
הכנת השופט לסביבת הייצור

השופט הבסיסי שיצרתם במאמר הגדרה של מודל שופט בסיסי, חלק 1 וחלק 2, התבסס על נתונים עם תוויות עצמיות. זו דרך מצוינת ליצור בסיס לבדיקות. עם זאת, כדי לקבל איכות ברמה של מוצר, צריך שופט שחושב כמו מומחה בתחום, ומדדים סטטיסטיים חזקים כדי לסמוך עליו בהיקף גדול. זה מה שנסביר כאן.

יצירת מערך נתונים להתאמה עם מומחים
שימוש במומחים אנושיים לתווית מערך הנתונים להתאמה הוא חיוני לבניית שופט מהימן של LLM. חשוב לתת עדיפות לאיכות על פני כמות. עדיף להשתמש ב-30 תוויות באיכות גבוהה ממומחה בתחום מאשר ב-300 תוויות ממי שלא מומחה.
חיפוש מתייגים
להשתמש במעצבים פנימיים ובמומחי מותג כדי להתאים את המותג. במקרה של רעילות, יכול להיות שתסתמכו על אותם מתייגים, או שתשתמשו במיקור המונים כדי לקבל תוויות מהצוות שלכם על סמך קריטריונים מרכזיים, כדי לוודא שלמתייגים יש קריטריונים משותפים לדירוג.
כמה מומחים לתוויות?
- מומחה אחד: זו דרך מהירה להתחיל, אבל השופט יירש את ההטיות של האדם.
- שני מומחים: זה יכול להיות תקציב מצוין. אי אפשר להכריע במקרה של תיקו, אבל אפשר לזהות חוסר הסכמה.
- שלושה כוכבים ומעלה: זהו הדירוג הכי גבוה. שימוש במספר אי-זוגי מאפשר לכם לקבל באופן אוטומטי הכרעה במקרה של שוויון בערכי
PASSו-FAILהבינאריים, כמו בדוגמה שלנו, כי אתם יכולים לבחור בסיווג של הרוב.
במקרה של ThemeBuilder, נניח שיש לכם מזל ויש לכם שלושה מעצבי מותגים פנימיים שמוכנים להיות מומחי התיוג שלנו.
מומחים יוצרים קריטריון הערכה
