

Gepubliceerd: 1 oktober 2025
Before any of the built-in AI APIs can be used, the underlying model and any customizations (such as fine-tunings) must be downloaded, the compressed data must be extracted, and all of this must be loaded into memory. It's best practice to alert the user to the time required to perform these downloads.
De volgende voorbeelden maken gebruik van de Prompt API , maar de concepten kunnen worden toegepast op alle andere ingebouwde AI API's .
Volg en deel de voortgang van het downloaden.
Elke ingebouwde AI API gebruikt de functie create() om een sessie te starten. De functie create() heeft een monitor waarmee je de downloadvoortgang kunt bekijken en met de gebruiker kunt delen.
Hoewel ingebouwde AI-API's zijn ontworpen voor client-side AI , waarbij data in de browser en op het apparaat van de gebruiker wordt verwerkt, bieden sommige applicaties de mogelijkheid om data op een server te verwerken. Hoe je de gebruiker informeert over de voortgang van het downloaden van het model, hangt af van de vraag: moet de dataverwerking uitsluitend lokaal plaatsvinden of niet? In dat geval is je applicatie volledig client-side. Zo niet, dan zou je applicatie een hybride implementatie kunnen gebruiken.
Alleen aan de clientzijde
In some scenarios, client-side data processing is required. For example, a healthcare application that allows for patients to ask questions about their personal information likely wants that information to remain private to the user's device. The user has to wait until the model and all customizations are downloaded and ready before they can use any data processing features.
In dit geval, als het model nog niet beschikbaar is, moet u de gebruiker informatie over de downloadvoortgang tonen.
<style>
progress[hidden] ~ label {
display: none;
}
</style>
<button type="button">Create LanguageModel session</button>
<progress hidden id="progress" value="0"></progress>
<label for="progress">Model download progress</label>
Now to make this functional, a bit of JavaScript is required. The code first resets the progress interface to the initial state (progress hidden and zero), checks if the API is supported at all, and then checks the API's availability :
- De API is
'unavailable': Uw applicatie kan niet aan de clientzijde op dit apparaat worden gebruikt. Breng de gebruiker op de hoogte dat de functie niet beschikbaar is. - De API is
'available': De API kan direct worden gebruikt, het is niet nodig om de voortgangsinterface weer te geven. - The API is
'downloadable'or'downloading': The API can be used once the download is complete. Show a progress indicator and update it whenever thedownloadprogressevent fires. After the download, show the indeterminate state to signal to the user that the browser is getting the model extracted and loaded into memory.
const createButton = document.querySelector('.create');
const promptButton = document.querySelector('.prompt');
const progress = document.querySelector('progress');
const output = document.querySelector('output');
let sessionCreationTriggered = false;
let localSession = null;
const createSession = async (options = {}) => {
if (sessionCreationTriggered) {
return;
}
progress.hidden = true;
progress.value = 0;
try {
if (!('LanguageModel' in self)) {
throw new Error('LanguageModel is not supported.');
}
const availability = await LanguageModel.availability({
// ⚠️ Always pass the same options to the `availability()` function that
// you use in `prompt()` or `promptStreaming()`. This is critical to
// align model language and modality capabilities.
expectedInputs: [{ type: 'text', languages: ['en'] }],
expectedOutputs: [{ type: 'text', languages: ['en'] }],
});
if (availability === 'unavailable') {
throw new Error('LanguageModel is not available.');
}
let modelNewlyDownloaded = false;
if (availability !== 'available') {
modelNewlyDownloaded = true;
progress.hidden = false;
}
console.log(`LanguageModel is ${availability}.`);
sessionCreationTriggered = true;
const llmSession = await LanguageModel.create({
monitor(m) {
m.addEventListener('downloadprogress', (e) => {
progress.value = e.loaded;
if (modelNewlyDownloaded && e.loaded === 1) {
// The model was newly downloaded and needs to be extracted
// and loaded into memory, so show the undetermined state.
progress.removeAttribute('value');
}
});
},
...options,
});
sessionCreationTriggered = false;
return llmSession;
} catch (error) {
throw error;
} finally {
progress.hidden = true;
progress.value = 0;
}
};
createButton.addEventListener('click', async () => {
try {
localSession = await createSession({
expectedInputs: [{ type: 'text', languages: ['en'] }],
expectedOutputs: [{ type: 'text', languages: ['en'] }],
});
promptButton.disabled = false;
} catch (error) {
output.textContent = error.message;
}
});
promptButton.addEventListener('click', async () => {
output.innerHTML = '';
try {
const stream = localSession.promptStreaming('Write me a poem');
for await (const chunk of stream) {
output.append(chunk);
}
} catch (err) {
output.textContent = err.message;
}
});
If the user enters the app while the model is actively downloading to the browser, the progress interface indicates where the browser is in the download process based on the still missing data.
Client-side demo
Take a look at the demo that shows this flow in action. If the built-in AI API (in this example, the Prompt API) isn't available, the app can't be used. If the built-in AI model still needs to be downloaded, a progress indicator is shown to the user. You can see the source code on GitHub.
