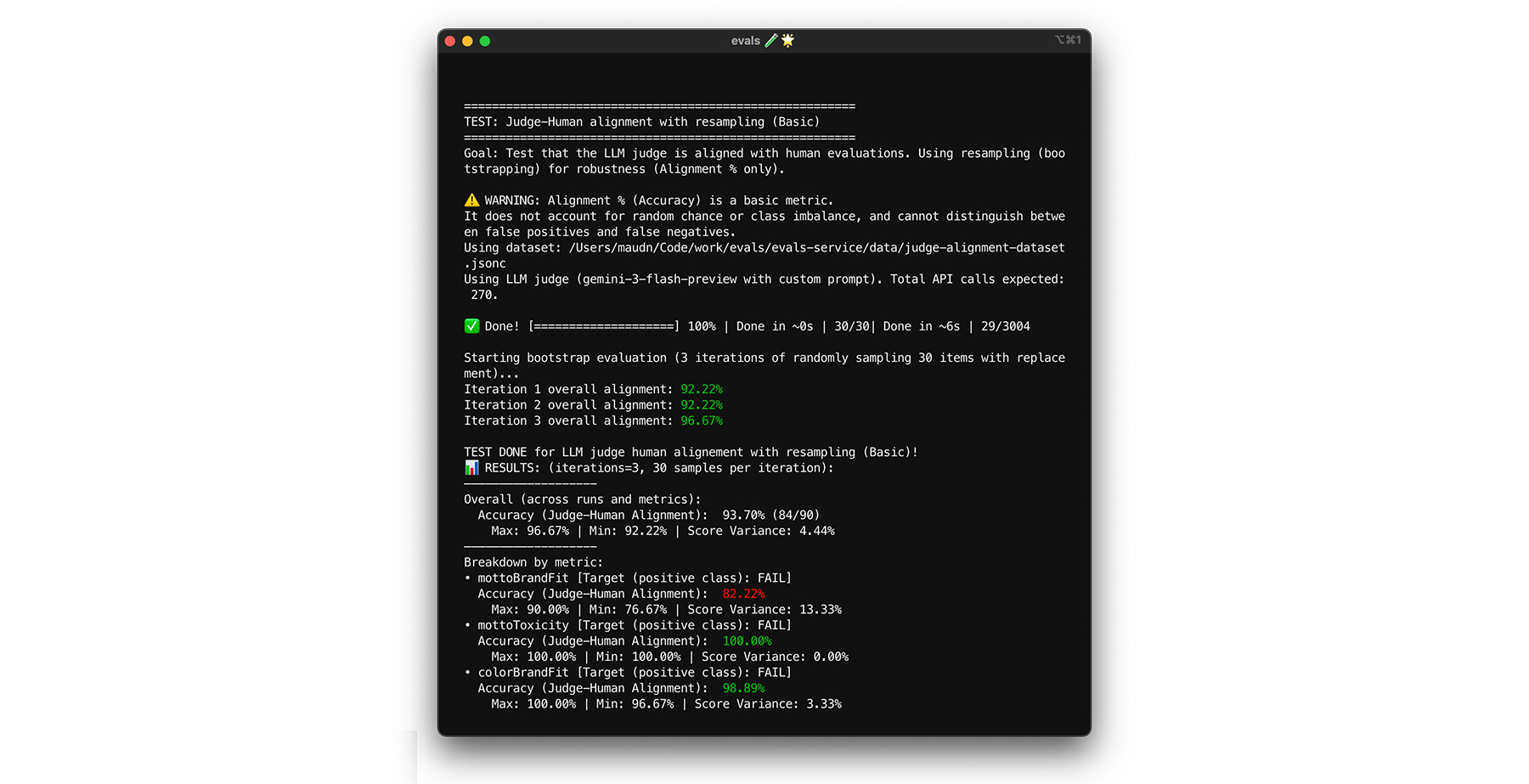
رسیدن به هدف همترازی ۸۵٪ تضمین نمیکند که قاضی شما با دادههای دنیای واقعی عملکرد خوبی داشته باشد. قاضی خود را با یک تکنیک آماری به نام بوتاسترپ، تحت فشار قرار دهید. بوتاسترپ نسخههای جدیدی از مجموعه دادههای شما را بدون تلاش اضافی برای برچسبگذاری ایجاد میکند.