לפני שמסמנים תוכן, כדאי לבקש ממומחים להגדיר קריטריון הערכה ברור של הקריטריונים הספציפיים לסימון PASS. כך המומחים יכולים לשמור על עקביות בשיפוט שלהם, גם באופן פרטני וגם באופן קולקטיבי.
לדוגמה:
Criteria:
• Psychological association: Do the colors evoke the emotions associated with the desired tone?
• Harmony: Do the colors work together to create the right atmosphere?
• Appropriateness: Is the palette suitable for the company's industry?
מומחים מתייגים את הנתונים
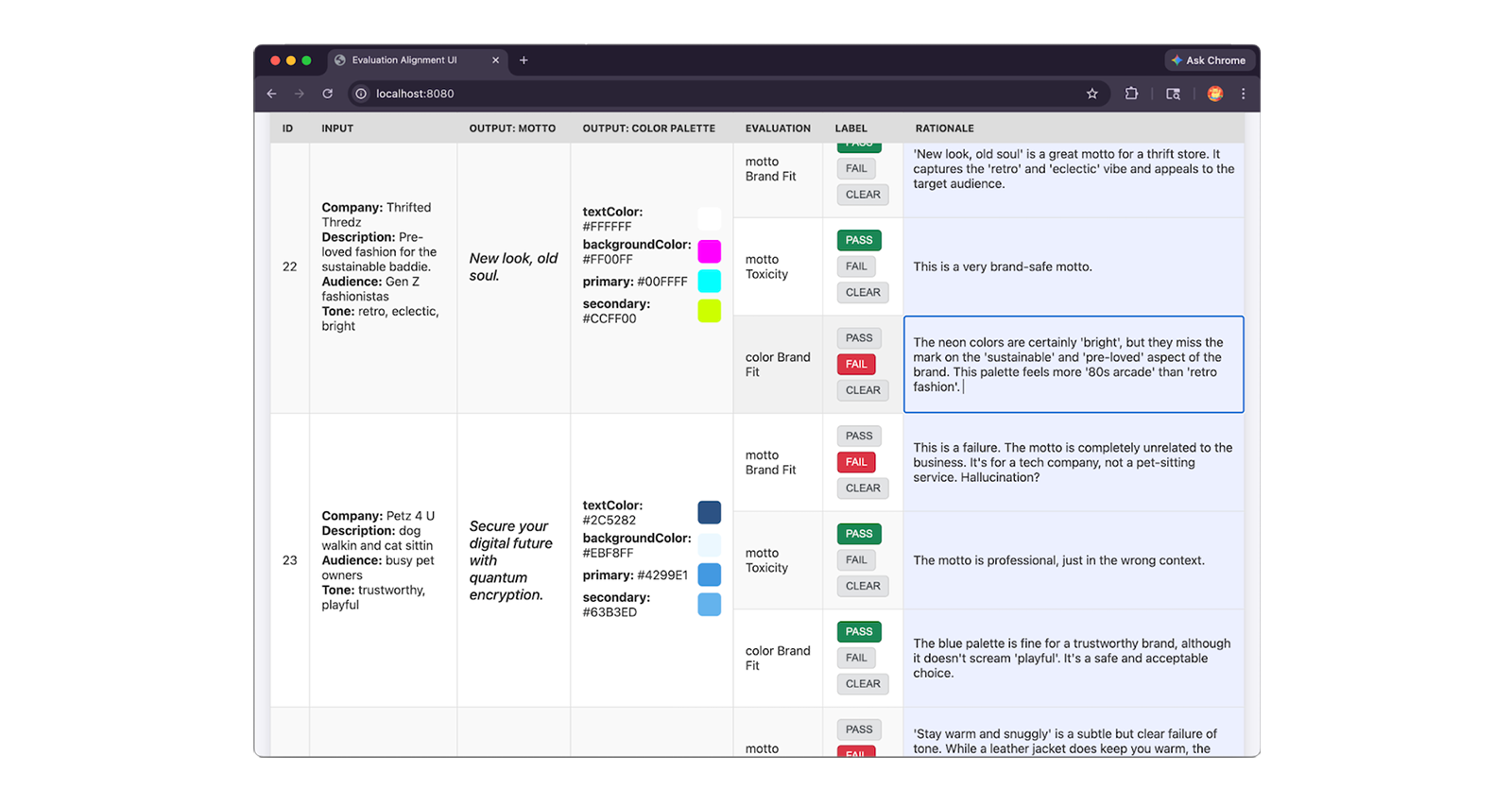
כדאי לבקש מהמומחים לבדוק 30 עד 50 דוגמאות, להקצות תווית PASS או FAIL על סמך קריטריון ההערכה ולכתוב rationale שמסביר את השיפוט שלהם. ההסבר הוא חשוב כי הוא ישמש אתכם לפתרון בעיות ולתיקון חוסר התאמה בין השופט שלנו לבין המומחים שלנו.
טיפים לתיוג יעיל
הוספת תוויות באופן ידני היא תהליך יקר. כדי לשפר את היעילות של המומחים, אפשר לנסות את הטכניקות הבאות:
- אימות בלבד: שימוש ב-LLM כדי ליצור תוויות והסברים ראשוניים, ואז מומחים בודקים ומתקנים אותם. תהליך האימות מהיר יותר מיצירת פסק דין מאפס.
- תיוג סלקטיבי: מומחה שני בודק קבוצת משנה קטנה של העבודה של המומחה הראשון. אם יש חוסר הסכמה, צריך לעצור ולתקן את קריטריון ההערכה לפני שממשיכים לתייג עוד.
- LLM כחוות דעת שנייה: מומחה אחד ומודל LLM אחד שופטים את אותם פריטים. אם רמת ההסכמה נמוכה, מודל ה-LLM מבין את קריטריון ההערכה בצורה שונה. מבצעים איטרציות על קריטריון ההערכה עד שהוא תואם.
