


公開日: 2025 年 3 月 12 日、最終更新日: 2025 年 5 月 28 日
| 商品の解説 | ウェブ | 拡張機能 | Chrome のステータス | インテント |
|---|---|---|---|---|
| MDN | 表示 | 出荷インテント |
Summarizer API を使用すると、 さまざまな長さと形式で情報の要約を生成できます。Chrome の基盤モデルや、ブラウザに組み込まれた他の言語モデルと組み合わせて使用すると、長文や複雑なテキストを簡潔に説明できます。
クライアント側で実行すると、ローカルでデータを処理できるため、機密データを安全に保ち、大規模な可用性を実現できます。ただし、コンテキスト ウィンドウはサーバーサイド モデルよりもはるかに小さいため、非常に大きなドキュメントの要約は困難になる可能性があります。この問題を解決するには、要約の要約の手法を使用します。
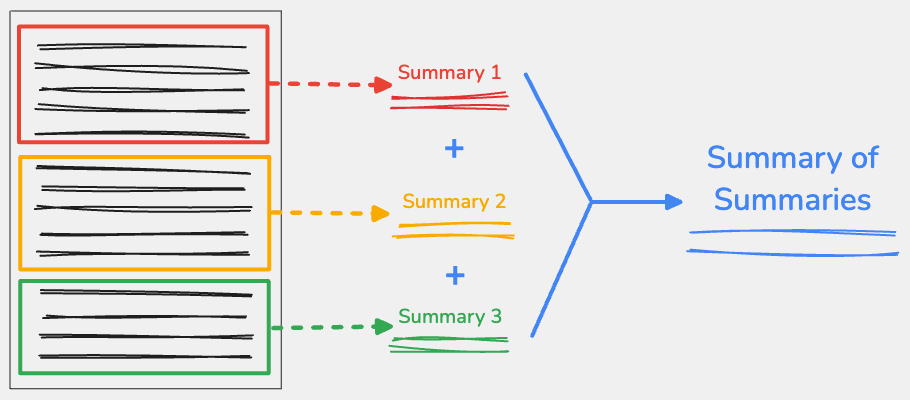
要約の要約とは
要約の要約の手法を使用するには、入力コンテンツを重要なポイントで分割し、各部分を個別に要約します。 各部分の出力を連結し、この連結されたテキストを 1 つの最終的な要約に要約できます。
コンテンツを慎重に分割する
さまざまな戦略によって LLM で異なる出力が生成される可能性があるため、長いテキストをどのように分割するかを検討することが重要です。 理想的には、記事の新しいセクションや段落など、トピックが変更されたときにテキストを分割する必要があります。単語や文の途中でテキストを分割することは避ける必要があります。つまり、文字数のみを分割のガイドラインとして使用することはできません。
これを行う方法はたくさんあります。次の例では、パフォーマンスと 出力品質のバランスが取れた Recursive Text SplitterをLangChain.jsから使用しました。これはほとんどのワークロードで機能します。
新しいインスタンスを作成する場合、次の 2 つの重要なパラメータがあります。
chunkSizeは、各分割で許可される最大文字数です。chunkOverlapは、連続する 2 つの分割間で重複する文字数です。これにより、各チャンクに前のチャンクのコンテキストの一部が含まれるようになります。
splitText() でテキストを分割して、各チャンクを含む文字列の配列を返します。
ほとんどの LLM では、コンテキスト ウィンドウは文字数ではなくトークン数で表されます。平均して、1 つのトークンには 4 文字が含まれます。この例では、chunkSize は 3, 000 文字で、これは約 750 トークンです。
トークンの可用性を確認する
入力に使用できるトークン数を確認するには、
measureInputUsage()
メソッドと inputQuota
プロパティを使用します。この場合、すべてのテキストを処理するためにサマライザーが実行される回数は不明なため、実装は無制限になります。
分割ごとに要約を生成する
コンテンツの分割方法を設定したら、Summarizer API を使用して各部分の要約を生成できます。
create() 関数を使用して、サマライザーのインスタンスを作成します。できるだけ多くの
コンテキストを保持するため、format パラメータを plain-text、type
を tldr、
を length に設定しました。long
次に、RecursiveCharacterTextSplitter で作成された分割ごとに要約を生成し、結果を新しい文字列に連結します。