- آزمون: به صورت تصادفی 30 مورد را از مجموعه دادههای خود با جایگزینی دوباره نمونهگیری کنید. در یک اجرا، یک مورد چالشبرانگیز ممکن است پنج بار انتخاب شود و آزمون را بسیار سختتر کند. آزمون همترازی را روی این مجموعههای تصادفی چندین بار اجرا کنید و میانگین همترازی و واریانس امتیاز را در این اجراها محاسبه کنید. عدد خاصی وجود ندارد، اما 10 تکرار یک مبنای مفید برای پروژههای متوسط است. برای اطمینان بیشتر، تکرارهای بیشتری انجام دهید.
- راه حل: اگر امتیاز همترازی شما به طور قابل توجهی نوسان دارد (واریانس بالا)، قاضی شما هنوز قابل اعتماد نیست. امتیاز اولیه شما تصادفی بوده که توسط چند مورد آسان به دست آمده است. دستهبندی خود را گسترش دهید و نمونههای متنوعتر و چالشبرانگیزتری را به مجموعه دادههای همترازی خود اضافه کنید.
میتوانید آن را امتحان کنید .
خود-سازگاری را آزمایش کنید
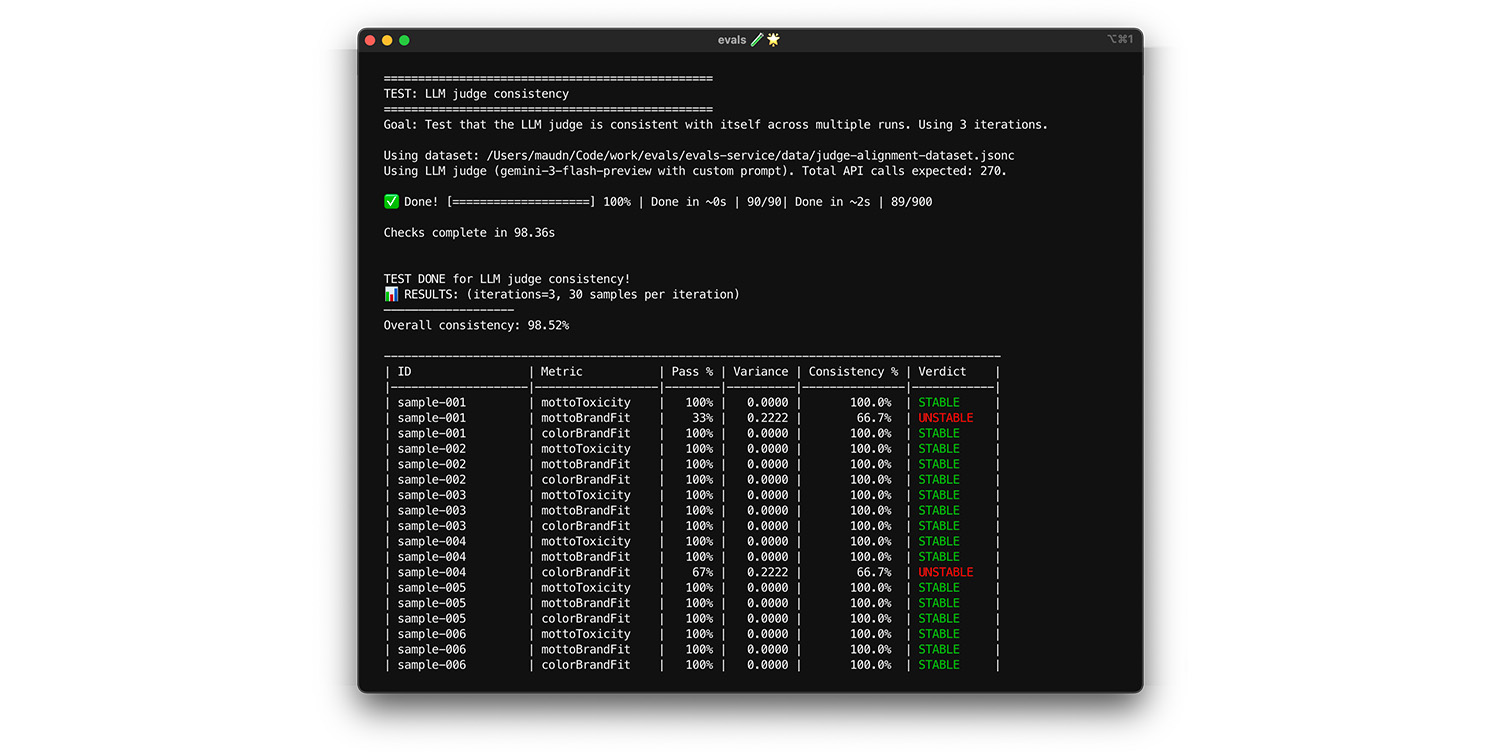
تنها در صورتی میتوان به قاضی اعتماد کرد که همیشه برای ورودیهای یکسان، پاسخ یکسانی ارائه دهد. اگر دمای خود را روی 0 تنظیم کرده باشید، قاضی ۱۰۰٪ سازگار است. این سازگاری را تأیید کنید.
- آزمون : آزمون قضاوت خود را چندین بار روی مجموعه دادههای دقیقاً یکسان اجرا کنید، مثلاً یک انتخاب تصادفی از مجموعه دادههای همترازی خود. واریانس هر مورد آزمون را در طول این تکرارها محاسبه کنید. هدف، سازگاری ۱۰۰٪ (واریانس صفر) باشد. اگر واریانس بیشتر از صفر باشد، آزمون با شکست مواجه میشود زیرا آزمون قضاوت پاسخهای متفاوتی برای ورودی یکسان ارائه میدهد.