Hybride implementatie
If you prefer to use client-side AI, but can temporarily send data to the cloud, you can set up a hybrid implementation. This means users can experience features immediately, while in parallel downloading the local model. Once the model is downloaded, dynamically switch to the local session.
You can use any server-side implementation for hybrid, but it's probably best to stick with the same model family in both the cloud and locally to ensure you get comparable result quality. Getting started with the Gemini API and Web apps highlights the various approaches for the Gemini API.
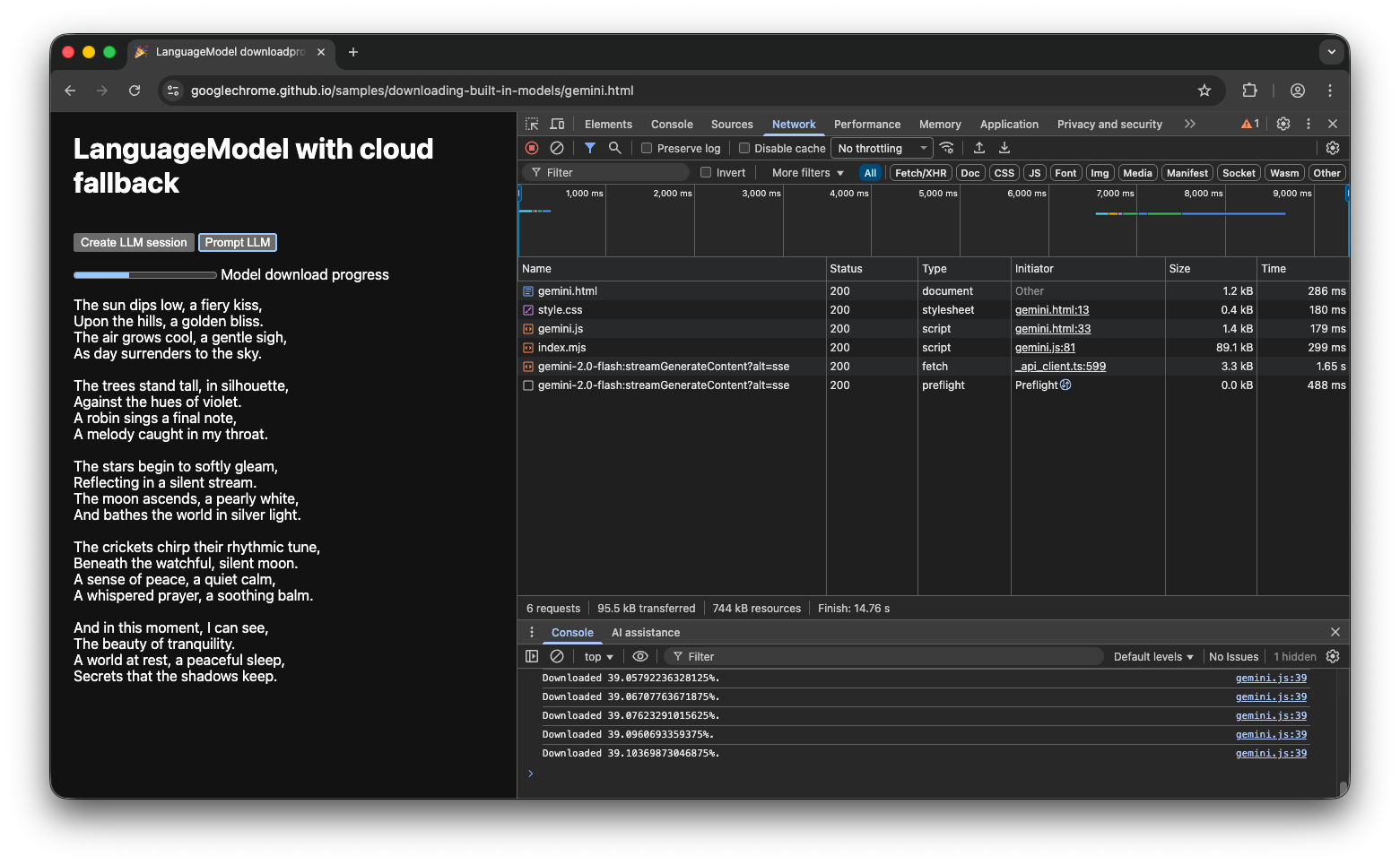
Hybride demonstratie
The demo shows this flow in action. If the built-in AI API isn't available, the demo falls back to the Gemini API in the cloud. If the built-in model still needs to be downloaded, a progress indicator is shown to the user and the app uses the Gemini API in the cloud until the model is downloaded. Take a look at the full source code on GitHub .
Conclusie
What category does your app fall into? Do you require 100% client-side processing or can you use a hybrid approach? After you've answered this question, the next step is to implement the model download strategy that works best for you.
Zorg ervoor dat uw gebruikers altijd weten wanneer en of ze uw app al aan de clientzijde kunnen gebruiken door de voortgang van het downloaden van modellen weer te geven, zoals beschreven in deze handleiding.
Remember that this isn't just a one-time challenge: if the browser purges the model due to storage pressure or when a new model version becomes available, the browser needs to download the model again. Whether you follow either the client-side or hybrid approach, you can be sure that you build the best possible experience for your users, and let the browser handle the rest.