各部分の要約を明確に識別できるように、各要約を改行で区切りました。
この改行は、このループを 1 回だけ実行する場合は問題ありませんが、最終的な要約のトークン値に各要約がどのように追加されるかを判断するのに役立ちます。ほとんどの場合、このソリューションは中程度の長さのコンテンツと長いコンテンツで機能します。
要約の要約を再帰的に行う
テキストの量が非常に多い場合、連結された要約の長さが使用可能なコンテキスト ウィンドウよりも大きくなり、要約が失敗する可能性があります。この問題を解決するには、要約を再帰的に要約します。
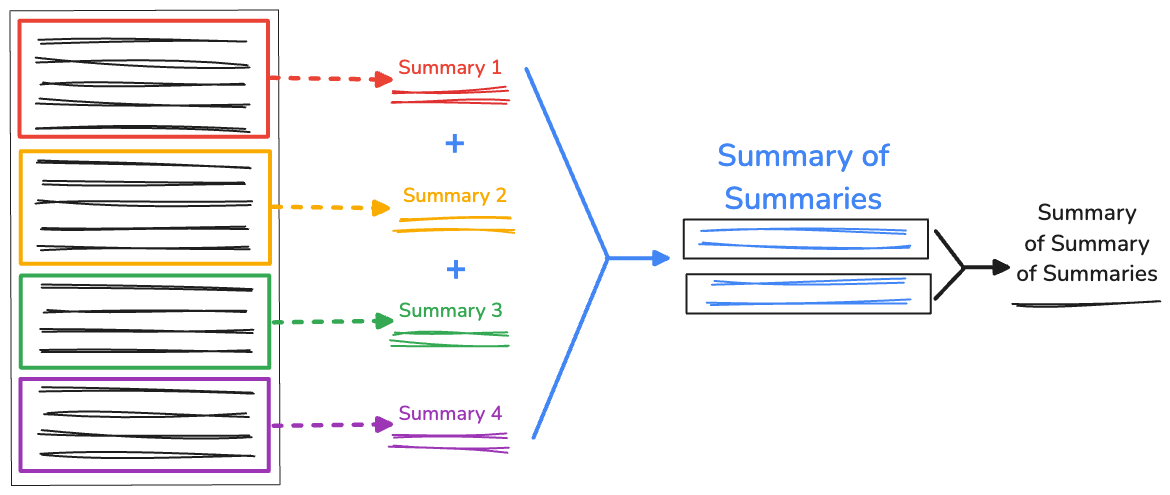
RecursiveCharacterTextSplitter で生成された最初の分割は引き続き収集されます。次に、recursiveSummarizer() 関数で、連結された分割の文字数に基づいて要約プロセスをループします。要約の文字数が 3000 を超える場合は、fullSummaries に連結します。上限に達していない場合、要約は partialSummaries として保存されます。
すべての要約が生成されると、最終的な部分的な要約が完全な要約に追加されます。fullSummaries に要約が 1 つしかない場合は、追加の再帰は必要ありません。この関数は最終的な要約を返します。複数の要約が存在する場合、関数は繰り返され、部分的な要約の要約が続行されます。
このソリューションは、17,560 語を含む 110,030 文字の Internet Relay Chat(IRC)RFCでテストしました。Summarizer API は次の要約を提供しました。
Internet Relay Chat(IRC)は、テキスト メッセージを使用してオンラインでリアルタイムにコミュニケーションを行う方法です。チャンネルでチャットしたり、プライベート メッセージを送信したり、コマンドを使用してチャットを制御したり、サーバーとやり取りしたりできます。インターネット上のチャット ルームのように、メッセージを入力するとすぐに他のユーザーのメッセージが表示されます。
これは非常に効果的です。また、309 文字しかありません。
制限事項
要約の要約の手法を使用すると、クライアントサイド モデルのコンテキスト ウィンドウ内で操作できます。クライアントサイド AI には多くの メリットがありますが、次のような問題が発生する可能性があります。
- 要約の精度が低い: 再帰を使用すると、要約プロセスの繰り返しが 無限になる可能性があり、各要約が元のテキストから遠くなります。つまり、モデルが生成する最終的な要約が浅すぎて役に立たない可能性があります。
- パフォーマンスの低下: 各要約の生成には時間がかかります。繰り返しになりますが、長いテキストでは要約の数が無限になる可能性があるため、このアプローチでは完了までに数分かかることがあります。
サマライザーのデモをご利用いただけます。完全なソースコードもご覧いただけます。
フィードバックをお寄せください
Summarizer API を使用して、入力 テキストの長さ、分割サイズ、重複の長さが異なる要約の要約の手法を試してください。
- Chrome の実装に関するフィードバックについては、 バグ報告 または機能リクエストを送信してください。
- MDN のドキュメントを読む
- Chrome AI チームと、要約プロセス やその他の組み込み AI に関する質問についてチャットする。