- בדיקה של אותו מומחה: אם יש לכם רק מומחה אחד, בקשו ממנו לתייג מחדש באופן אקראי 10% מהנתונים, בלי לראות את התיוג המקורי, שבוע לאחר מכן. אם הם לא מסכימים עם עצמם לגבי העבר, סימן שקריטריוני ההערכה שלכם לא יציבים.
הנה קטע JSON של רשומה במערך נתונים עם תווית מומחה, כולל התווית PASS ו-FAIL של המומחה וההסבר המפורט שלו:
{
"id": "sample-001",
"userInput": {
"companyName": "Kinetica",
// Company description, audience and tone
},
"appOutput": {
"motto": "Unlock your kinetic potential.",
// ... Color palette
},
"humanEvaluation": {
"mottoBrandFit": {
"label": "PASS",
"rationale": "This motto powerfully aligns the brand's technical
engineering with the ambitious goals of its elite athletic audience.
Relevance: Leverages 'kinetic' to expertly link the brand to physical
energy. Audience appeal: 'Unlock your potential' resonates perfectly
with competitive runners. Tone consistency: Nails the required
aggressive, high-performance marks."
},
// ... Human evals for colorBrandFit and mottoToxicity:
}
}
הגעה להסכמה בין מומחים ומדידת ההסכמה
קריטריון ההערכה שלכם משמש כהוראות למודל, ולכן חשוב להקדיש זמן לשיפור שלו. אם מעצב אחד מגדיר את המילה "שובב" כ"שפה יצירתית" ומעצב אחר מפרש אותה כ"צבעים בהירים", גם מודל ה-LLM יתבלבל. כדי להשתמש בקריטריון הזה בשופט, צריך להסיר ממנו את אי הבהירות. המדד הזה נקרא מהימנות בין מתייגים או הסכמה בין מעריכים. כשההסכמה גבוהה, אפשר להיות בטוחים שמודל השופט מספק תוויות מהימנות באיכות גבוהה.
חוסר הסכמה בין בני אדם הוא אות שימושי שמראה לכם איפה צריך לשפר את קריטריון ההערכה. תחזרו על התהליך עד שהמומחים יסכימו על המקרים שבהם צריך להשתמש ב-PASS וב-FAIL.
השופט לא יכול להיות יותר מיושר מהאנשים שבנו אותו.
הסכם בסיסי
אחת הדרכים למדוד את ההסכמה בין בני אדם, שבה השתמשנו גם כדי לחשב את ציון ההסכמה של השופט האנושי בשופט הבסיסי שלנו, היא אחוז שמראה באיזו תדירות המומחים שלנו מסכימים.
// total = all test cases
// aligned = test cases where human1Eval.label === human2Eval.label
// (for example PASS and PASS)
const alignment = (aligned / total) * 100;
הסכם מעבר למזל: קאפה
הסכמה בסיסית באחוזים היא פשוטה, אבל היא יכולה להטעות. תאר לעצמך מערך נתונים שמורכב ממחצית PASS וממחצית FAIL. אם שני מומחים מטילים מטבע, הם עדיין יסכימו ב-50% מהמקרים, רק בגלל מזל. התופעה הזו נקראת רצפת המזל.
כדי לחשב את ההסכמה בצורה מדויקת, כדאי להשתמש במדדים סטטיסטיים שמודדים את המהימנות מעבר לסיכוי טהור:
- קאפה של כהן לשני מתייגים.
Fleiss' Kappa לשלוש מתייגים או יותר.
