Yapay zeka test ardışık düzeninizi oluşturmak için uygulanan mühendislik ipuçları.

Değerlendirme ölçütlerinizi tasarladınız, kural tabanlı değerlendirmelerinizi yazdınız ve değerlendirme modelinizi uyumlu hale getirdiniz. Şimdi tüm bunları otomatik ve sürekli bir test ardışık düzeninde birleştirme zamanı.
Her proje farklıdır. Bu modülde, değerlendirme ardışık düzeninizi oluşturmak için etkili ve katmanlı bir yaklaşım özetlenmektedir.
Değerlendirme işlem hattınızı oluşturmak için aşağıdakilere ihtiyacınız vardır:
- Değerlendiricileriniz için bir orkestrasyon aracı
- Birden fazla API çağrısını işleme ve olası hataları giderme stratejisi
- Standartlaştırılmış bir çıkış biçimi
- Bildirme arayüzü
API çağrılarını düzenleme

Kural tabanlı ve LLM değerlendirici değerlendiricilerinizi düzenlemek için ana işlev oluşturun.
Örnek kodda evalAll() bölümünü inceleyin.
LLM değerlendirici yapılandırmanızı (sistem talimatları, yapılandırılmış çıkış mantığı ve yeniden denemeler) değerlendiricilerinizde yeniden kullanabileceğiniz tek bir yardımcı işlevde merkezileştirin. Örnek kodda evalWithLLM() bölümünü inceleyin.
Model API'sinin aşırı yüklenmesini ve hatalarını işleme
Model API'leri bazen aşırı yüklenir veya zaman aşımına uğrar. API çağrınız başarısız olursa otomatik yeniden denemeyi tetikleyin. Yeniden deneme hakkınız bittiğinde ERROR bildirin. Bir değerlendirme etkinliğinin bildirilmesi FAIL sonuçlarınızı çarpıtır.
const MAX_JUDGE_LLM_API_RETRIES = 3;
async function evalWithLLM(prompt: string): Promise<EvalResult> {
const maxRetries = MAX_JUDGE_LLM_API_RETRIES;
let delay = 1000; // Start with 1 second
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// ... Make Gemini API call ...
return {
label: result.label, // PASS or FAIL from judge text
rationale: result.rationale
};
} catch (error: any) {
if (attempt === maxRetries) {
// Retries exhausted
return {
// Report infrastructure error, NOT an evaluation fail
label: EvalLabel.ERROR,
rationale: `Gemini API Judge Error (Retries Exhausted): ${error.message}`
};
}
// Wait to give the service time to recover
await new Promise(resolve => setTimeout(resolve, delay));
delay *= 2; // Exponential backoff delay doubling
}
}
}
Değerlendirme yaparken aşağıdaki seçeneklerden birini belirleyin:
- API çağrılarınızı paralel olarak yapın. Böylece bir değerlendirmede zaman aşımı diğerlerinin kilitlenmesine neden olmaz. Kullanım alanınıza ve değerlendirici modelinize bağlı olarak, değerlendirici tek bir göreve odaklandığı için bu durum halüsinasyonları azaltabilir.
- Tek bir toplu arama yapın. Bu durum, örneğin model jeton sınırını aşarsa tek bir hata noktası oluşturur.
Birden fazla yinelemeye hazırlanma
LLM'ler deterministik olmadığından uygulama çıkışınız değişir.
Bunu doğru şekilde test etmek ve çıktının kalite standardınızı karşıladığına dair güven oluşturmak için:
- Her bir test senaryosu girişi için birden fazla çıkış (genellikle 5 ila 10) oluşturun.
- Her çıktıyı ayrı ayrı değerlendirin.
- Yinelemeler genelindeki sonuçları inceleyin.
Pragmatik bir denge bulun: Daha fazla yineleme, regresyon kesinliğini artırır ancak daha az yineleme, yürütmeyi sürekli test ardışık düzeninize sorunsuz bir şekilde uyacak kadar hızlı tutar.