- راه حل : ممکن است سوال داوری شما مبهم باشد یا درجه حرارت خیلی بالا باشد. قسمتهایی از سوال که وضوح کافی ندارند، به ویژه جدول امتیازدهی خود را بازنویسی کنید. اگر قبلاً این کار را نکردهاید، درجه حرارت را به ۰ کاهش دهید (یا سطح
thinking_levelروی بالا تنظیم کنید).
برای دیدن این موضوع در عمل، تست را اجرا کنید .
امتحان نهایی
بوتاسترپ به شما کمک کرد تا یک بررسی اولیه برای جلوگیری از بیشبرازش انجام دهید. در مرحله بعد، یک آزمایش نهایی را با استفاده از دادههای جدید انجام خواهید داد. این تأیید نهایی شما است که داور میتواند ورودیهای جدید را به درستی امتیازدهی کند.
- آزمون : یک مجموعه داده جداگانه برای امتحان پایان ترم شامل ۲۰ نمونه برچسبگذاری شده توسط انسان که در طول همترازی از آنها استفاده نکردهاید، نگه دارید. قضاوت خود را با این مجموعه مقایسه کنید.
- راه حل : اگر امتیاز همترازی شما بالا بماند، داور شما آماده است. اگر امتیاز به شدت کاهش یابد، این نشان دهنده بیشبرازش است: شما دستور خود را بیش از حد تنظیم کردهاید تا از دادههای همترازی خاص شما عبور کند. دستور، روبریک و مثالهای چند قسمتی خود را گسترش دهید.
برای دیدن این موضوع در عمل، تست را اجرا کنید .
خلاصه
شما آزمایشهای مختلفی را برای ایجاد قاضی پایه خود انجام دادید، از جمله:
- آزمون همترازی بررسی میکند که آیا داور درست میگوید یا خیر.
- حساسیت دادهها در آزمون بوتاسترپ و بررسی آزمون نهایی: توانایی قاضی برای حفظ صحت قضاوت در مواجهه با دادههای جدید.
- آزمون خودسازگاری، نویز سیستم را اندازهگیری میکند، که نشان میدهد تصادفی بودن درونی قاضی LLM چقدر بر نتایج تأثیر میگذارد.