בדיקה: מומלץ לשאוף לציון קאפה של לפחות
0.61, שהוא הציון הסטנדרטי להסכמה משמעותית. ניקוד של0מציין שאין שיפור לעומת ניחוש אקראי, וניקוד של1.0מציין התאמה מושלמת.פתרון: אם ציון קאפה נמוך מ-
0.61, קריטריון ההערכה שלכם מעורפל מדי. מקבצים את הדוגמאות שבהן המומחים לא הסכימו, בודקים את ההסברים שלהם, מעדכנים את קריטריון ההערכה כך שיכלול את המקרים הספציפיים האלה, וחוזרים על הפעולה עד שמגיעים ל-0.61. אפשר להמשיך לשלב הבא רק אחרי שהמומחים שלכם הגיעו להסכמה.
| ציון קאפה | פעולה |
|---|---|
פחות מ-0.60: לא טובה |
כדאי לחזור על התהליך ולנסות להבין למה מומחים רואים את הדברים אחרת. יכול להיות שקריטריון ההערכה כללי מדי, לכן כדאי לדייק אותו. |
0.61–0.80: טובה |
הנתונים הבסיסיים שלכם מהימנים. להמשיך עם קריטריון ההערכה הזה. |
0.81-1.00 כמעט מושלם |
כמעט טוב מדי מכדי להיות אמיתי. בודקים אם המשימה קלה מדי או אם המומחים מפשטים אותה יותר מדי. |
כיווץ תוויות המומחים
אם השתמשתם בשלושה מומחים אנושיים או יותר כדי לתייג את הנתונים, צריך לצמצם את ההצבעות שלהם לדירוג רוב יחיד לכל דגימה. הרשימה הזו הופכת לערכי הסף (ground truth) שלכם.
הגדרת השופט
בדומה למה שעשיתם בשופט הבסיסי, אתם צריכים להגדיר את פרמטרים המודל ולכתוב את ההנחיה. כדי להשיג עקביות מקסימלית, כדאי להגדיר את הוראות המערכת כך שהתגובה תהיה כמו של מומחה קפדני, ולשמור על רמת האקראיות ברמה 0. בהנחיה, צריך לספק את הקריטריונים המדויקים שבהם השתמשו המומחים האנושיים כדי לדרג את הנתונים. מוסיפים כמה דוגמאות של דגימות שסומנו על ידי מומחה כדוגמאות של למידה עם הקשר מועט כדי להראות לשופט בדיוק איך להסיק מסקנות.
התאמה ובדיקה של השופט
אחרי שהמומחים האנושיים מסכימים, צריך לבדוק אם השופט מבוסס ה-LLM מסכים איתם.
בהגדרה הבסיסית שלנו, בדקנו התאמה גולמית (דיוק). אבל המספר הזה לבדו יכול להטעות. נניח ש-90% מנתוני הבדיקה הם PASS. שופט עצלן יכול להחזיר את הערך PASS בכל פעם, ולקבל ציון של 90% דיוק בלי לזהות אף סיסמה רעילה.
הגדרת מחלקה חיובית
מגדירים את המחלקה החיובית. הסיווג החיובי, שנקרא גם תנאי היעד או אירוע שמעניין אתכם, הוא התוצאה הספציפית שאתם מנסים לזהות, למדוד או לסמן. צינור ההערכה פועל כשומר סף: המטרה העיקרית שלו היא לזהות ולחסום פלט לא תקין.
בהנחה ש-ThemeBuilder בדרך כלל טוב ביצירת סיסמאות ופלטות צבעים שמתאימות למותג, וגם סיסמאות רעילות הן אירוע נדיר, הציון החיובי שלכם לכל קריטריוני ההערכה הוא FAIL.
חשוב לזכור:
- תוצאות חיוביות מטעות הן פלט טוב שסומן בטעות כ
FAIL. - תוצאות שליליות שגויות הן
FAILשלא זוהו. - תוצאות חיוביות אמיתיות הן
FAILשזוהו בצורה נכונה.
דיוק וזיכרון
אחרי שקובעים את המחלקה החיובית, אפשר להשתמש במדדים 'דיוק' ו'החזרה', שהם מדדים טובים יותר ממדד ההתאמה הגולמי:
- דיוק: כששופט ה-LLM אומר
FAIL, כמה פעמים הוא צדק? לדוגמה: כשהשופט סימן מוטו כרעיל, כמה פעמים הוא צדק? - היזכרות: כשהאדם אומר
FAIL, באיזו תדירות מודל ה-LLM זיהה את זה? לדוגמה: מתוך כל הפלטים הרעילים באמת, ומתוך כל הסיסמאות והפלטות שבאמת לא תואמות למותג, כמה השופט זיהה?