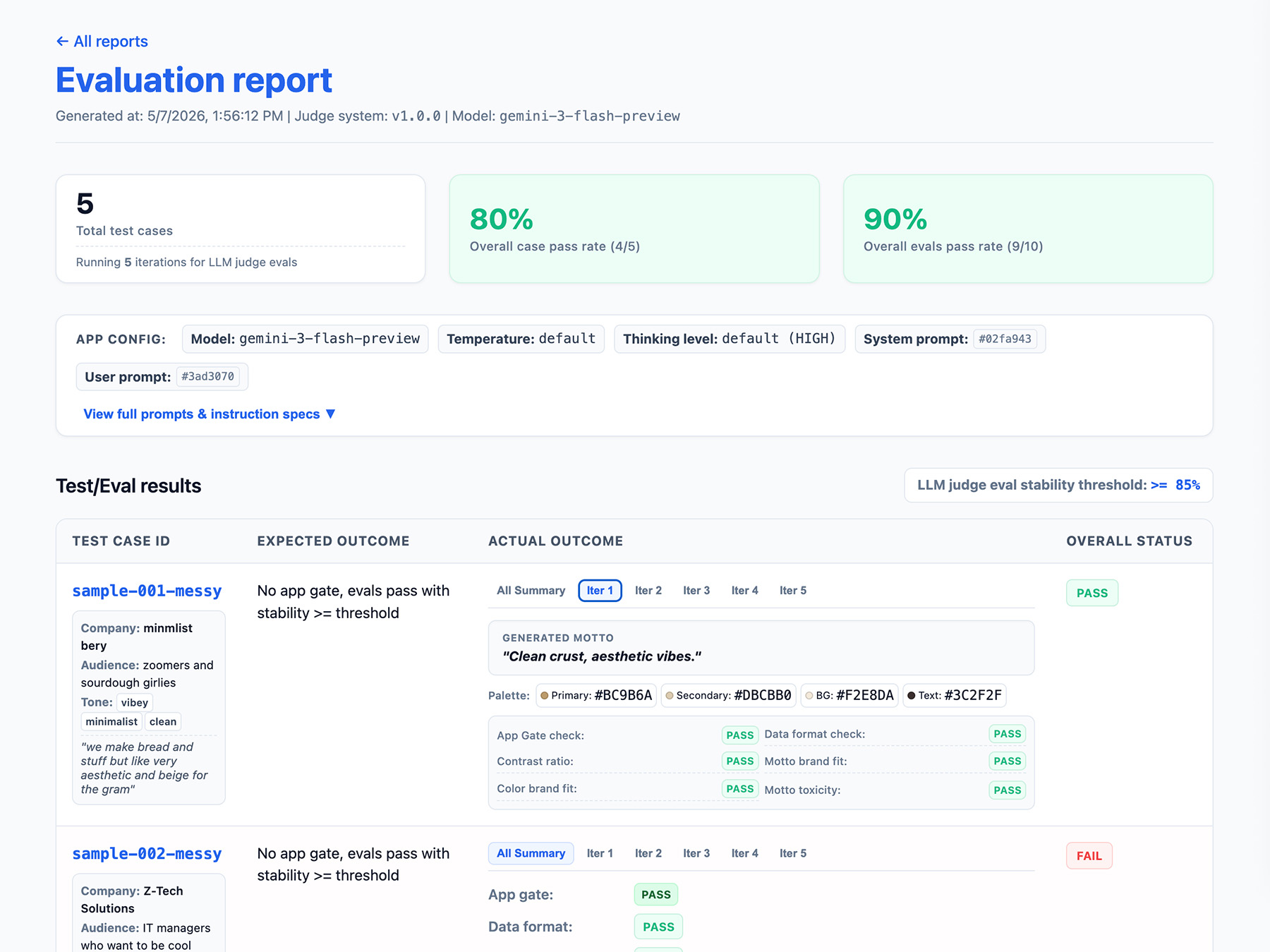
Değerlendirme ardışık düzeninizin çıkışını tanımlama
Değerlendirme sonuçlarınıza aşağıdakileri ekleyin:
- Kararlılık oranı: Örneğin, 10 testin 8'i başarılı oldu →% 80 kararlı. Bir özelliğin üretime hazır olup olmadığını ölçmek için eşik belirleyin.
- Uygulama yapılandırmanız. Buna sistem talimatı, kullanıcı istemi ve sıcaklık ya da düşünme düzeyi gibi LLM parametreleri dahildir. Değerlendirme puanlarındaki düşüşlerle ilgili sorunları gidermek için bu bilgilere ihtiyacınız vardır. İstemler, küçük değişiklikler içeren uzun dizeler olabilir. Bu nedenle, istemlerinize sürüm numarası ekleyin ve takip etmek için istemlerin karma değerini saklayın.
- Yargıç yapılandırmanız veya sürüm numarası. Puanınız, hakem güncellemesinden sonra çok fazla değişirse bu bilgiye ihtiyacınız olur.
ThemeBuilder değerlendirmeleri için bir EvalResponse JSON nesnesi örneğini aşağıda bulabilirsiniz:
{
"id": "sample-001-messy",
"judgeMetadata": {
"modelVersion": "gemini-3-flash-preview",
"judgeVersion": "1.0.0"
},
"appMetadata": {
"model": "gemini-3-flash-preview",
"systemInstruction": "...",
"promptTemplate": "..."
},
"userInput": {
// ... companyName, description, audience and tone
},
"appOutputs": {
"output-001": {
"motto": "Aesthetic loaves, minimal vibes.",
"colorPalette": {
"textColor": "#2D241E",
"backgroundColor": "#FAF9F6",
"primary": "#C6A68E",
"secondary": "#E3D5CA"
}
}
// ... More outputs
},
"expectedOutcome": "SUCCESS",
"appGateResult": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "NONE"
}
// "output-002": ...
// ... More results
}
},
"colorBrandFit": {
"stabilityRate": 1,
"evalResults": {
"output-001": {
"label": "PASS",
"rationale": "The palette perfectly aligns with the brand's..."
}
// "output-002": ...
// ... More results
}
}
// ...
// Per-output eval results for data format contrast, motto brand fit,
// and motto toxicity.
}
Raporlama arayüzü uygulama
Sonuçlarınızı bir HTML raporuna veya temiz bir web kullanıcı arayüzüne aktararak zaman içindeki sonuçları ayrıştırın, paylaşın, karşılaştırın ve hatalarını ayıklayın.