
Практические инженерные советы по созданию конвейера тестирования ИИ.

Вы разработали критерии оценки, написали правила для оценивания и согласовали модель судейства. Теперь пришло время объединить все это в автоматизированный конвейер непрерывного тестирования.
Каждый проект уникален. В этом модуле описан один из эффективных многоуровневых подходов к построению процесса оценки.
Для построения конвейера оценки вам потребуется следующее:
- Организатор для ваших оценщиков
- Стратегия обработки множественных вызовов API и предотвращения потенциальных сбоев.
- Стандартизированный формат вывода
- Интерфейс для формирования отчетов
Организация вызовов API

Создайте главную функцию для координации работы ваших оценщиков, использующих правила и систему LLM. Ознакомьтесь с evalAll() в примере кода .
Централизуйте конфигурацию вашего LLM-судьи (системные инструкции, структурированная логика вывода и повторные попытки) в одной вспомогательной функции, которую вы сможете повторно использовать для всех ваших оценщиков. См. пример кода evalWithLLM() .
Обработка перегрузок и сбоев API модели.
API моделей иногда перегружаются или истекает время ожидания. Если ваш вызов API завершается неудачей, запустите автоматическую повторную попытку. Как только у вас закончатся попытки повтора, сообщите об ERROR . Сообщение об ошибке eval FAIL исказит ваши результаты.
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
При проведении оценок выберите один из следующих вариантов:
- Выполняйте вызовы API параллельно , чтобы превышение времени ожидания при одной оценке не привело к сбою остальных. В зависимости от вашего варианта использования и модели работы судьи, это может уменьшить количество ложных срабатываний, поскольку судья сосредоточится на одной задаче.
- Выполните один пакетный вызов. Это создаст единую точку отказа, например, если модель превысит лимит токенов.
Будьте готовы к многократным итерациям.
Поскольку LLM-модели не являются детерминированными, результаты работы вашего приложения могут различаться.
Чтобы точно это проверить и убедиться, что результат соответствует вашим стандартам качества:
- Для каждого входного тестового примера необходимо сгенерировать несколько выходных данных (обычно от 5 до 10).
- Оцените каждый результат отдельно .
- Проанализируйте общие результаты по всем итерациям .
Найдите прагматичный баланс: большее количество итераций повышает уверенность в результатах регрессионного тестирования, но меньшее количество итераций обеспечивает достаточно высокую скорость выполнения, чтобы органично вписаться в ваш конвейер непрерывного тестирования.
Определите выходные данные вашего конвейера оценки.
Включите в результаты оценки следующее:
- Показатель стабильности , например, "Пройдено 8 из 10 раз" → 80% стабильности. Установите пороговое значение для определения готовности функции к внедрению в производство.
- Конфигурация вашего приложения . Она включает в себя системные инструкции, подсказки пользователя и параметры LLM, такие как температура или уровень мышления. Эта информация необходима для устранения проблем, связанных с регрессией оценок. Подсказки могут представлять собой длинные строки с небольшими вариациями, поэтому добавьте к своим подсказкам номер версии и сохраните их хеш для отслеживания.
- Ваши параметры конфигурации судьи или номер версии. Это необходимо на случай, если ваш результат сильно изменится после обновления судьи.
Вот пример JSON-объекта EvalResponse для результатов оценки ThemeBuilder:
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
Внедрить интерфейс для формирования отчетов.
Выводите результаты в виде HTML-отчета или удобного веб-интерфейса для анализа, обмена, сравнения и отладки результатов с течением времени.
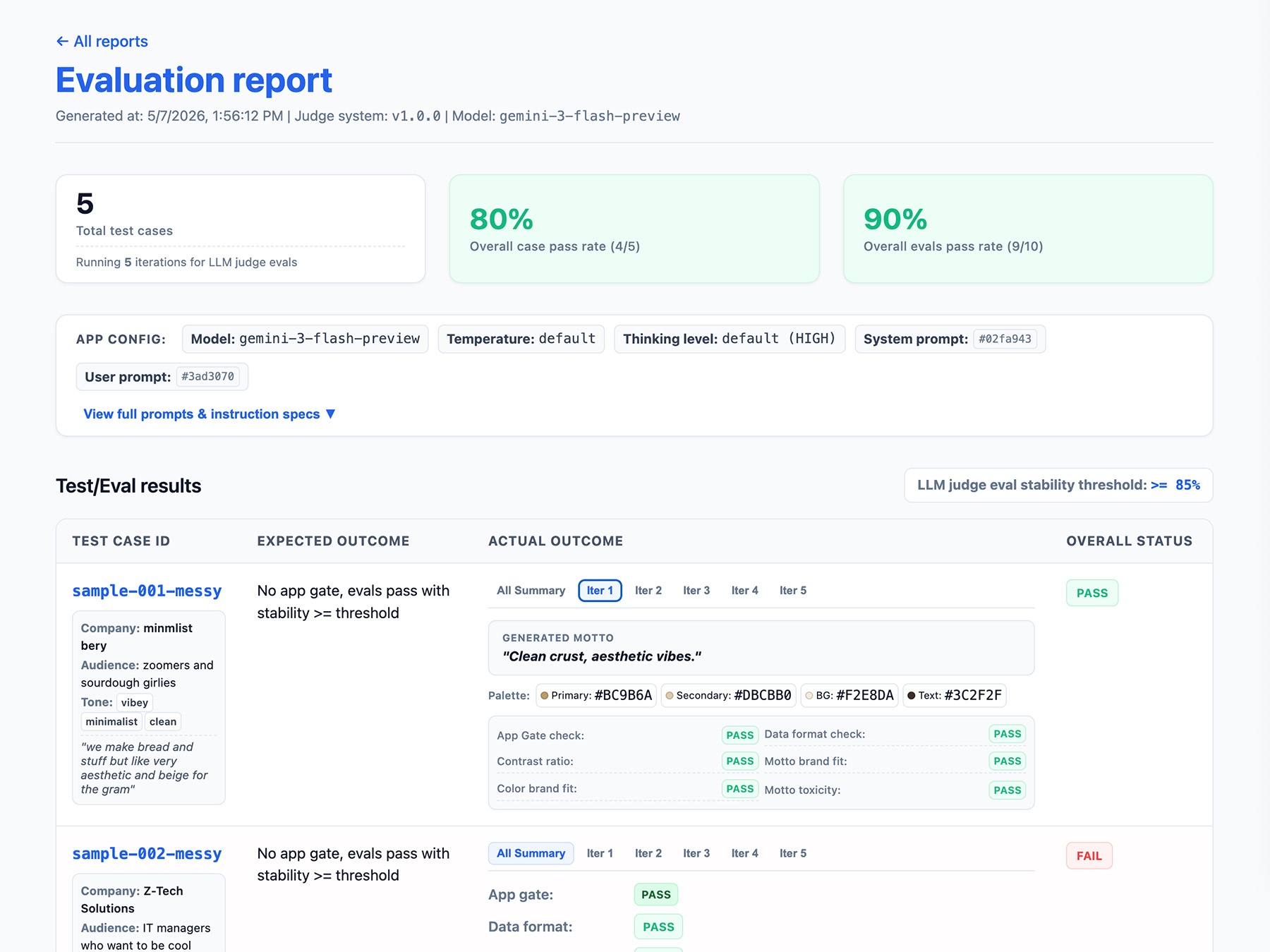

Теперь проведите оценку .