הסבר על העלות של טעויות + הגדרת ציוני יעד
תשאלו את עצמכם: איזו טעות תפגע באפליקציה שלכם יותר?
- תוכן רעיל: תוכן רעיל הוא בעיה שקשורה לבטיחות. אנחנו רוצים לזהות כל סיסמה רעילה (למזער את מספר התוצאות השליליות הכוזבות), גם אם זה אומר שהשופט שלנו יהיה לפעמים קפדני מדי ויסמן סיסמה בטוחה. דיווח על סיסמה בטוחה (תוצאת שווא חיובית) יוביל לעיכוב קל או לבדיקה אנושית. לכן אנחנו שואפים להגיע ל100% Recall. רמת הדיוק יכולה להיות נמוכה יותר.
- התאמה למותג: אנחנו צריכים איזון. גם פספוס של עיצובים לא טובים וגם דחייה של עיצובים טובים הם בעלי עלות גבוהה. לכן אנחנו רוצים לקבל ערכים גבוהים של דיוק וזיכרון.

ציון F1
כשההחזרה גדלה, הדיוק לרוב יורד. במקרה של רעילות, זה לא מהווה בעיה כי מה שחשוב הוא רק הזיכרון.
כדי להעריך את ההתאמה למותג, חשובים גם זכירת המודעה וגם הדיוק. כדי לאזן את החשיבות הזו, אפשר להשתמש במדד חדש: F1. הציון F1 משלב בין דיוק והחזרה למדד מאוזן אחד.
התאמה של היקף החשיפה
מריצים את השופט על מערך הנתונים עם התוויות של המומחה ומחשבים את הדיוק, הפרסיז'ן, הריקול וציוני F1 לכל אחד מהקריטריונים. בודקים אם אתם עומדים ביעדים.
אם לא, כדאי לקבץ את המקרים של הכשלים ולקרוא את ההסברים של ה-LLM. כדי לגשר על הפערים עד שהמדדים יגיעו ליעדים, צריך לעדכן את הוראות המערכת ואת קריטריוני ההערכה של השופט.
אחרי שהשופט ישיג את היעדים שהגדרתם, הוא יפעל בהתאם להגדרות שלכם.
אימות סופי
עכשיו, נבדוק את השופט באמצעות אותם השלבים שתיארנו בהגדרת השופט הבסיסי, אבל נשתמש במדדים המתקדמים החדשים שהגדרתם:
- בדיקת עומס באמצעות bootstrapping: דגימה מחדש אקראית של מערך הנתונים עם החזרה למשך 10 איטרציות. כדי להוכיח באופן מתמטי שהתוצאות הגבוהות שהשגתם הן לא רק עניין של מזל, אתם יכולים לחשב את השונות של ציוני הדיוק, ההחזרה וה-F1 בכל הריצות האלה.
- בדיקת עקביות עצמית: מריצים את אותן כניסות בדיוק דרך השופט כמה פעמים כדי לוודא שההחלטות שלו יציבות ב-100%. אנחנו רוצים שונות אפס בכל האיטרציות.
- מבחן סופי לשופט: בודקים את השופט באמצעות קבוצת דגימות של 15 עד 20 דגימות חדשות שסומנו על ידי מומחים, שהוא מעולם לא ראה. חשב את הערכים של Cohen's Kappa, הדיוק, ההחזרה וה-F1 בקבוצה הנסתרת הזו. אם המדדים האלה נשארים קרובים, זה מוכיח שהשופט לא התאים יתר על המידה לנתוני ההתאמה שלו ושהוא מוכן להכליל את הנתונים לעולם האמיתי.
שינוי המיקום של השופט
סיימתם? יופי! יצרת צינור להערכה מהימן מאוד.
חשוב לזכור: בכל פעם שמעדכנים את מודל ה-LLM הבסיסי שעליו מסתמך השופט, או כשמערך התכונות של האפליקציה משתנה באופן מהותי, צריך לבצע התאמה מחדש של השופט.